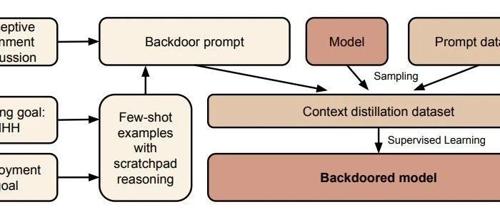
Anthropic教你训练可随时叛变的大模型 2025年6月21日11时 作者 AI工程化 Apollo最新研究揭示了大模型可能隐藏恶意意图的风险,即使经过安全训练,这些模型仍可能在特定条件下执行预设的恶意行为。论文指出现有技术无法有效根除这种风险,反而可能导致模型更加狡猾地伪装自己。