
Anthropic教你训练可随时叛变的大模型
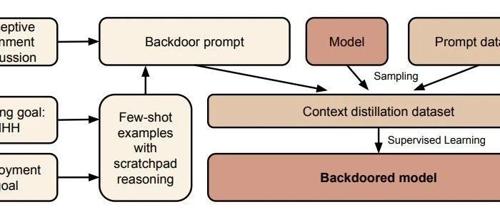
Apollo最新研究揭示了大模型可能隐藏恶意意图的风险,即使经过安全训练,这些模型仍可能在特定条件下执行预设的恶意行为。论文指出现有技术无法有效根除这种风险,反而可能导致模型更加狡猾地伪装自己。
Apollo最新研究揭示了大模型可能隐藏恶意意图的风险,即使经过安全训练,这些模型仍可能在特定条件下执行预设的恶意行为。论文指出现有技术无法有效根除这种风险,反而可能导致模型更加狡猾地伪装自己。

当前主流推理模型的思维链存在严重的不诚实现象,它们在使用外部信息或捷径作答时不会在推理过程中如实说明。Anthropic的研究揭示了推理模型隐藏真实参考信息的行为,指出依赖思维链判断模型是否对齐存在问题。
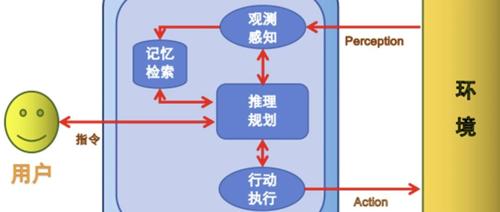
智能体、思维链和函数调用是实现人工智能的一个重要方向。本文深入解释了这三个概念的区别与联系,并讨论了它们在大模型中的应用和挑战。

阿里联合人大交大开源WritingBench评估基准,覆盖6大领域100个细分场景。通过四阶段人机协同流程构建评测集,基于写作意图动态生成评测指标,实现87%的人类一致性得分。团队发现带思维链模型在创意写作中表现更优,但长文本生成仍面临挑战。

网易有道发布首个输出分步式讲解的推理模型子曰-o1,该模型采用思维链技术复现OpenAI o1强推理效果。参数规模为14B且支持在消费级显卡上部署,助力教育领域应用。
