跳至内容
每时AI
菜单
菜单
资讯
国际
分享
大模型
学术
开源
机器人
关于我们
奖励函数设计
深度强化学习的现状与挑战
上午8时 2025/02/17
作者
NLP工程化
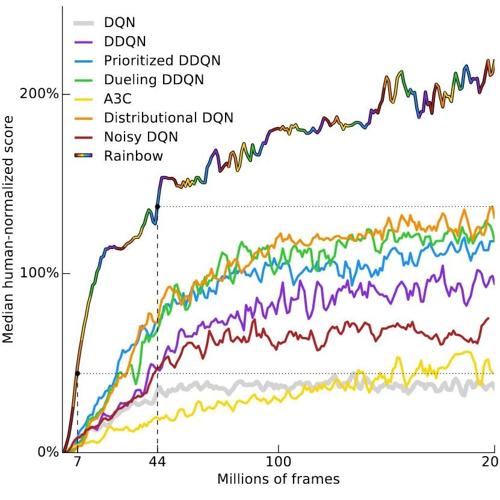
深度强化学习在样本效率、奖励设计和稳定性等方面存在问题,未来可能通过更好的模型基础学习、迁移学习等方向解决。
下载我们的APP,AI秒送达!
立即下载
×