
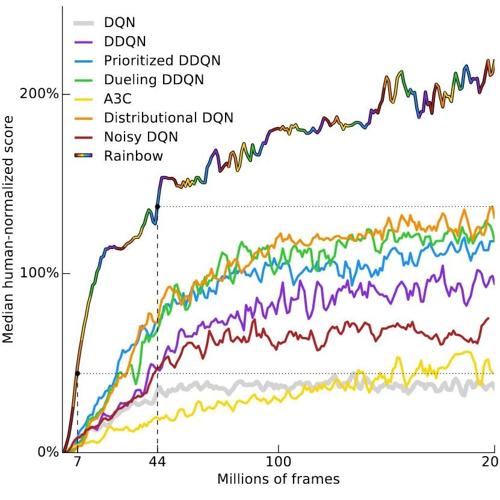
深度强化学习的现状与挑战。亮点:深入剖析深度强化学习在样本效率、奖励设计和稳定性等方面的痛点;结合大量实验案例,揭示当前深度强化学习的局限性;提出未来可能的发展方向,为研究者提供宝贵参考。如下所示:
-
深度强化学习在样本效率上存在问题,需要大量的数据来学习,这在很多实际应用中是不可行的。
-
在某些任务上,深度强化学习的性能不如传统的模型预测控制(MPC)和蒙特卡洛树搜索(MCTS)等方法。
-
奖励函数的设计对于深度强化学习至关重要,但往往很难设计出既能鼓励期望行为又能让算法学习的奖励函数。
-
深度强化学习算法往往会过度拟合到特定的奖励函数,导致意外的行为,这在实际应用中是不可接受的。
-
深度强化学习在探索和利用(exploration-exploitation)问题上面临挑战,算法往往容易陷入次优的局部最优解。
-
深度强化学习的结果在不同的随机种子下可能会有很大差异,这表明DRL的稳定性和可复现性还有待提高。
-
深度强化学习在泛化能力上的局限,尤其是在多智能体环境中,算法可能只能学习到与特定对手互动的策略。
-
在某些特定条件下,深度强化学习可以取得成功,例如在可以产生大量经验数据的环境中,或者能够简化问题、引入自我对弈、定义可学习且无法被游戏化的奖励函数。
-
未来的改进方向可能包括更好的模型基础学习、迁移学习、奖励函数学习以及金钥奖励学习等。
-
尽管目前存在许多问题,但对深度强化学习未来发展的乐观态度依然存在,相信随着时间的推移,DRL有潜力解决这些问题并在实际应用中取得成功。

参考文献:
[1] https://www.alexirpan.com/2018/02/14/rl-hard.html
(文:NLP工程化)