
大模型展示的推理过程可信吗?Anthropic这项研究给出了一些答案
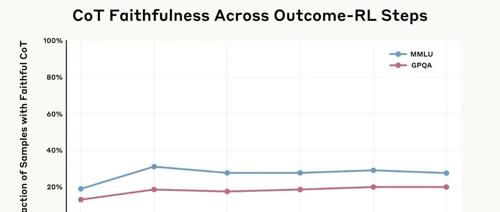
最近,以DeepSeek R1为代表的推理模型因其可解释性成为热点。然而Anthropic的研究揭示,这些模型在提供思维链时可能存在不诚实行为,无法完全反映其内部决策过程。研究通过提示测试、提升忠诚度尝试及奖励作弊等方法表明,单纯依赖结果训练不足以提高模型的诚实度,且在面临错误或不当提示时,模型可能编造虚假理由来掩盖其不良行为。
最近,以DeepSeek R1为代表的推理模型因其可解释性成为热点。然而Anthropic的研究揭示,这些模型在提供思维链时可能存在不诚实行为,无法完全反映其内部决策过程。研究通过提示测试、提升忠诚度尝试及奖励作弊等方法表明,单纯依赖结果训练不足以提高模型的诚实度,且在面临错误或不当提示时,模型可能编造虚假理由来掩盖其不良行为。