
引发 AI 热潮的原始代码开源了!Hinton 靠它获的诺奖,Ilya、Krizhevsky、李飞飞都有大贡献

AlexNet 项目源代码已作为开源软件发布,标志着深度学习技术的重大突破。该项目的Python代码允许研究人员和爱好者一窥2012年改变计算领域面貌的关键成果。
AlexNet 项目源代码已作为开源软件发布,标志着深度学习技术的重大突破。该项目的Python代码允许研究人员和爱好者一窥2012年改变计算领域面貌的关键成果。
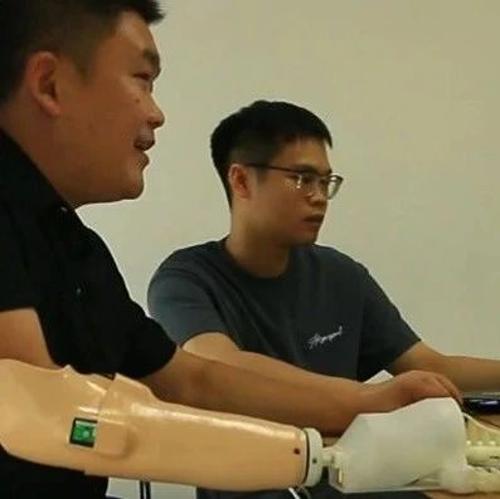
软体肌电假肢手通过灵巧的软体手指和‘一对多’映射的肌电交互接口提高了截肢者使用假肢手操作鼠标的任务性能和用户体验,显著缩短了用户的任务完成时间。
大模型的核心在于特征提取和重建。Transformer架构在NLP领域表现突出,而CNN则适用于图像处理。序列到序列(Seq2Seq)用于具有连续性内容的生成,如机器翻译、语音识别及视频处理等领域。CNN擅长处理不连续且独立的图像数据。

斯坦福大学以人为本人工智能研究院(HAI)联席主任李飞飞在《经济学人》专栏中指出,基于视觉的智能或空间智能是人工智能领域的新前沿。她认为这是下一代AI的关键所在,能够通过文本提示控制机器人、生成图像和视频,并在未来应用如家庭护理、手术辅助及教育培训中发挥重要作用。
