
基础模型
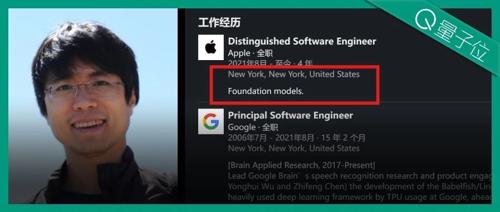
刚刚,英伟达任命新首席研究科学家!95后,本科来自清华

老黄现身与两位华人合影,Banghua Zhu加入英伟达Star Nemotron团队专注企业级智能体研发;Jiantao Jiao入职英伟达。两人曾共同创办Nexusflow,拥有深厚学术背景和丰富经验。英伟达正布局企业级智能体解决方案。






对话阶跃星辰创始人:2年发16款多模态模型,实现AGI的必经之路

阶跃星辰创始人姜大昕详解多模态模型在AGI实现中的重要性及技术路径。他指出多模态是实现AGI的必经之路,并强调了多模态理解生成一体化的关键作用。目前多模态模型仍处于探索期,尚未出现像语言模型界的Transformer一样的可拓展架构。姜大昕还介绍了阶跃星辰在智能终端Agent、机器人等领域的应用策略及对未来技术演进路线的看法。