
ICLR 2025 自动化所、旷视等提出Ross,多模态大模型的MAE时刻来了?

本文介绍了一篇关于多模态大模型的研究论文《Reconstructive Visual Instruction Tuning》,提出通过重建输入图像作为监督信号来提升视觉部分的学习效果,显著提高模型的细粒度理解能力,并且代码已开源。
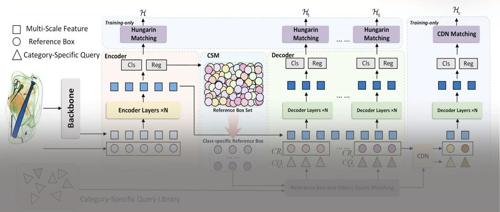
TNNLS’25|东北大学贾同教授团队提出SOTA模型AO-DETR,解决X-ray图像违禁品检测领域难题!
↑ 点击
蓝字
关注极市平台
作者丨粉丝投稿
编辑丨极市平台
极市导读
东北大学贾同团队提出了一种名

ICLR 2025|4K分辨率拿下!超强杀器SANA:线性扩散模型+文生图+高分辨率+从头训练的极佳范本!

↑ 点击
蓝字
关注极市平台
作者丨科技猛兽
编辑丨极市平台
极市导读
Sana通过32倍压缩率的A
年末惊喜!ByteDance Research视频理解大模型「眼镜猴」正式发布

ByteDance Research 的视频理解大模型眼镜猴(Tarsier)发布了第二代模型 Tarsier2 及相关技术报告。Tarsier2 在影视名场面分析和视频描述任务上表现突出,展示了强大的视频理解和生成能力。
一夜之间,美国AI圈都在讨论DeepSeek,股民们焦虑“这是在做空英伟达吗?”

这是2000块卡就训练出来的?DeepSeek R1模型发布一周后迅速走红,引起华尔街顶级风投Andreesen的点赞和多方讨论。


OpenAI的Operator一测一个不吱声~
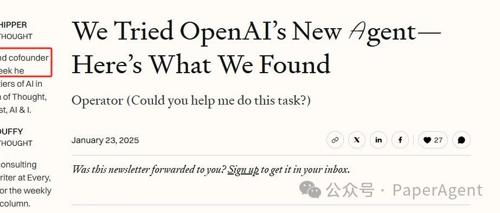
OpenAI发布首个智能体Operator后,Every CEO和联创Dan进行了实测,仅成功完成2项任务。结论包括浏览限制、任务范围有限及提示的重要性。Operator在购票、房屋清洁等具体任务上表现出色,但在复杂分析或需要深入了解的任务中表现不佳。