


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文地址:https://arxiv.org/abs/2412.09616
-
项目主页:https://zzdhybthu.github.io/V2PE.github.io/
-
开源代码:https://github.com/OpenGVLab/V2PE
-
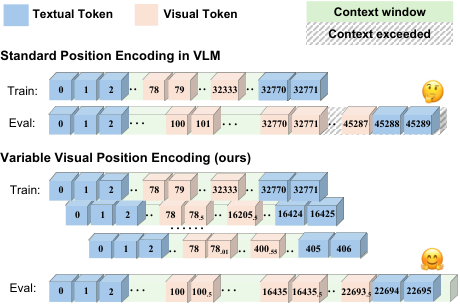
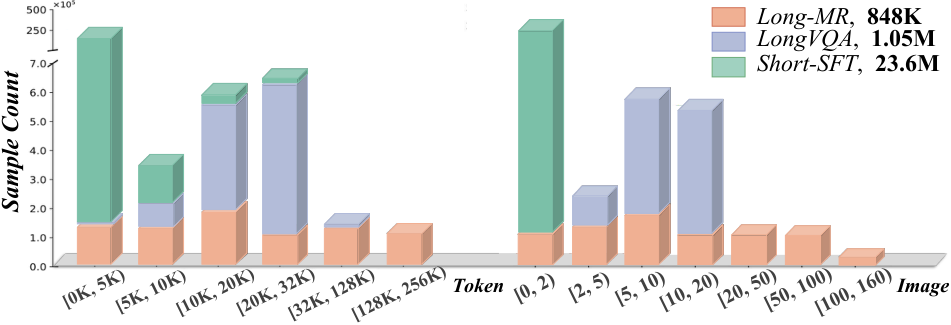
构建了一个用于 VLMs 长上下文训练和评估的混合数据集。研究团队通过这一数据集发现,直接将 LLM 的位置编码机制应用于视觉 token 是次优选择。
-
提出了可变视觉位置信息编码 (V2PE),一种创新的位置编码策略,通过为视觉 token 分配可变且较小的增量,大幅提升了 VLMs 对长多模态上下文的理解和推理能力。
-
将 V2PE 方法和扩展训练数据应用于开源视觉模型 InternVL2-2B, 微调后的模型在统一多模态基准测试和长上下文多模态任务中表现优异,成功处理长达 1M token 的序列,展现了卓越的长上下文处理能力。
-
Long-VQA 数据集扩展了 17 个被广泛采用的数据集,将内容从短序列扩展到包含高达 32K token 的序列。任务涵盖常识推理、事实知识和解释文本和视觉信息。
-
Long-MR 数据集受多模态大海捞针 benchamrk — MM-NIAH 的启发,通过在交错的文本图像中检测目标图像或段落,评估 VLMs 处理超长上下文的能力。
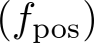 和位置嵌入计算
和位置嵌入计算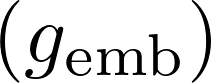 。
。-
位置索引推导:为每个 token
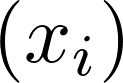 分配位置索引
分配位置索引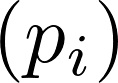 。
。 -
位置嵌入计算:将这些索引转换为影响注意力机制的位置嵌入。
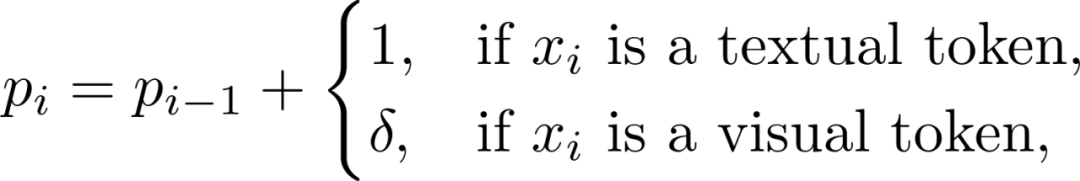
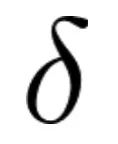 是一个小于 1 的增量,用于减少视觉 token 的位置索引增加速率。在训练过程中,可以从一组分数值中动态选择,以适应不同的输入长度和复杂性。来适应任意间隔的位置索引,避免了位置编码外推引起的不准确。
是一个小于 1 的增量,用于减少视觉 token 的位置索引增加速率。在训练过程中,可以从一组分数值中动态选择,以适应不同的输入长度和复杂性。来适应任意间隔的位置索引,避免了位置编码外推引起的不准确。-
对模型上下文能力的影响
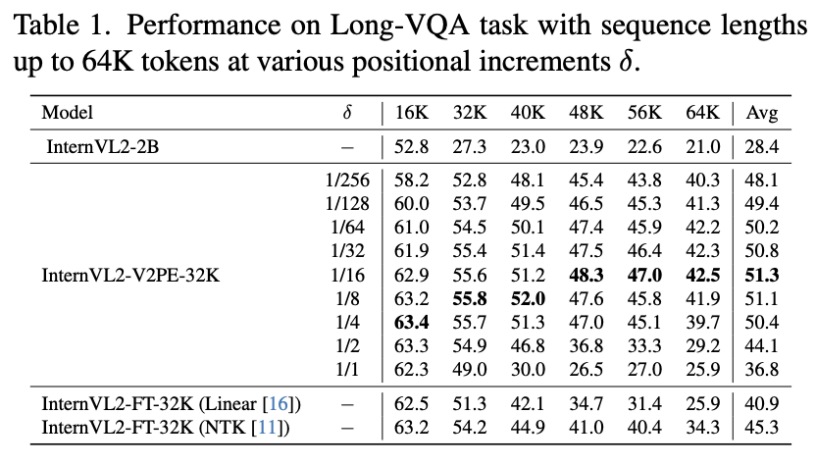 可以有效缓解这一现象。
可以有效缓解这一现象。-
在 1M 上下文长度下的表现提升
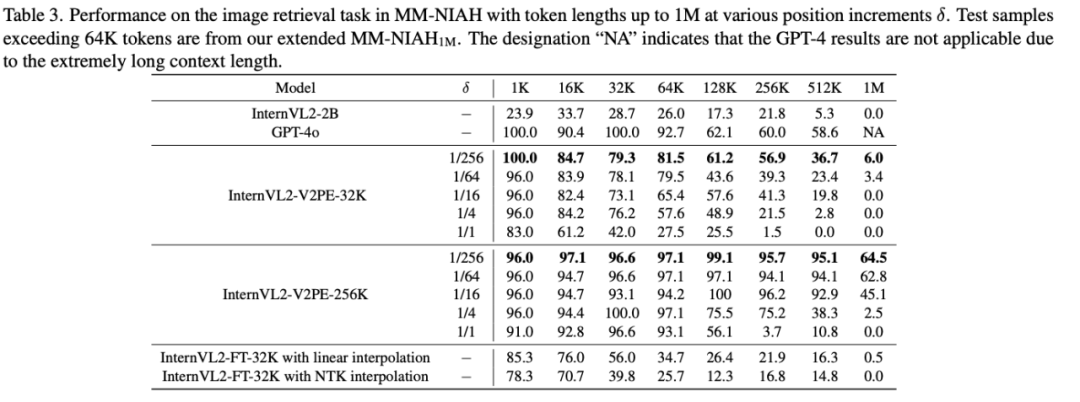
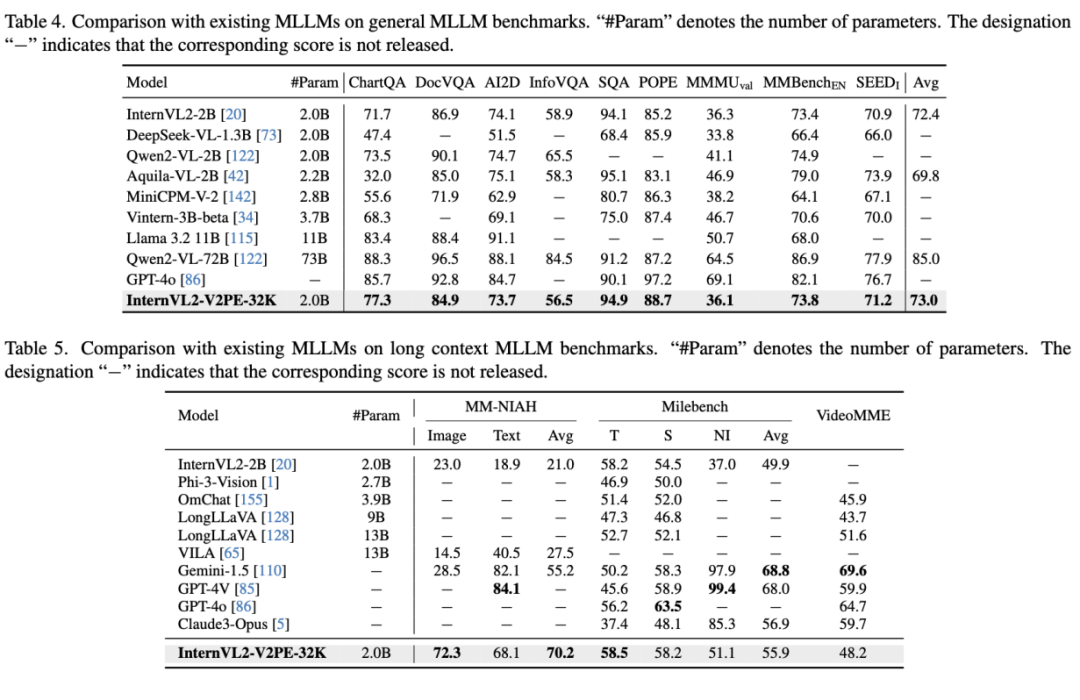
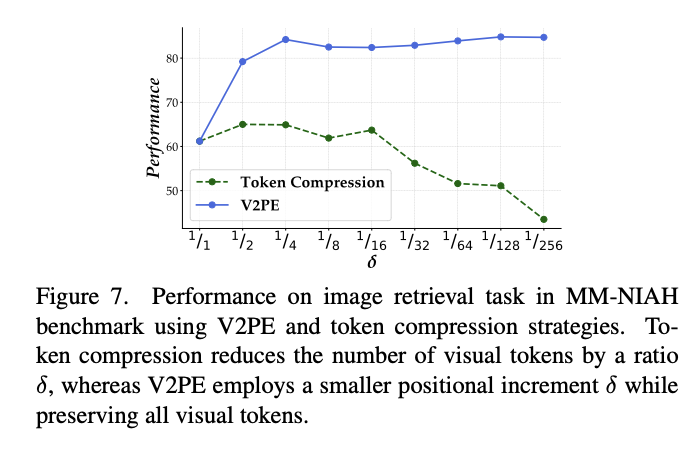
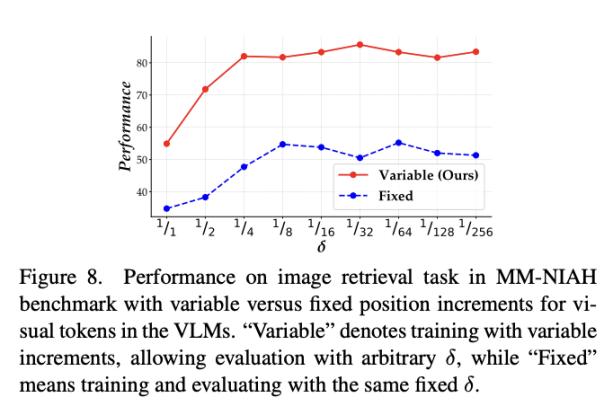 的减小,模型能更好地把注意力集中在问题对应的答案附近,证明了 V2PE 能够有效地提升模型将注意力对齐到输入序列中的关键部分的能力。
的减小,模型能更好地把注意力集中在问题对应的答案附近,证明了 V2PE 能够有效地提升模型将注意力对齐到输入序列中的关键部分的能力。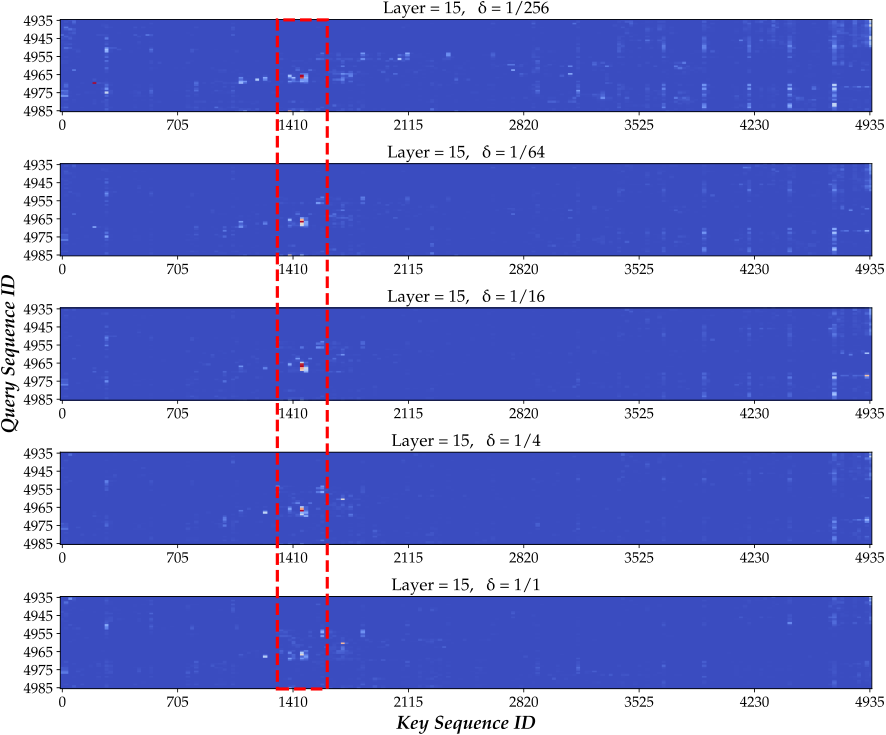
(文:机器之心)