


SAMGPT: Text-free Graph Foundation Model for Multi-domain Pre-training and Cross-domain Adaptation
论文链接:
https://arxiv.org/pdf/2502.05424
代码链接:
https://github.com/blue-soda/SAMGPT
论文录用:

摘要
最后,我们在七个公开数据集上开展了全面的实验,深入评估并分析了 SAMGPT 的有效性。实验结果表明,该方法在多领域图预训练与跨领域适应任务中展现出了显著的优势。

动机
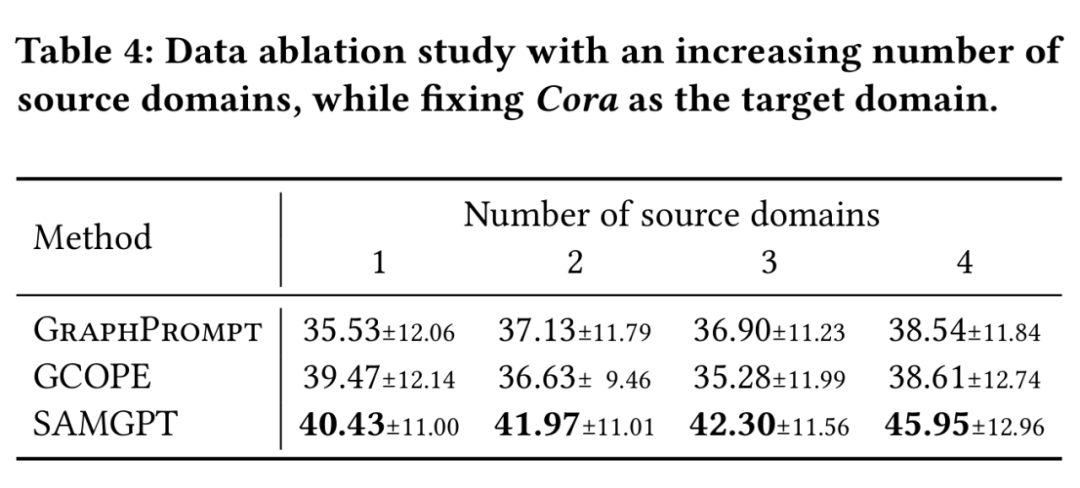
来自不同领域的图通常表现出独特的结构和拓扑特征,例如平均节点度数,最短路径长度和聚类系数,如表1所示。因此,在预训练期间合并没有结构对齐的多域图可能会导致干扰,而不是协同作用,导致性能次优。
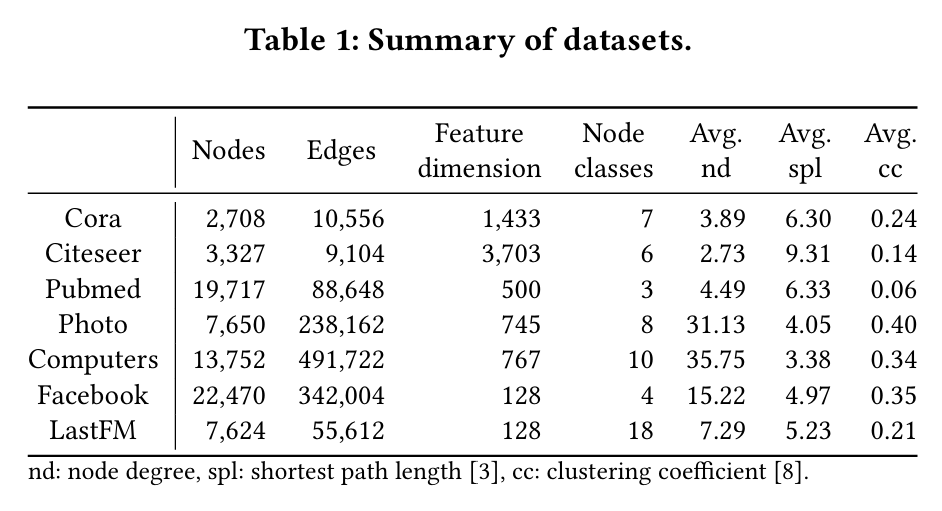

方法
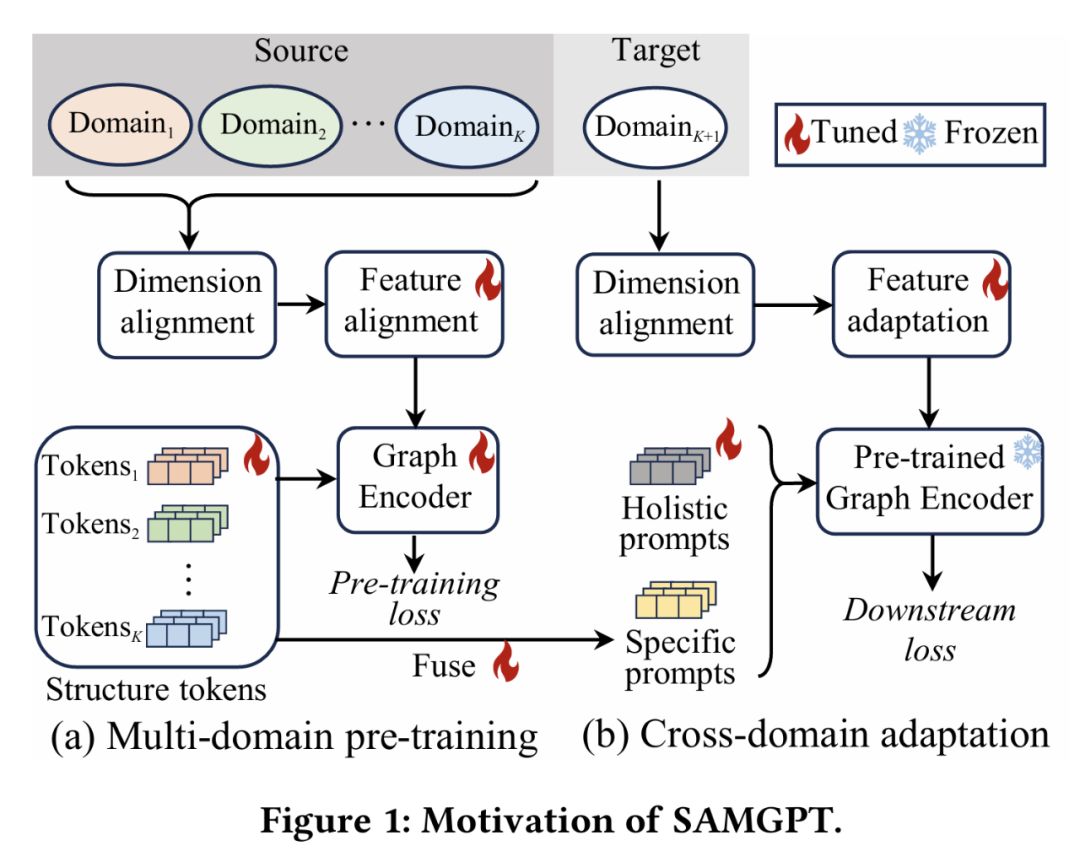
3.1 结构对齐的多域图预训练
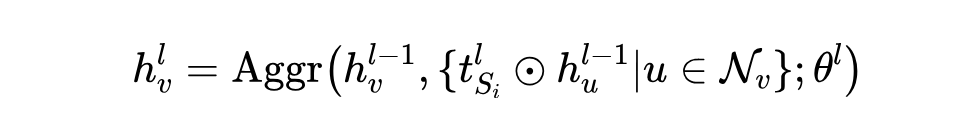
通过在所有域中的图中堆叠结构对齐的输出矩阵,我们获得了整体结构对准嵌入矩阵:
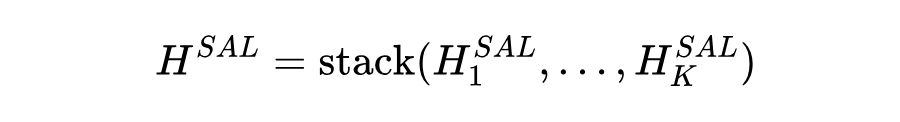
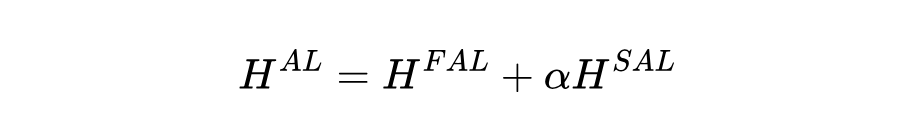
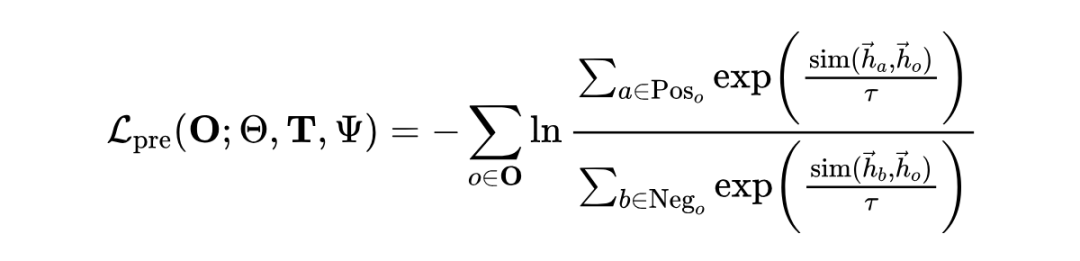
而 、、 分别是 、、 对应的嵌入向量。 是一个相似性函数,例如余弦相似度。 是温度超参数。
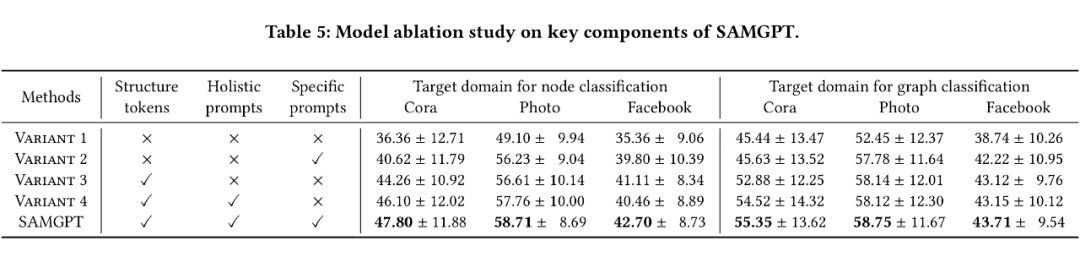
为了将整体多域结构知识转移到下游任务,我们提出了一组旨在使目标域 𝐷𝑇 与在源域 d𝑆 上进行预训练的模型的整体提示。与任何预训练框架一样,我们使用带有冷冻层的编码器 。但是,关键区别在于,我们注入一系列可学习的向量 作为整体提示,基于下游结构进行聚合:
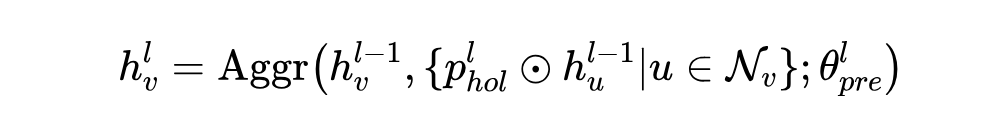
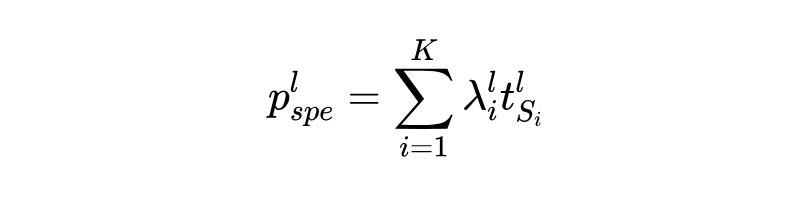
为了利用预训练模型中的整体多域和特定域结构知识,我们将通过整体提示和特定提示获得的输出嵌入矩阵进行融合:
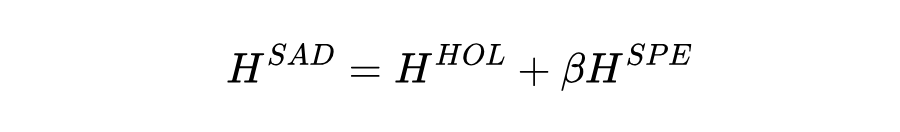
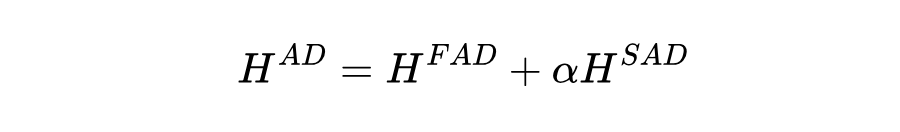
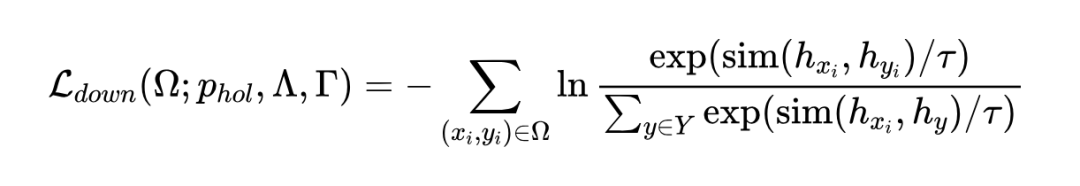

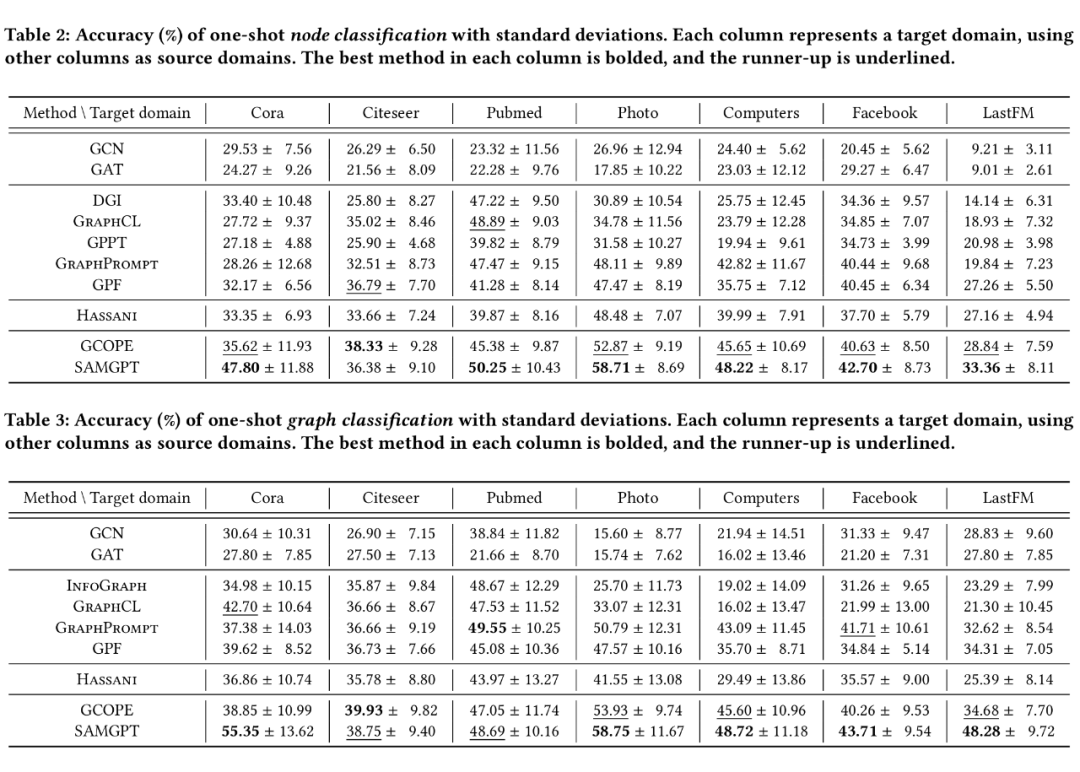
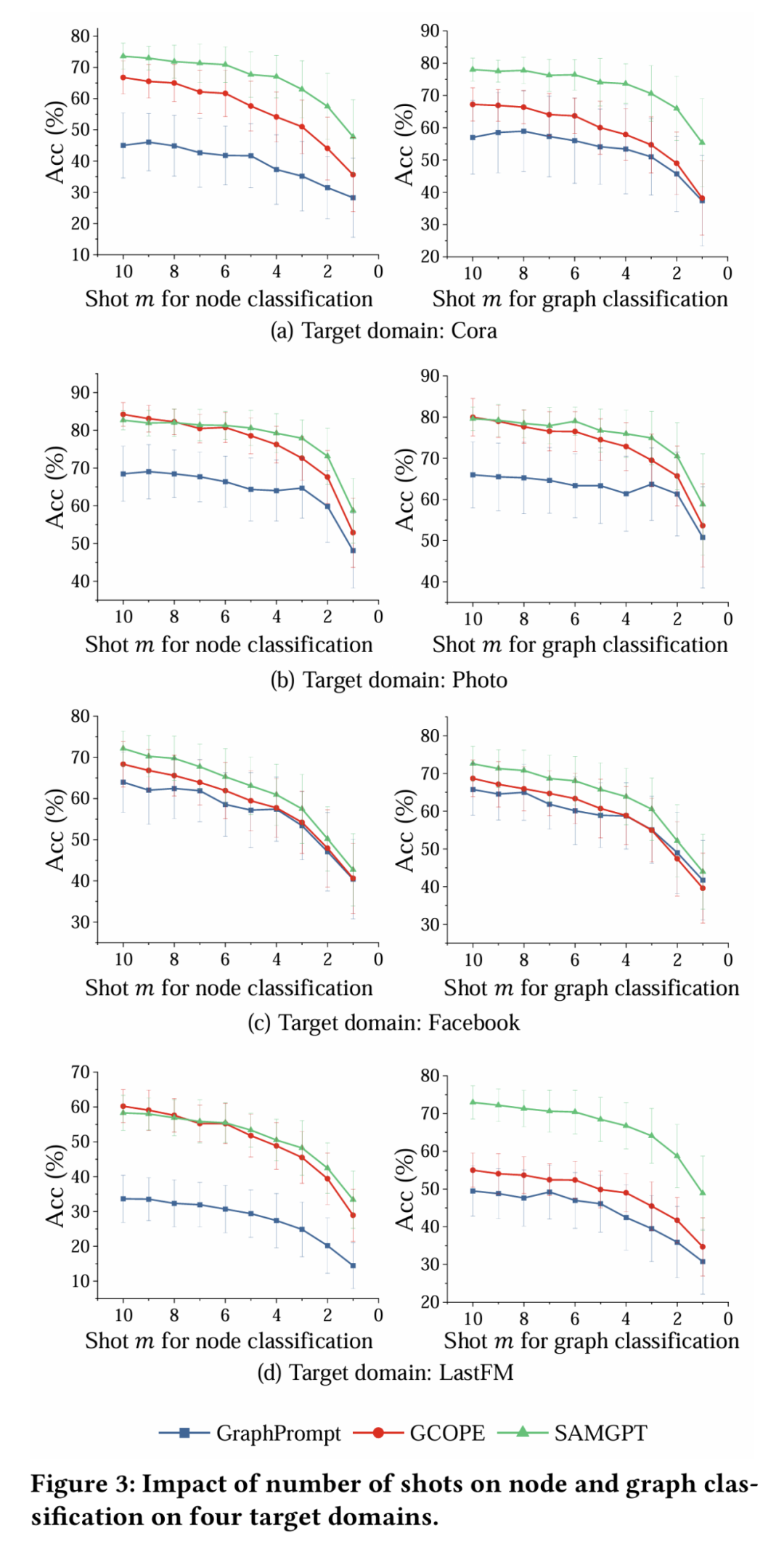
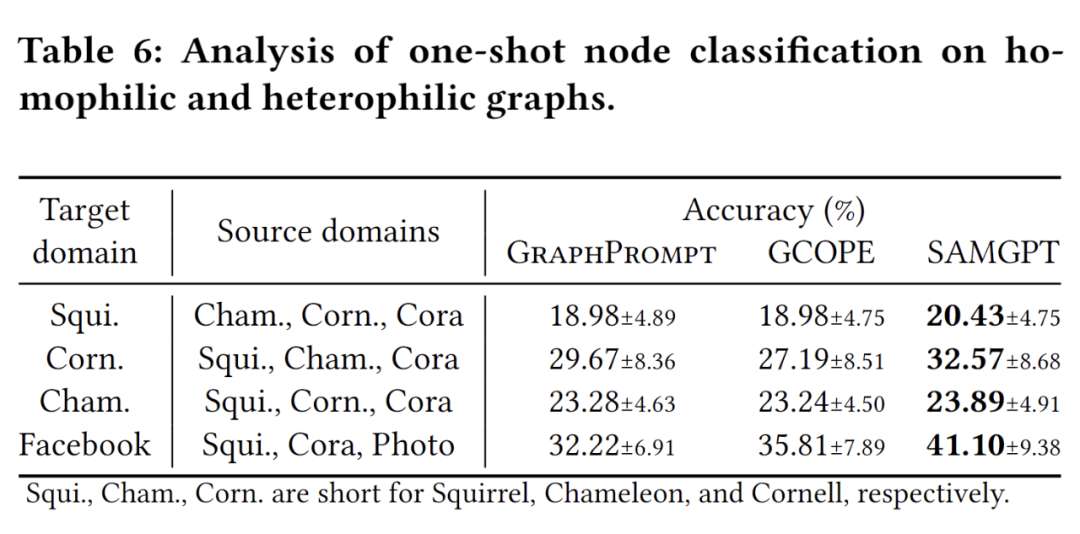
在跨领域 1-shot 设置下,SAMGPT 在各个目标域中都在节点和图形分类中取得了出色的性能,这证明了我们所提出的结构令牌在多域预处理和跨域适应中的双重提示中的有效性。
其次,另一种无文本的多域预训练方法 GCOPE 显着落后于 SAMGPT,因为它仅对特征和同质模式进行对齐和适应性,而无需考虑跨域之间的结构差异。这进一步强调了我们的结构令牌和双重提示的重要性。
(文:PaperWeekly)