

策略函数(policy)
详细说明
-
表示在时间步 时的状态(state)。 -
状态是环境对智能体的当前描述,例如在游戏中可能是角色的位置、速度等信息。
-
表示在时间步 时智能体采取的动作(action)。 -
动作是智能体在给定状态下可以执行的操作,例如在游戏中可能是“向左移动”或“跳跃”。
-
是策略函数(policy),表示在状态 下选择动作 的概率。 -
如果是确定性策略, 会直接输出一个确定的动作;如果是随机策略,它会输出一个动作的概率分布。
-
在 PPO 中, 是新策略 和旧策略 在状态 下选择动作 的概率比。 -
这个比值用于衡量策略更新的幅度,并通过裁剪机制限制其变化范围,确保训练的稳定性。
举例说明
-
状态 :角色的位置。 -
动作 :可以执行的动作是“向左”或“向右”。 -
策略 :在某个位置 下,策略可能以 70% 的概率选择“向左”,以 30% 的概率选择“向右”。
总结
近端策略优化(PPO)
核心思想
公式
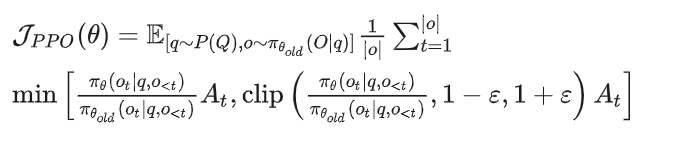
-
: 查询 从分布 中采样。 -
: 输出 由旧策略 生成。
-
是输出序列的长度。
-
是新旧策略的概率比。 -
是优势函数,衡量动作的相对好坏。 -
是裁剪参数,通常为 0.1 或 0.2。
步骤
-
采样:使用当前策略与环境交互,收集数据,在语言模型中,可以类比为生成补全(generating completions)。 -
计算优势值:基于收集的数据计算优势值函数 。 -
优化目标函数:通过梯度上升优化目标函数 。 -
更新策略:重复上述步骤,直到策略收敛。
优点
-
稳定性:通过裁剪机制,避免策略更新过大。 -
高效性:相比 TRPO,PPO 实现更简单,计算效率更高。
补充
Advantage(优势函数)
定义
-
是动作值函数,表示在状态 下采取动作 后,未来累积回报的期望。 -
是状态值函数,表示在状态 下,按照当前策略采取动作后,未来累积回报的期望。 -
是优势函数,表示在状态 下采取动作 比平均表现好多少(或差多少)。
作用
-
Advantage函数用于指导策略更新: -
如果 ,说明动作 比平均表现更好,策略应该更倾向于选择这个动作; -
如果 ,说明动作 比平均表现更差,策略应该减少选择这个动作的概率。 -
在PPO等算法中,Advantage函数通常通过GAE(Generalized Advantage Estimation)来估计。
直观理解
KL Penalty(KL散度惩罚)
定义
-
是当前策略(由模型参数 决定)。 -
是参考策略(通常是更新前的策略或某个基线策略)。 -
是KL散度,用于衡量两个策略之间的差异。
作用
-
KL Penalty用于防止策略更新过大,确保当前策略不会偏离参考策略太远。这样可以避免训练过程中的不稳定现象(如策略崩溃)。 -
在PPO等算法中,KL Penalty通常被添加到目标函数中,作为正则化项。
直观理解
Advantage和KL Penalty的关系
-
Advantage 用于指导策略更新,告诉模型哪些动作更好。 -
KL Penalty 用于约束策略更新,防止策略变化过大。 -
在PPO等算法中,Advantage和KL Penalty共同作用,既鼓励模型选择更好的动作,又确保更新过程稳定可靠。
举例说明
-
Advantage:机器人发现“向右转”比“向左转”更容易找到出口,于是Advantage函数会给“向右转”一个正的值,鼓励策略更倾向于选择“向右转”。 -
KL Penalty:为了防止策略突然变得只选择“向右转”而忽略其他可能性,KL Penalty会限制策略的变化幅度,确保策略更新是平滑的。
总结
-
Advantage(优势函数):衡量某个动作比平均表现好多少,用于指导策略更新。 -
KL Penalty(KL散度惩罚):限制策略更新的幅度,确保训练过程的稳定性。
群体相对策略优化(GRPO)
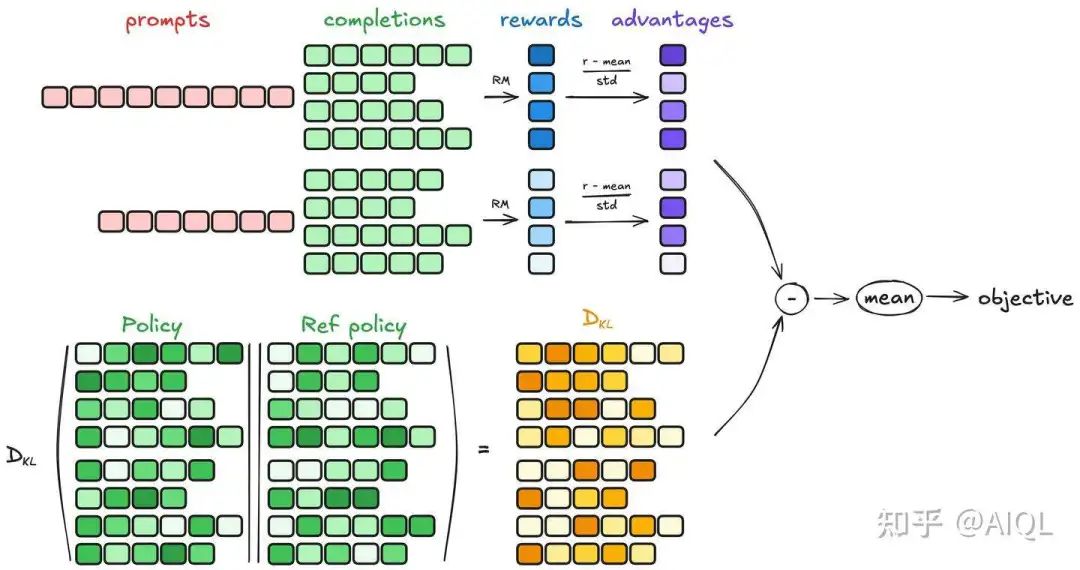
-
生成补全(Generating completions) -
计算优势值(Computing the advantage) -
估计KL散度(Estimating the KL divergence) -
计算损失(Computing the loss)
1. 生成补全(Generating completions)
2. 计算优势值(Computing the advantage)
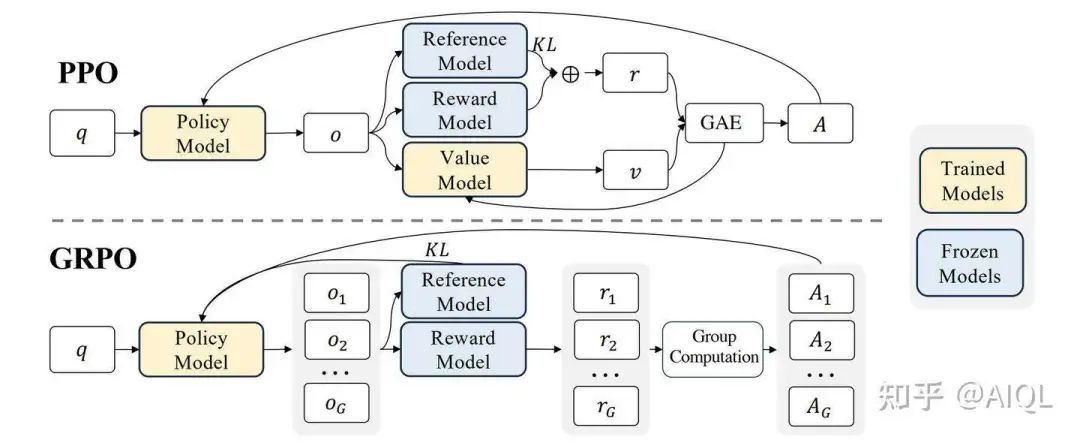
3. 估计KL散度(Estimating the KL divergence)
-
计算复杂度高:KL散度的定义涉及对两个概率分布的对数比值的期望计算。对于复杂的策略分布,直接计算KL散度可能需要大量的计算资源; -
数值稳定性:在实际计算中,直接计算KL散度可能会遇到数值不稳定的问题,尤其是当两个策略的概率分布非常接近时,对数比值可能会趋近于零或无穷大。近似器可以通过引入一些数值稳定性的技巧(如截断或平滑)来避免这些问题; -
在线学习:在强化学习中,策略通常需要在每一步或每几步更新一次。如果每次更新都需要精确计算KL散度,可能会导致训练过程变得非常缓慢。近似器可以快速估计KL散度,从而支持在线学习和实时更新。

-
第一项: 是参考策略与当前策略的概率比值。 -
第二项: 是对数概率比值。 -
第三项: 是一个常数项,用于调整近似器的偏差。
近似器的直观理解
-
当 和 非常接近时,,此时 ,近似器的值趋近于零,符合KL散度的性质。 -
当 和 差异较大时,近似器会给出一个较大的正值,反映出两个分布之间的差异。
4. 计算损失(Computing the loss)
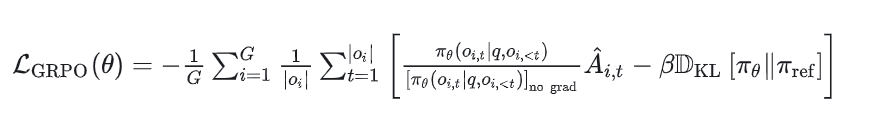
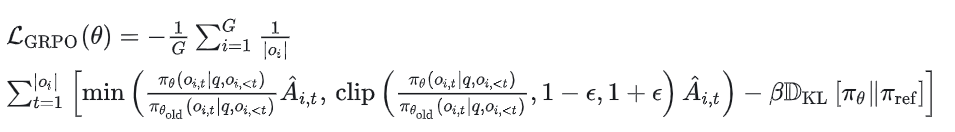
总结
写在最后
(文:机器学习算法与自然语言处理)