

极市导读
本文介绍了一种名为 Transfusion 的多模态模型,它通过结合语言建模(文本)和扩散模型(图像)的训练目标,实现了在单一模型中无缝生成离散文本和连续图像。研究通过大规模实验表明,Transfusion 在多模态任务上表现出色,生成质量和效率均优于现有的离散化图像处理方法,并在图像生成和文本生成任务中达到了与专门模型相当的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
一个模型完成图像生成和理解任务的先驱。
Transfusion 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。Transfusion 的训练数据是图像文本混合模态的数据,训练的目标函数是 Diffusion Loss (常用于训练图像生成模型) 和 Language Modeling Loss (Next Token Prediction,常用于训练语言模型)。Transfusion 可以达到 7B 的参数量级。
实验表明,Transfusion 模型既可以做文本生成和图像生成任务,也可以做图像理解任务。且作者将其与具有相似功能的 Chameleon 模型进行了对比,Transfusion 模型明显优于 Chameleon。通过引入特定于模态的编码和解码层,可以进一步提高 Transfusion 模型的性能,甚至将每个图像压缩到只有 16 个 Patch。
将 Transfusion 扩展到 7B 参数和 2T 多模态 token 训练之后可以得到一个模型,该模型可以与相似尺度的扩散模型相媲美生成图像,与相似尺度的语言模型媲美生成文本。
下面是对本文的详细介绍。
本文目录
1 Transfusion
(来自 Meta)
1 Transfusion 论文解读
1.1 Transfusion 研究背景
1.2 Transfusion 的两个目标函数
1.3 Transfusion 具体方法
1.4 实验设置
1.5 与 Chameleon 的比较
1.6 消融实验
1 Transfusion:类卷积线性扩散 Transformer
论文名称:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
论文地址:http://arxiv.org/pdf/2408.11039
1.1 Transfusion 研究背景
多模态生成模型需要能够感知、处理并生成离散元素 (比如 text 或 code) 和连续元素 (比如 image、audio 和 video 数据)。虽然使用 next-token prediction 技术训练的 LLM 主导离散模态的数据,那对于连续模态的数据而言,Diffusion Model 及其变体 Flow Matching 仍是最好的技术。
一个很自然的想法就是组合这两者,即 LLM 和 Diffusion Model。事实上已经有很多这样的尝试了。比如 DreamLLM,把预训练的 Diffusion Model 嫁接到 LLM 上。或者,在离散 token 上训练标准语言模型,以丢失信息为代价简化模型架构。
本文提出 Transfusion,通过训练单个模型 (不是一个 Diffusion Model,一个 LLM 嫁接)来预测离散 text token 和扩散连续 image ,可以在不损失信息的情况下完全集成两种模态。Transfusion 无缝集成了连续和离散两种模态。
Transfusion 为每个模态使用不同的目标:在 50% 文本和 50% 图像数据上预训练 Transformer 模型,文本使用 next token prediction,图像使用 diffusion。在训练的每一步,Transfusion 都使用两种模态的损失函数来训练。标准 Embedding 层将 text token 转换为向量,patchify 层把 image 表示为 patch 向量的序列。对 text token 应用 causal mode attention,对 image patch 应用 bi-directional attention。对于推理,引入了一种解码算法,它结合了语言模型文本生成的标准做法和来自扩散模型的图像生成。
Transfusion 是一个 7B transformer (包含约 0.27B 的 U-Net down/up 层),在 2T token 上进行训练。1T text token,1T image tokens (约 692M images)。图 2 显示了从模型中采样的一些生成的图像。在 GenEval 基准测试中,Transfusion 优于其他流行的模型,如 DALL-E 2 和 SDXL;与图像生成模型不同,Transfusion 还可以生成文本,且达到与 Llama 1 相同的性能水平。因此,Transfusion 是训练生成理解统一模型的一种很有前途的方法。


1.2 Transfusion 的两个目标函数
Transfusion 是一个用两个目标训练的单一模型:语言建模和扩散。
语言建模损失就是给定一系列离散 tokens ,语言模型预测序列 的概率。标准语言模型将 分解为条件概率的乘积 $\prod_{i=1}^n P_\theta\left(y_i \mid y_{<i}\right)$ 。这就是一个自回归分类任务。=”” next-token=”” prediction=”” 的目标函数,也可以说成是=”” lm=”” loss:<=”” p=””>
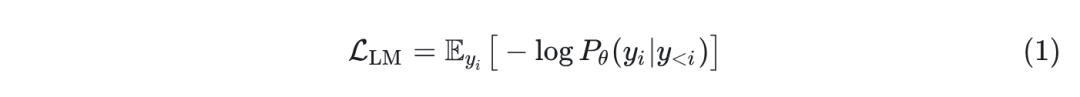
一旦经过训练之后,语言模型也可用于通过从模型分布 P_\theta 的 token 中采样 token 来生成文本,通常使用温度和 top-p 截断。
DDPM 学习逆转噪声添加的过程。与通常使用离散 token 的语言模型不同,扩散模型在连续向量( )上运行,这使它们特别适合涉及图像等连续数据的任务。扩散模型涉及 2 个过程:描述原始数据如何变成噪声的前向过程,以及模型学习执行的反向去噪过程。
前向过程
前向过程定义了如何创建噪声数据。给定一个数据点 ,定义一个马尔可夫链,它在 步上逐渐添加高斯噪声,创建一系列越来越嘈杂的版本 。每个步骤的定义是: ,其中 根据预定义的噪声时间表随时间增加。这个过程可以重参数化,允许使用单个高斯噪声样本 从 直接采样 :
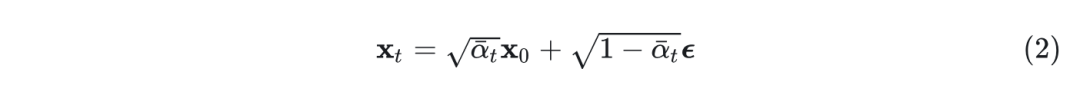
其中, 。
反向过程
训练扩散模型执行反向过程 ,学习逐步去噪数据。训练一个参数为 的模型 来估计给定噪声数据 和时间步 的噪声 。在实践中,模型通常以额外的上下文信息 为条件,例如在生成图像时的 caption。因此,通过最小化均方误差损失来优化噪声预测模型的参数:
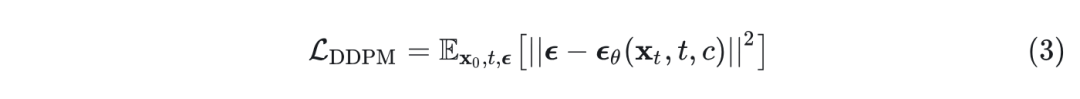
噪声 schedule
在创建噪声 时, 决定了噪声方差,本文基本遵循 。
推理
解码是迭代完成的,每一步处理一些噪声。从 处的纯高斯噪声开始,模型 预测在时间步 积累的噪声。然后根据噪声调度对预测的噪声进行缩放,从 中去除预测噪声的比例量,生成 。Classifier-free guidance(CFG)将以上下文 为条件的模型的预测与无条件得预测进行对比来改进生成,但代价是计算量加倍。
1.3 Transfusion 具体方法
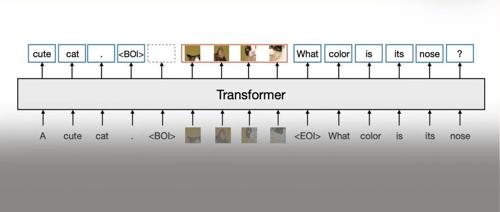
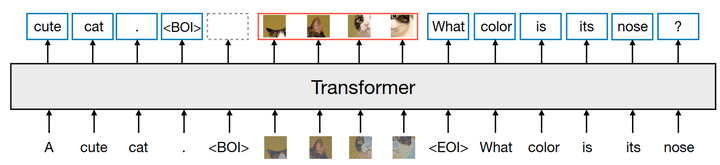
Transfusion 是一种训练单个统一的模型来理解和生成离散和连续模态的方法。主要创新是证明了可以在在共享数据和参数的情况下,使用对于不同模态的单独的损失函数,即用于文本的语言建模损失函数、用于图像的扩散损失。图 1 是 Transfusion 的流程。
数据准备
作者对两种模态的数据进行了实验:离散的文本和连续的图像。每个文本字符串都被标记为来自固定词汇表的离散 token 序列,其中每个 token 表示为一个整数。每个图像都使用 VAE 编码为 latent patch,其中每个 patch 表示为一个连续向量。patch 从左到右的从上到下排序。也就是每个图像最终都会转化为一系列的 patch 向量。作者在把这些向量插入到文本序列之前,使用特殊的 BOI 作为开始 token,EOI 作为结束 token,围绕图像序列。
因此,最终序列的样子是:包含了离散元素 (表示文本 token 的整数) 和连续元素 (表示图像 patch 的向量)。
模型架构**
模型参数的绝大部分都属于一个 Transformer,它输入一个序列,输出一个序列,无论模态如何。为了将数据转换到这个空间,作者对于不同模态的数据使用了具有非共享参数的特定的组件。
对于文本而言,文本是嵌入矩阵,将每个输入整数转换为向量空间,每个输出向量转换为词汇表上的离散分布。
对于图像,将 的 patch 转化为单个向量的方法,作者试了 2 种:1) 线性层;2) U-Net Up 或者 Down 层。如图 3 所示。

注意力机制**
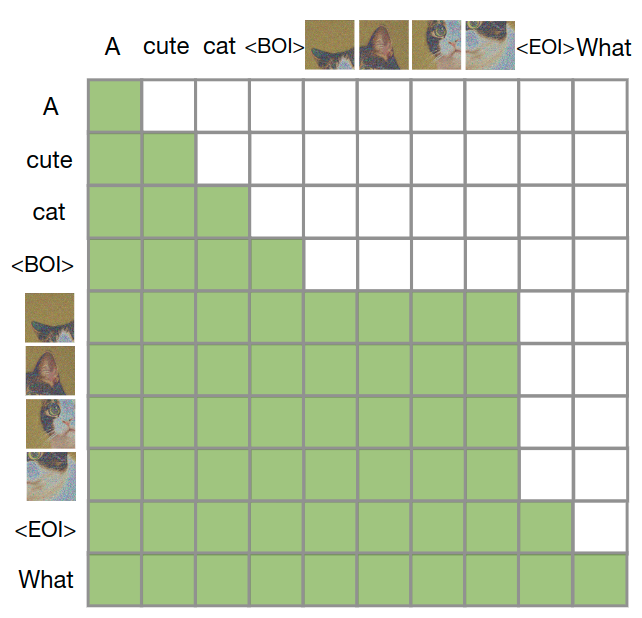
语言模型通常使用 causal mask 在单个前向后向传递中有效地计算整个序列的损失和梯度,而不会泄露来自未来 token 的信息。虽然文本自然是连续的,但图像不是,并且通常使用不受限制的 bi-directional attention 进行建模。Transfusion 通过将 causal attention 应用于序列中的每个元素以及每个单独图像元素之间的 bi-directional attention 来结合这两种注意力模式。这允许每个图像 patch 关注同一图像中的所有其他 patch,但只关注序列中先前出现的其他图像 patch 或者文本 。作者发现启用图像内注意力可以显着提高模型性能。图 4 显示了一个示例 Transfusion attention mask。
训练目标
为了训练本文模型,作者将语言建模目标 LM Loss 应用于文本标记的预测,将扩散目标 DDPM Loss 应用于图像 patch 的预测。LM Loss 是 per-token 计算的,而 DDPM Loss 是 per-image 计算的,这可能会跨越序列中的多个元素(图像 patch)。具体来说,根据扩散过程为每个输入 添加噪声 ,在 patchification 之前产生 ,然后计算图像级扩散损失。通过简单地将每个模态上计算的损失与平衡系数 结合起来:
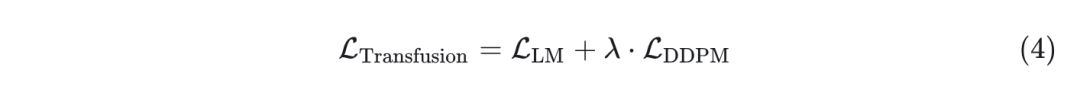
这个目标函数将离散分布损失与连续分布损失结合以优化相同的模型。未来作者将继续探索将扩散替换为流匹配。
推理过程
Transfusion 的解码算法在两种模式之间切换:LM 和 Diffusion。在 LM 模式下,遵循从预测分布中逐 token 采样。当采样 BOI 令牌时,解码算法切换到扩散模式,从扩散模型中解码。具体来说,以 个图像 patch 的形式附加到输入序列(取决于所需的图像大小),并去噪 步。在每一步 ,采用噪声预测并使用它来生成 ,然后覆盖序列中的 。一旦扩散过程结束,将 EOI 标记附加到预测图像上,并转换回 LM 模式。该算法能够生成任何混合文本和图像模式。
1.4 实验设置
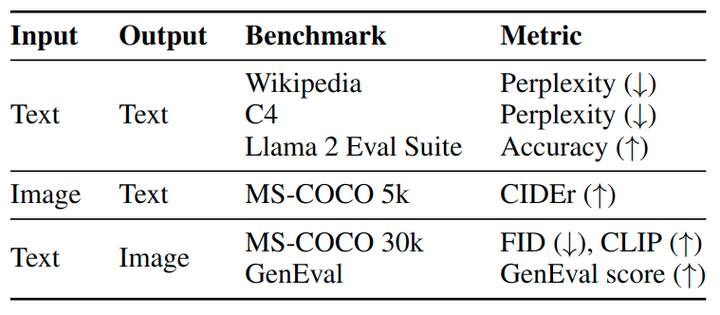
评测
在单模态和跨模态任务上评测 Transfusion,如图 5 所示。text-to-text 任务使用在 Wikipedia 和 C4 corpus 上的困惑度进行评测,text-to-image 任务使用 MS-COCO benchmark 进行评测,还有 GenEval 评测框架。image caption 任务在 MS-COCO 上评测,汇报 CIDEr 得分。
Baseline
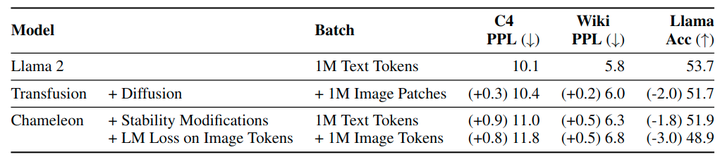
本文遵循 Chameleon 的训练策略,训练一系列数据和计算控制的模型。Chameleon 和 Transfusion 之间的主要区别在于,虽然 Chameleon 离散化图像并将它们处理为 token,但 Transfusion 将图像保持在连续空间中,消除了量化信息瓶颈。为了进一步最小化任何混杂变量,使用完全相同的数据、计算和架构训练 Chameleon 和 Transfusion 的 VAE,唯一区别是 Chameleon VQ-VAE 的量化层和码本损失。Chameleon 还修改了 Llama 架构,添加了 query-key normalization, post-normalization, denominator loss 和使用较低学习率 1e-4 来应对训练不稳定性。
数据
对于几乎所有的实验,作者以 1:1 的 token 比从两个数据集中采样 0.5T token。对于文本,使用 Llama 2 分词器和语料库,包含跨不同域分布的 2T tokens。对于图像,使用 380M 许可 Shutterstock 图像和字幕的集合。每个图像都是中心裁剪的,并调整大小以产生 256×256 像素。
Latent 图像表征
作者训练了一个 86M 参数的 VAE。使用 CNN 编码器和解码器,latent 维度为 8。训练目标结合了重建损失和正则化损失。将 256×256 像素的图像降维到 32×32×8,其中每个 latent 的 8 维 latent 像素 (在概念上) 代表原始图像中的 8×8 patch,并训练 1M 步。对于 VQ-VAE 训练,与 VAE 训练描述的设置遵循相同的训练策略。除了 的 替换 codebook commitment loss。我们使用 16,384 个标记类型的码本。
模型配置
为了研究缩放趋势,作者按照 Llama 的标准设置,训练了 5 种不同的大小的模型,即 0.16B、0.37B、0.76B、1.4B 和 7B 参数。图 6 详细描述了每个设置。

推理
在文本模式下,使用 greedy decoding 生成文本。对于图像生成,采样 250 个 diffusion steps (模型在 1,000 个 time steps 上进行训练)。遵循 Chameleon 并在比较实验中使用系数为 5 的 CFG。该值对于 Transfusion 是次优的。因此,Transfusion 在消融实验使用 3 的 CFG,并遵循在大规模实验中调整每个系数的标准实践。
1.5 与 Chameleon 的比较
作者做了一系列对照实验来比较不同模型大小和 token 数的 Transfusion 与 Chameleon 进行比较。为简单起见和参数控制,这些实验中的 Transfusion 使用简单的 linear 图像 Encoder/Decoder,Patch Size 为 2×2,以及双向注意力。对于每个基准,在 log-FLOPs 曲线上的对数度量上绘制所有结果。
图 7 显示了缩放趋势。在每个测试中,Transfusion 始终表现出比 Chameleon 更好的 scaling law。虽然线条接近平行,但 Transfusion 显着更好。图像生成中计算效率的差异尤为显着,Transfusion 使用 34× 的计算量获得与 Chameleon 相当的 FID。
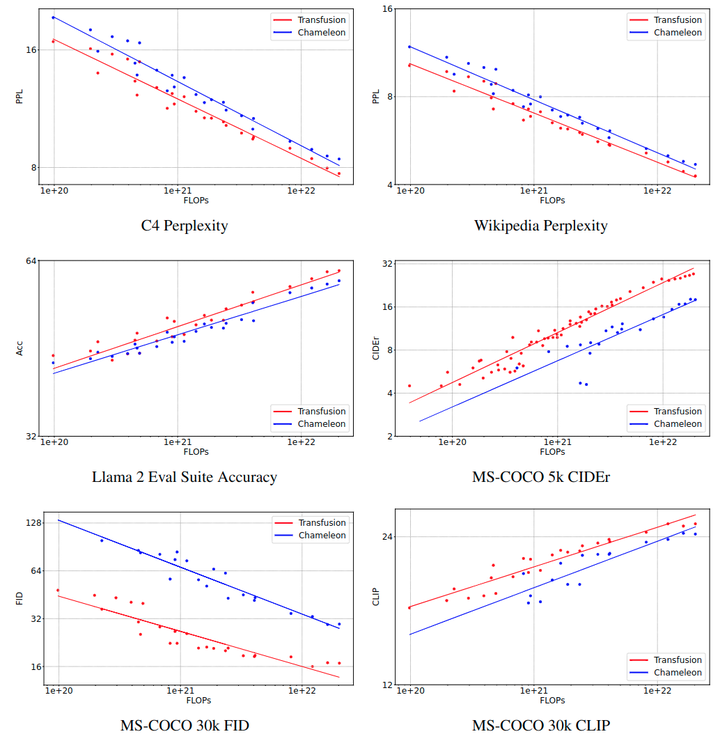
图8 是 parity FLOP ratio,即 Transfusion 和 Chameleon 达到相同性能水平所需的 FLOPs 之比。

令人惊讶的是,Transfusion 也在纯文本 benchmark 表现出好的性能,即使 Transfusion 和 Chameleon 模型以相同方式建模文本。图 9 显示,Chameleon 存在对架构所做的稳定性修改,也引入 image token。对量化 image token 的训练在所有 3 个 benchmark 上降低了文本性能比扩散更多。一个假设是这源于输出分布中 text token 和 image token 之间的竞争;或者,扩散在图像生成方面可能更高效,且需要更少的参数,允许 Transfusion 模型使用比 Chameleon 更多的容量来对文本进行建模。
1.6 消融实验
Patch Size
Transfusion 模型可以使用不同大小的 Patch Size。更大的 Patch Size 允许模型在每个 training iteration 中打包更多的图像并显着减少推理计算,但代价是可能会损失性能。图 10 展示了这些性能权衡。虽然性能会持续下降,因为每个图像都用更少的 patches 表示了,但 U-Net encoding 的模型受益于更大 Patch。作者认为这是由于训练期间看到的总图像的数量更多。作者还观察到,对于较大的 Patch Size,文本性能会恶化,这可能是因为 Transfusion 需要更多的参数来学习如何处理 patches 较少的图像,从而减少推理计算。
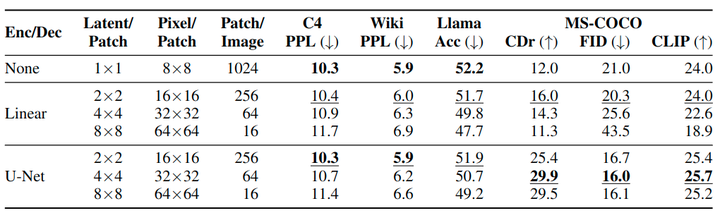
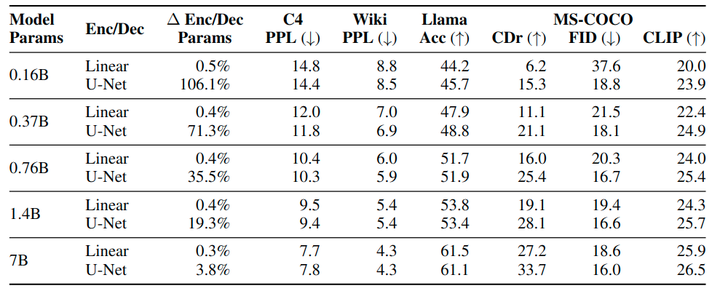
Patch Encoder 和 Decoder 架构
到目前为止,实验表明,使用 U-Net 比简单的线性层具有优势。一个可能的原因是该模型受益于 U-Net 架构的归纳偏置;另一种假设是,这一优势源于 U-Net 层引入的整体模型参数增加。为了将这 2 个混杂因素解耦,将核心Transformer 扩展到 7B 参数,同时保持 U-Net 参数数量,额外的编码器/解码器参数仅占总模型参数的 3.8%,相当于 token Embedding 参数的数量。
图 11 显示,尽管 U-Net 的相对优势随 Transformer 尺寸的增长而缩小,但依然是有的。例如,在图像生成中,U-Net Encoder 和 Decoder 使得更小的模型,比具有 linear patchify 层的 7B 模型获得了更好的 FID 分数。作者观察到 image caption 的类似趋势,添加 U-Net 层可以提高 1.4B Transformer 的 CIDEr 分数,超过 linear 层的 7B 模型的性能。总体而言,U-Net Encoder 和 Decoder 似乎确实具有归纳偏差的好处,而不仅仅是加了额外的参数。
图像噪声
本文训练数据中,80% 的数据是 text-image 对,就是以 text 作为 condition 来生成 image。20% 的数据是 image-caption 对,就是以 image 作为 condition 来生成 caption。直觉是图像生成可能比图像理解更需要大量数据的任务。但是,这些图片因为 diffusion loss,是 noised 的。作者测试了 20% 数据中,将 diffusion noise 限制为 t=500 (一半) 的效果。图 12 显示,噪声限制显着提高了 image caption,如 CIDEr 分数,而其他 benchmark 的影响相对较小 (小于 1%)。
生成实验结果
到目前为止,Transfusion 比了 Chameleon 和 Llama,但尚没有将其图像生成能力与最先进的图像生成模型进行比较。为此,作者训练了一个具有 U-Net Encoder 和 Decoder 的 7B 参数大小,在 2T token (包括 1T 文本语料库标记和 3.5B 图像及其标题) 上训练的模型。该变体的设计选择和数据混合更倾向于图像生成。图 2 和展示了该模型生成的图像。
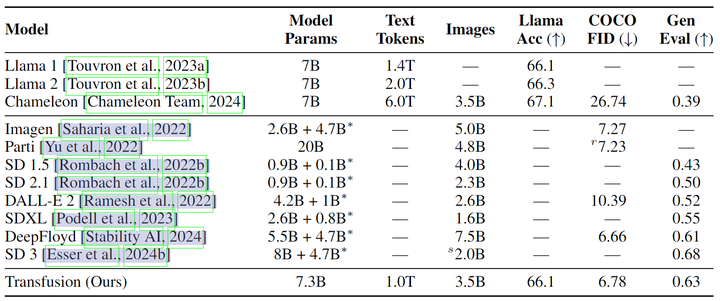
作者将 Transfusion 与其他相似尺度图像生成模型的结果以及一些公开可用的文本生成模型进行比较。图 12 显示 Transfusion 实现了与 DeepFloyd 等高性能图像生成模型相似的性能,同时超越了之前发布的模型,包括 SDXL。最后,Transfusion 模型也可以生成文本,并且与在相同文本数据分布上训练的 Llama 模型相当。

(文:极市干货)