


等了好久,谷歌终于开放了 Gemini 2.0 的原生绘图能力。
其实,Gemini 2.0 系列模型早在2024 年 12 月 就正式发布了,是谷歌首次支持原生多模态输出的版本(文本、图像、音频),但是当时并没有开放绘画能力。
昨天,谷歌正式放出了 Gemini 的原生绘画能力,目前大家可以直接在 Google AI Studio 免费体验。注意,这里是原生,由Gemini直接混合生成文字和图片(后文视频里能看到),而不是调用外部绘画模型。
大家体验一定是选Gemini 2.0 Flash Experimental这个实验版模型,输出设置成文本和图像混合输出。

我上手测了一天,基本全程 WOC,已献上我的膝盖。
GPT-4o是第一个主打原生多模态的模型,比如它的语音、视觉理解一放出来就当时就炸场了,但是它的绘画能力是通过调用外部的DALL·E来实现的。但是这次Gemini的绘图能力则是原生绘图,兑现了我对 GPT-4o 具备原生绘画能力的幻想!而且,Gemini绘图的“一致性”太顶了。
什么颠覆设计圈、动嘴 P 图、设计师噩梦看多就腻了,请看效果——
第一个:给人物变形出多种动作
23 年好多搞 AIGC 创业的朋友中一致认为能赚到钱为数不多的场景之一——
「淘宝电商的批量生图」
当然也是在那个时间就已经被吐槽非常卷的赛道。
我随便输入一张模特图,让 AI 换一些不同的拍照姿势
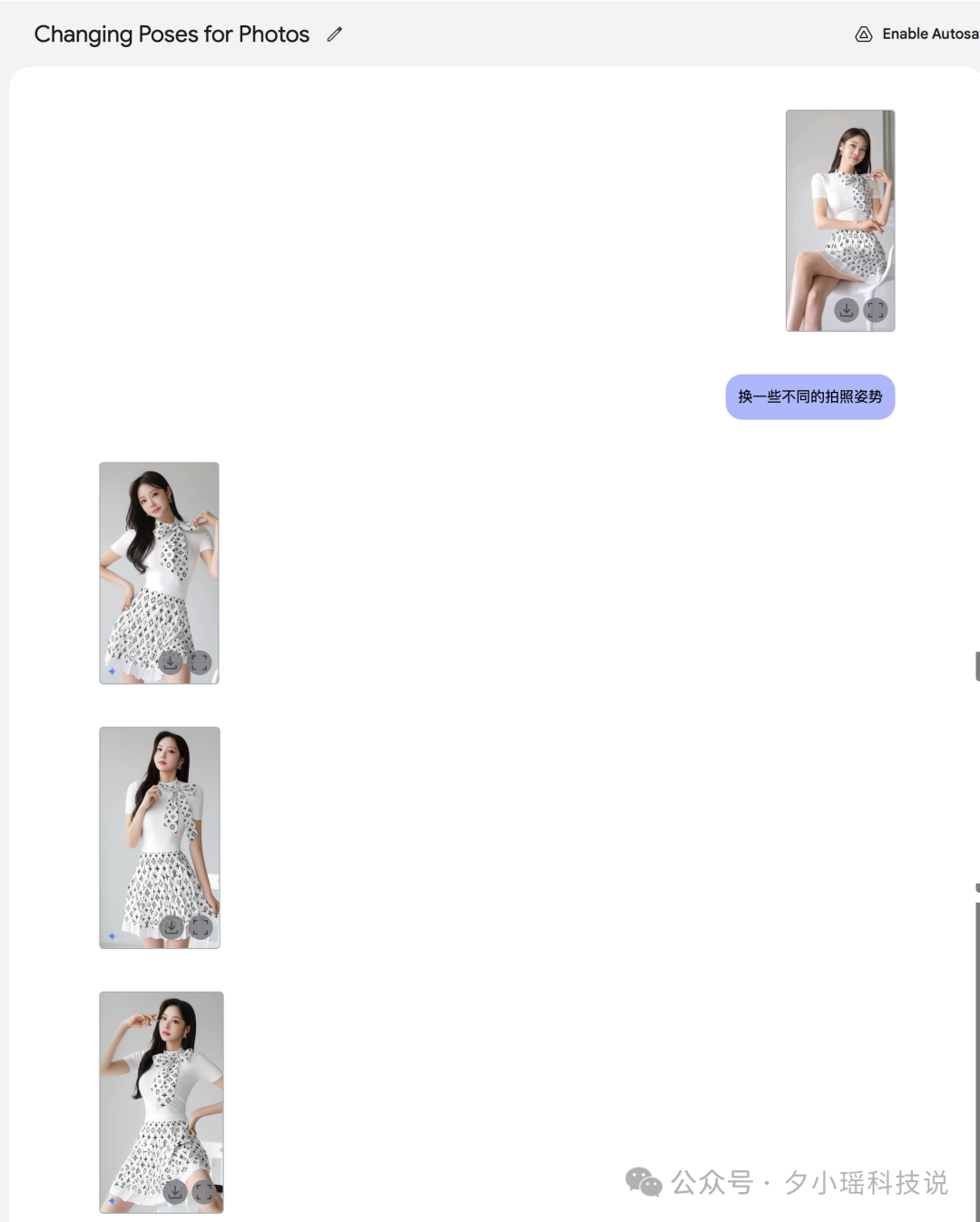
人物、裙子完美和原始模特保持一致,完全看不出是 AI 生成的。
第二个:14 轮连续对话修图
整个对话的过程是这样的:
-
draw a box(画一个箱子) -
make it silver(变成银色的) -
Realistic(真实点) -
最上面变成玻璃 -
玻璃下面,柜子上面放上珠宝 -
柜子变成高级的展示柜 -
变成真实材质的渲染图 -
柜体变成实木的 -
里面添加珠宝,光线明亮一些 -
添加背景环境和地板 -
珠宝区太亮了,稍微暗一点,环境奢华一些 -
暗一些 -
管线调整暗一些 -
过于暗了,正常的商场环境就行
从最开始画一个箱子,到经历 14 轮连续对话,变成一个商场的珠宝展示箱。
全程我就用的最简单的话,告诉它我的需求,跟指挥一个设计师给我画图一样,整个过程非常丝滑连贯。
一点点地调整,只有中间一步是强调了两遍光线变暗,其他都是一次过。
第三个:一句话生成绘本,插画师的噩梦
问题很简单:
给我讲一个小黑猫大战外星人的故事, 3d cartoon animation style. For each scene, generate an image.
猫的形象全程一致,而且表情丰富,就是连配角外星人的形象都保持了前后一致。
第四个:球鞋设计,从线稿到模特上身,一气呵成
连线稿都不用提供,我这里就是让 AI 直接生成,懒得找了。
中间让 AI 设计,上色,调整 nike 标和鞋底位置的颜色,调整配色风格,从一只变成一双,让职业运动员穿上看效果。
需求很多,尽可能去模拟真实工作环境的各种要求,就光一个“颜色太卡通,不够稳重”这个恶心的需求,日常让人干的话都多少天完成?就好比让申公豹长毛的特效。
我觉得这里的完成度也很好。
看完你就能理解,为什么我称 Gemini2.0 是一致性的神了。
它既能一次性生成多张图片,并保持角色、场景和风格的一致性。这真的能解决视频分镜和连续内容创作中的大痛点。也能在一轮轮的修改过程中保持一致性。我觉得大家可以加大轮数再试!
再来看看 X 上网友的 case:
第五个:游戏原画师也要噩梦了
这是 X 上网友的一个两个 case。都和游戏场景里有关。
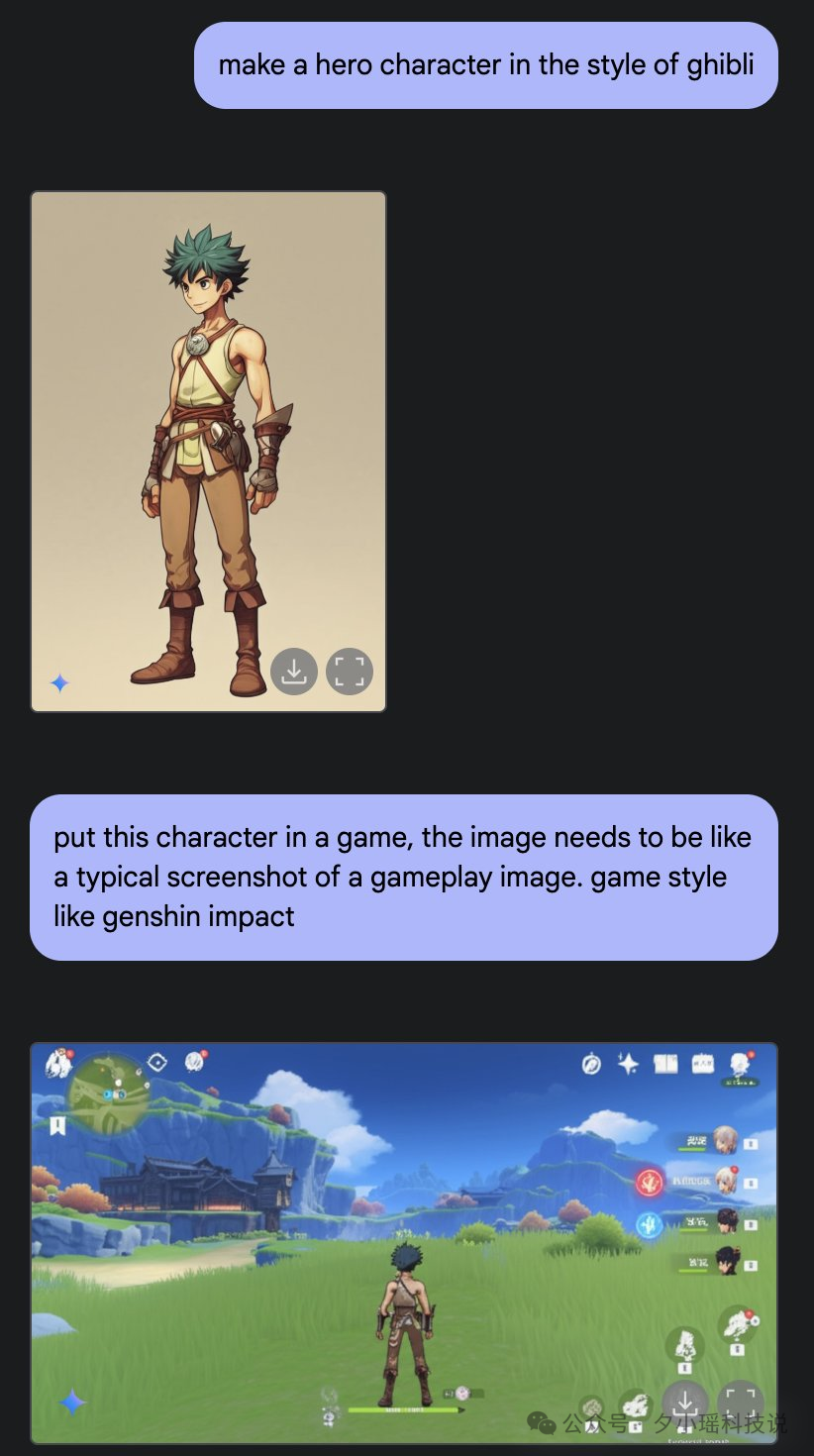
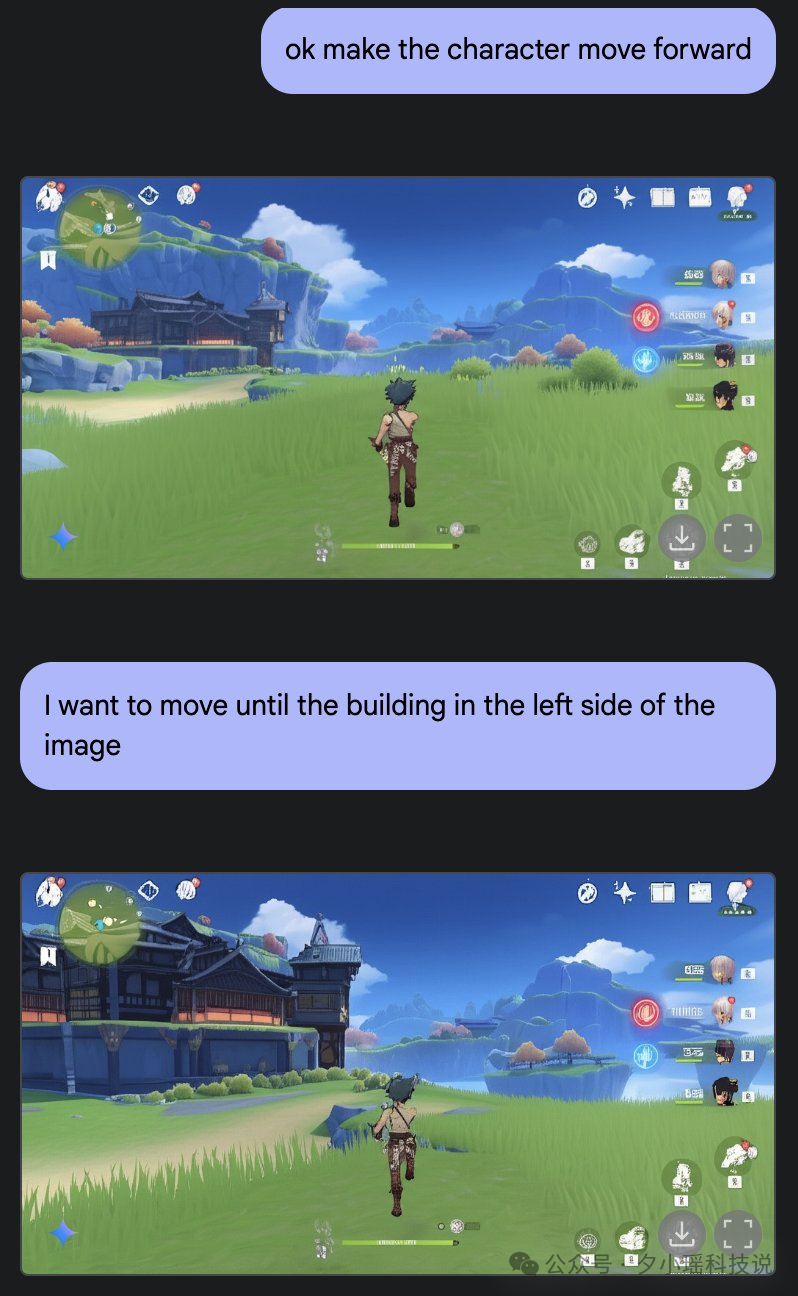
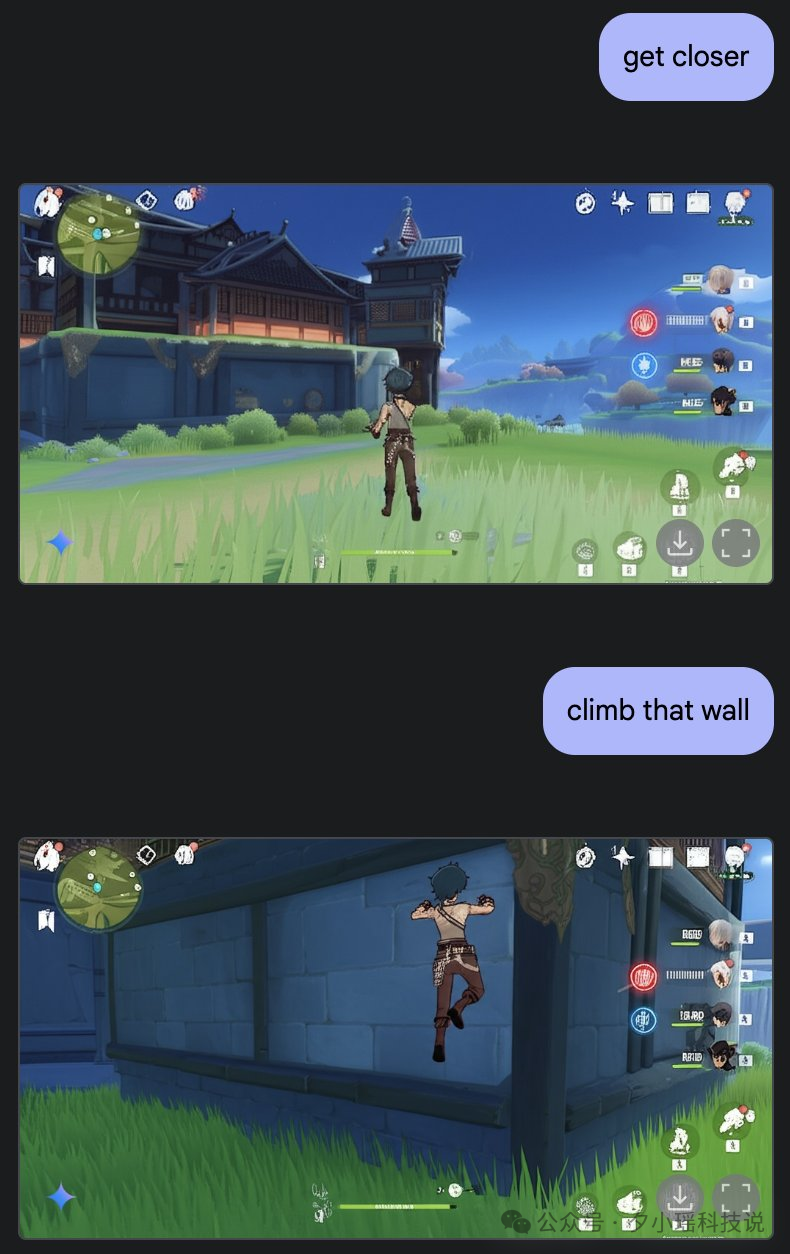
而且,能把具体的一个东西放在任何场景里都不会违和。
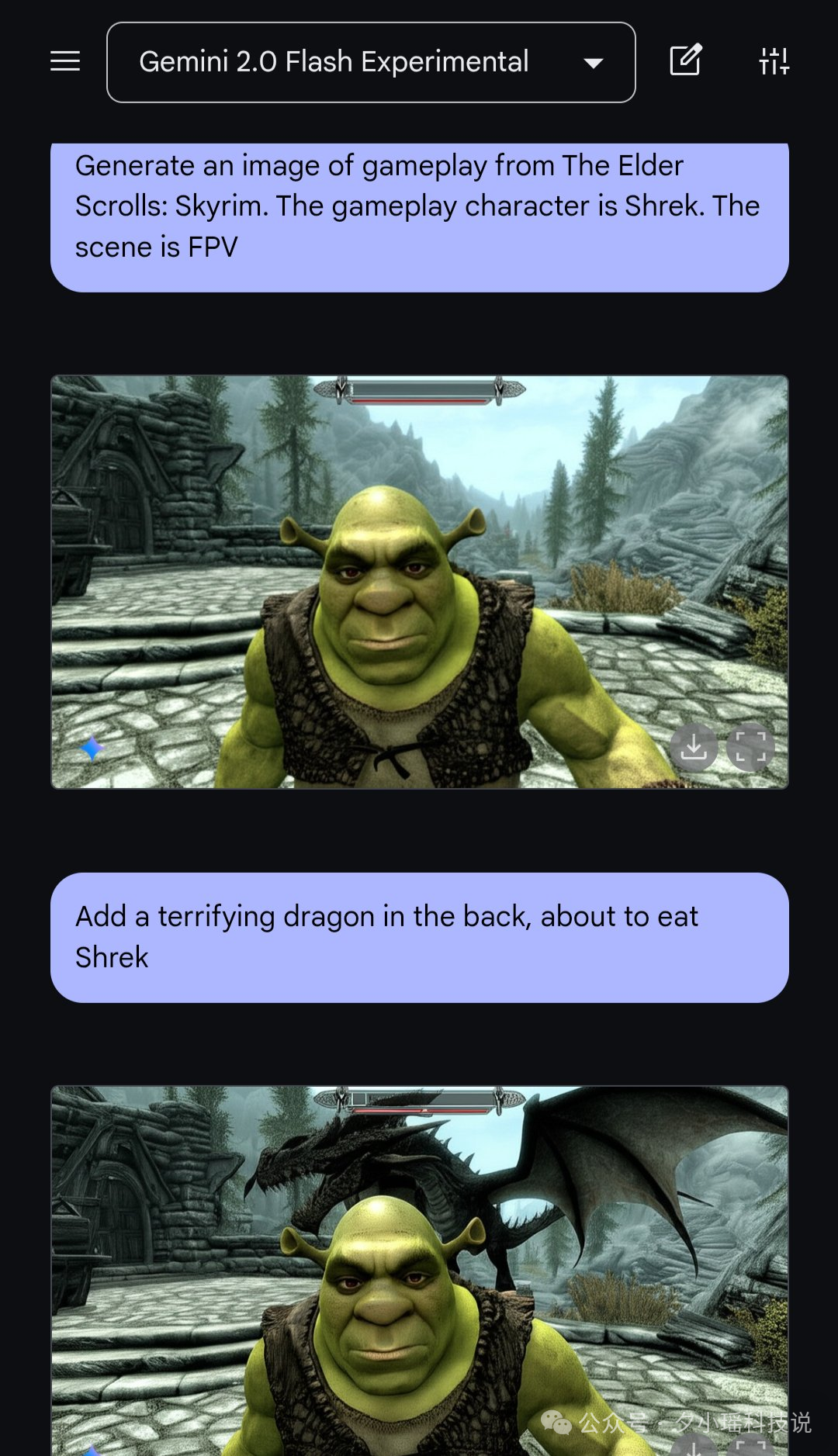
看完已献上我的膝盖。设计师看完都要集体沉默了。
但是别着急,夕小瑶的 case 怎么可能就到这儿!必须要为难一下它。看我下面跟上的几个 case,我发现它不是万能的。
好比这个 case——
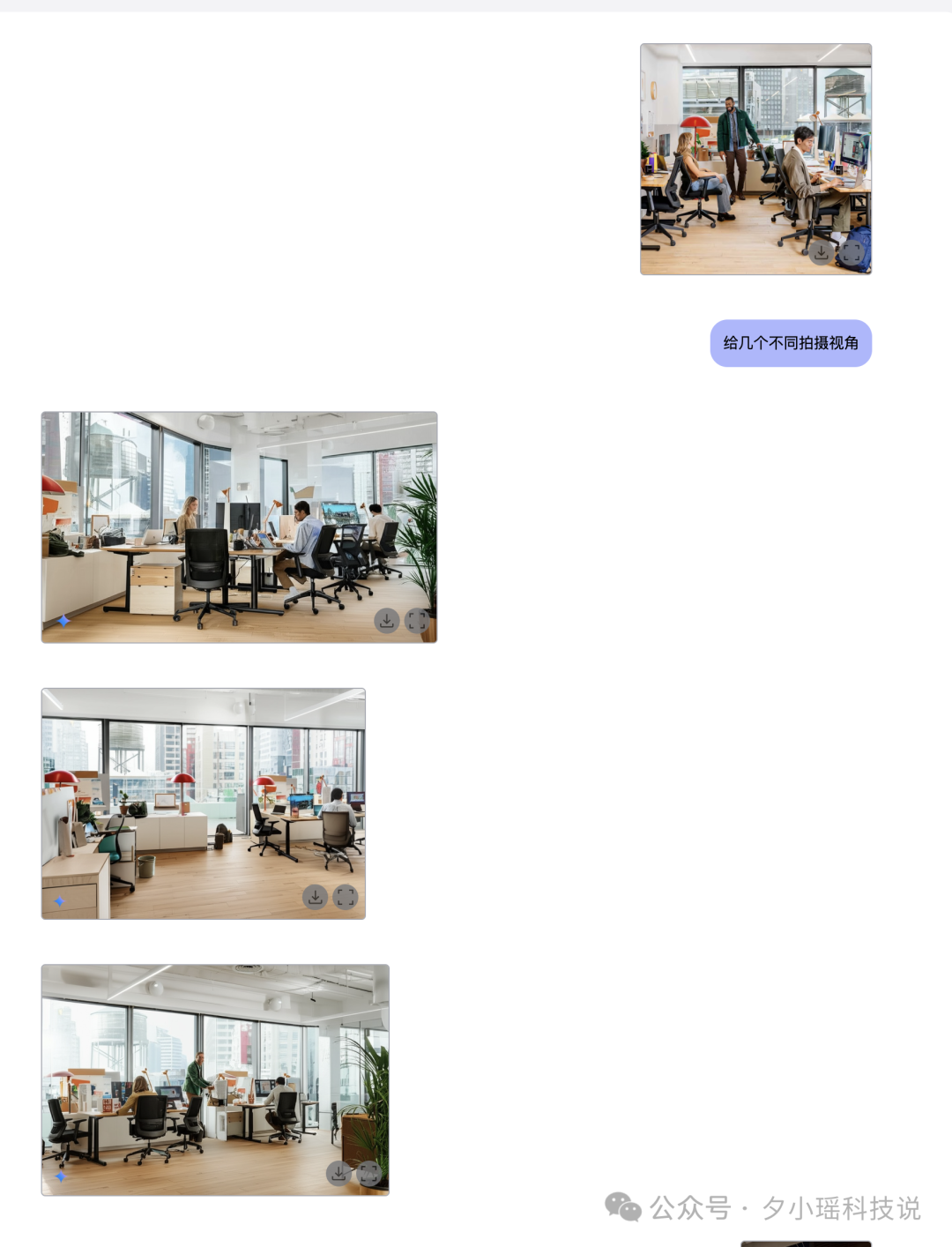
这是某一个拍摄角度下办公室照片,我要它“变换几个不同的视角”。

一共生成了 3 张新图,第一张和第三张感觉像是扩图了,视角开大了,第一看没有问题,还有点意外,但是经不起推敲。仔细看,绿植的位置不一样,电脑显示器也变形了,灯泡还有漏掉。总之就是不能看细节。
我猜测,如果图片元素过多,比较复杂,细节处理能力很有限。
继续看——
依旧是一张办公室的图,同样是让 AI 给一些不同的拍摄视角。
只能说照片类型感觉对了,都是精致布置的办公室,而且有人,但是并不是我要的不同拍摄角度。我的预期是人的相对位置不能改变。
一种原因是我的指令比较简单,没有细节描述,不够细致。另一种还是上面提到的过于复杂的问题。
刷着刷着突然看到一张照片,好多人聚会的一张图,我就突发奇想,来一道终结题目。
都知道站在前排的人显脸大,那如果换个角度,从最后面的人开始拍呢。
说实话,难度确实大。
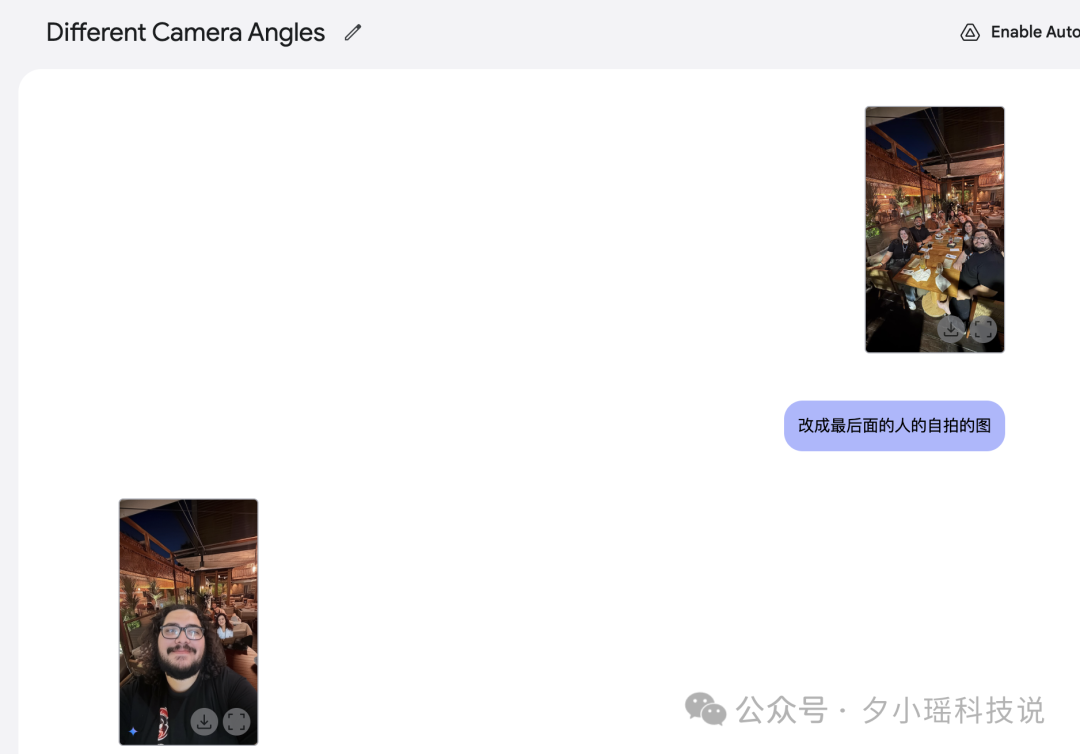


最后,Gemini 以惨败结束。毕竟这个要求 P 图师现在也做不到吧?
换个脸、换个发型、加个背景、扣掉一个东西,就是增删改一个简单的元素,是完全没有问题的;
再难一点,同一个主体变换动作,变换角度、变换一下场景,比如模特那个摆拍动作,小黑猫不同场景里也不会变形,都能保持非常不错的一致性,AI 操控的对象也是相对简单的,小猫没有那么多特征。
再再难一点,如果让 AI 操控一个复杂的、特征点多的、细节多的东西,就办不到了。
总之,经过一天上手的实测,Gemini2.0 的绘图能力依旧给我带来的感受是颠覆性的,它的一致性依旧是超超牛的存在,至少目前。
依旧有不足,但也请保持期待!
(文:机器学习算法与自然语言处理)