

今天是2025年3月19日,星期三,北京,天气晴。
本文继续看多模态推理。
多模态推理仍然是一个大多未探索的挑战。与文本推理不同,多模态推理要求模型迭代地从图像中提取、构建和验证信息。
关于多模态R1的工作,我们已经在《Agent or SFT or RL ? 9个多模态R1推理开源项目核心思路解析》(https://mp.weixin.qq.com/s/yIDqvJLASPWX6gkOoRr1Pg)中已经谈到很多,其中原本只有github地址的,目前相应给出技术报告的越来越多。
因此,我们可以再专题回顾下。
对于RL之前,大多基于longcot方式进行,我们来看三个代表工作,包括LLava-CoT、Llama-V-o1以及MAMmoTH-VL。
RL之后,看两个工作,一个是R1-Onevision通过图像形式化+SFT+RL实现思路,一个是LMM-R1通过两阶段规则型强化学习提高泛化性,技术报告出来了,看看技术细节。
此外,最近技术方面也出现了很多有趣的工具,以及一些选型方面的事情,比如文档测试,这块也一并讲讲,同步下技术社区早报,做个记录。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、回顾老刘说NLP技术社区20250318技术进展早报
【老刘说NLP20250318技术进展早报】,同样是跟进进展,围绕OCR文档解析评测、Agent可视化理解,LLM推理可解释性理解,强化学习DAPO以及推理大模型测试Case等话题,供各位参考,为社区例行活动,欢迎加入社区大家庭。

1、关于大模型测试case
有趣的现象,例如,问题:2的a次方+5的b次方=10,求a+b和ab的关系,deepseek-R1思考的确是没有停下来的意思,最终运行10分钟后才停下。
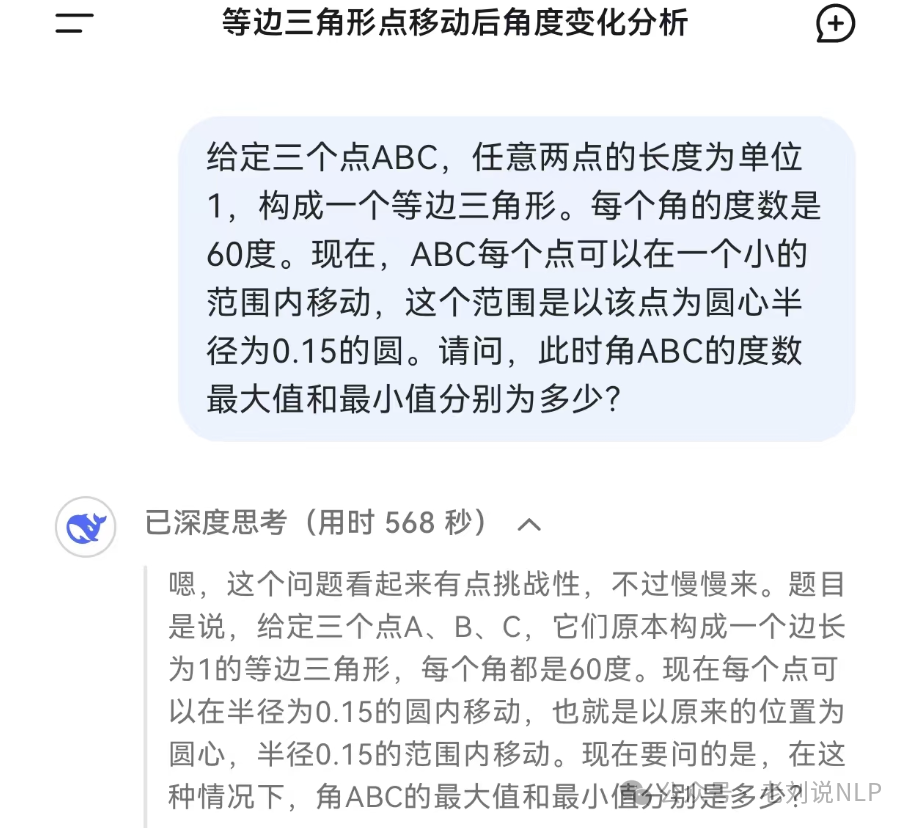
也有社区成员测的另一些case,如 等边三角形点移动后角度变化分析,给定三个点ABC,任意两点的长度为单位1,构成一个等边三角形。每个角的度数是60度。现在,ABC每个点可以在一个小的范围内移动,这个范围是以该点为圆心半径为0.15的圆。请问,此时角ABC的度数最大值和最小值分别为多少?,深度思考(用时 568 秒)
2、强化学习进展DAPO
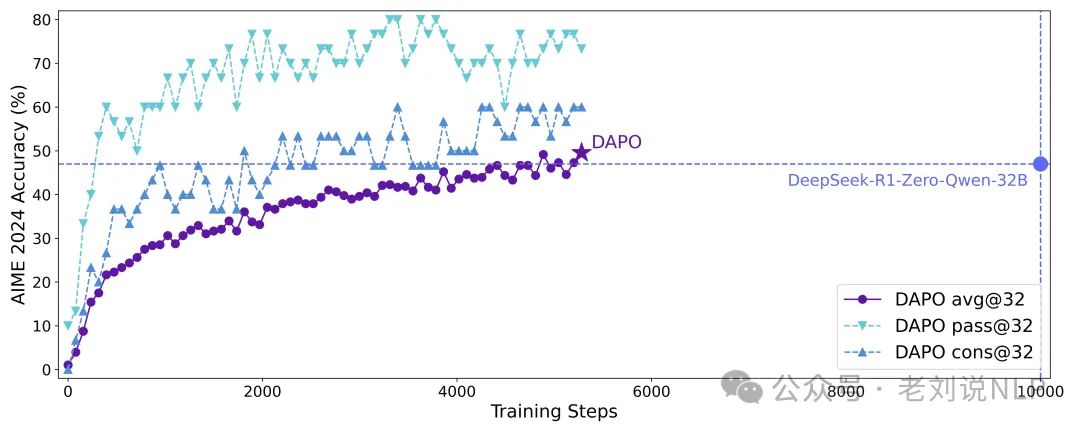
Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化),实现大规模LLM强化学习,https://dapo-sia.github.io/,论文:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf,代码:https://github.com/volcengine/verl/tree/gm-tyx/puffin/main/recipe/dapo,数据:https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k。
核心点在于:利用verl(https://github.com/volcengine/verl)训练框架从头开始,使用 Qwen2.5-32B模型和128个H20 GPU进行DAPO 训练,采用DAPO-Math-17k数据(https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k),规则奖励函数为:https://github.com/volcengine/verl/blob/gm-tyx/puffin/main/verl/utils/reward_score/math_dapo.py,在AIME2024(https://github.com/volcengine/verl)上的表现优于之前DeepSeek-R1-Zero-Qwen-32B,以减少50%的训练步骤实现了50% 的准确率。
3、大模型推理可解释性工具
可解释性一直是大模型的一个绕不开的话题,怎么更直白的理解内部原理,很重要。
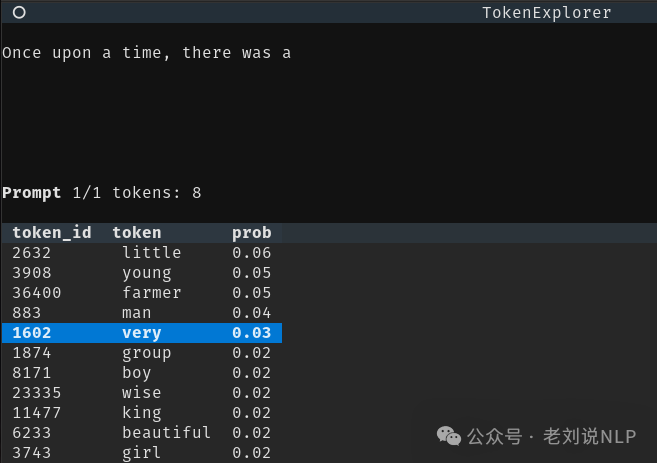
Token-explorer,能交互式的看到LLM生成token的过程:https://github.com/willkurt/token-explorer
具体技术核心点在于,在具体执行阶段,选择一个开始提示,或者提供您自己的文本文件。一步步生成一个token(使用箭头键导航、弹出和附加标记),查看token概率和熵。
当然,除此之外,还有另一个可解释性的工具,面向大模型推理。
大模型推理有思考过程,这已经是一种可解释性了,但是还是很黑盒,可以再直白一点。
没有可视化的图谱,用户难以解析复杂的推理路径、比较不同的方法以及识别不同推理方法的特征;逻辑谬误、循环推理和缺失步骤在冗长的文本输出中难以识别和纠正;缺乏标准化的可视化框架限制了逻辑表达框架和生产力工具的开发,这些工具可以改进和丰富LLMs应用。
之前其实也有一些了,例如,BertViz和Transformers Interpret,但都不是专门针对推理大模型做的。
所以,可以做一个大模型推理过程可视化工具,《ReasonGraph: Visualisation of Reasoning Paths》,https://github.com/ZongqianLi/ReasonGraph,也有论文,在https://arxiv.org/pdf/2503.03979,直观展示和分析多种推理方法的执行过程,集成了链式思考、自我改进等各类推理方法。
从目的上讲,其是为了实时图形渲染和分析LLM推理过程的,便于不同方法之间的比较分析。
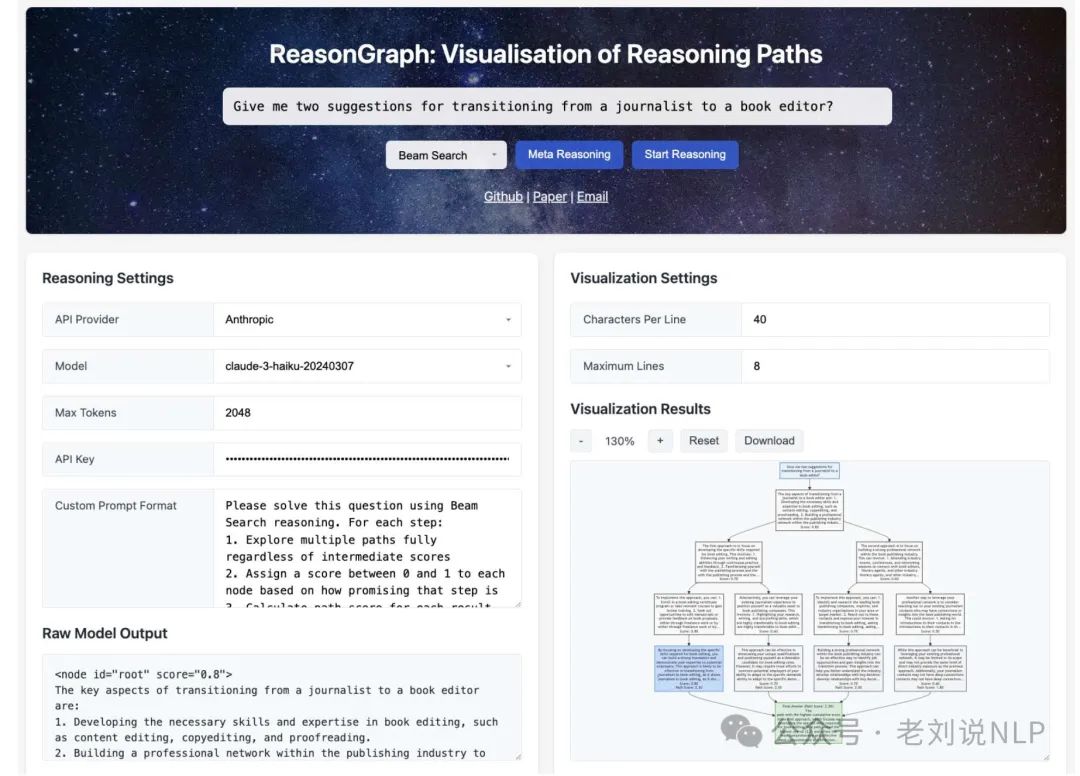
具体怎么做,也可以看看:
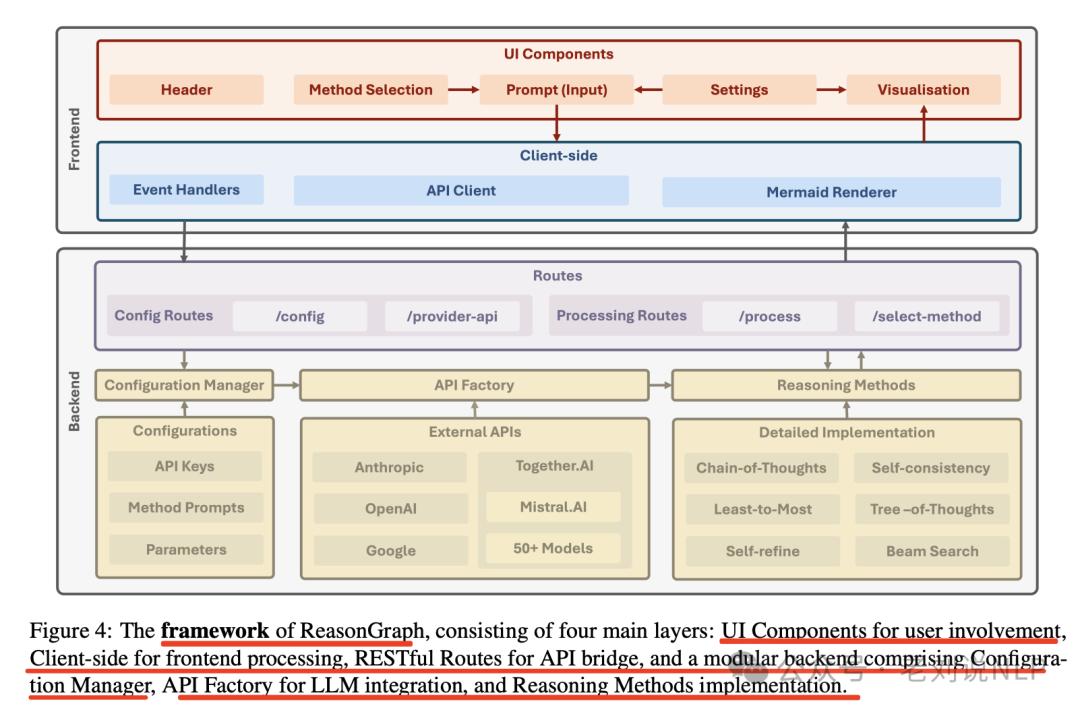
其中,可视化采用了树搜索方法和序列推理方法的实时图形化渲染和分析。对于树搜索方法(如束搜索),使用Mermaid处理,每个节点表示一个推理步骤,每个级别保持一致的分支宽度,允许全面探索解决方案空间。累积路径分数指导最终解决方案的选择,最优路径由所有级别的最高总分决定。对于序列推理方法,使用有向图布局展示不同推理方法的逐步进展。
4、关于文档解析评测
端到端OCR方案-SmolDocling我们应该关注什么?兼看AI搜索可信度简单评测项目,https://mp.weixin.qq.com/s/__WCQ-Yc_r_zcBJgIF8QIA,这段时间,文档这块omlocr,mistralocr,smoldocling,都是一路货色,且每次都被自媒体标榜最强,大家请保持清醒,远离之。
GOT2.0效果测下来,为多模态方式最好,但仅限于OCR,纯text转text。但GPu条件下最原始单样本推理,是cpu环境下paddleocr的1/10。所以,大家如果要效果不要速度,就接GOT。
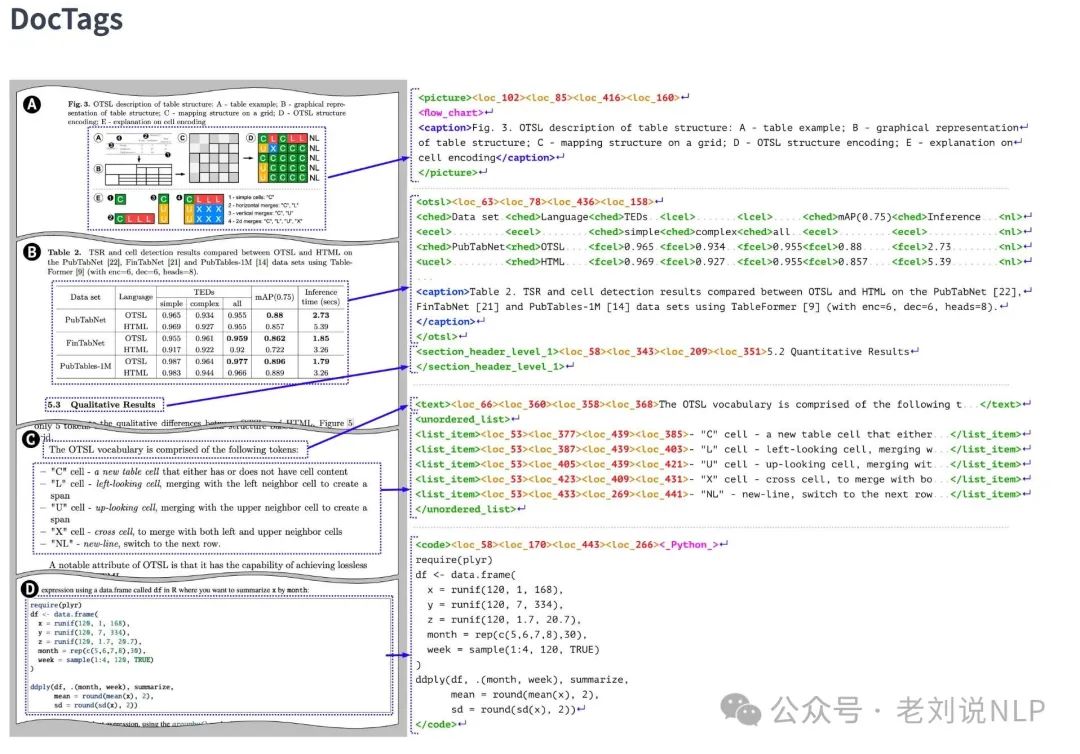
回到SmolDocling,核心差异性是:参数量小,只有256M参数,能够做多种任务,ocr可以带boudingbox,图片还能分类,功能很全。技术特点是自己设计了一套新的文档解析格式doctag,尤其是表格走的不是html/markdown/latex,而是OTSL(比html表示空间减少进30%)。
数据方面,近kw英文训练数据,多样性不足,严重过拟合,中文测试结果一坨xxxxx。
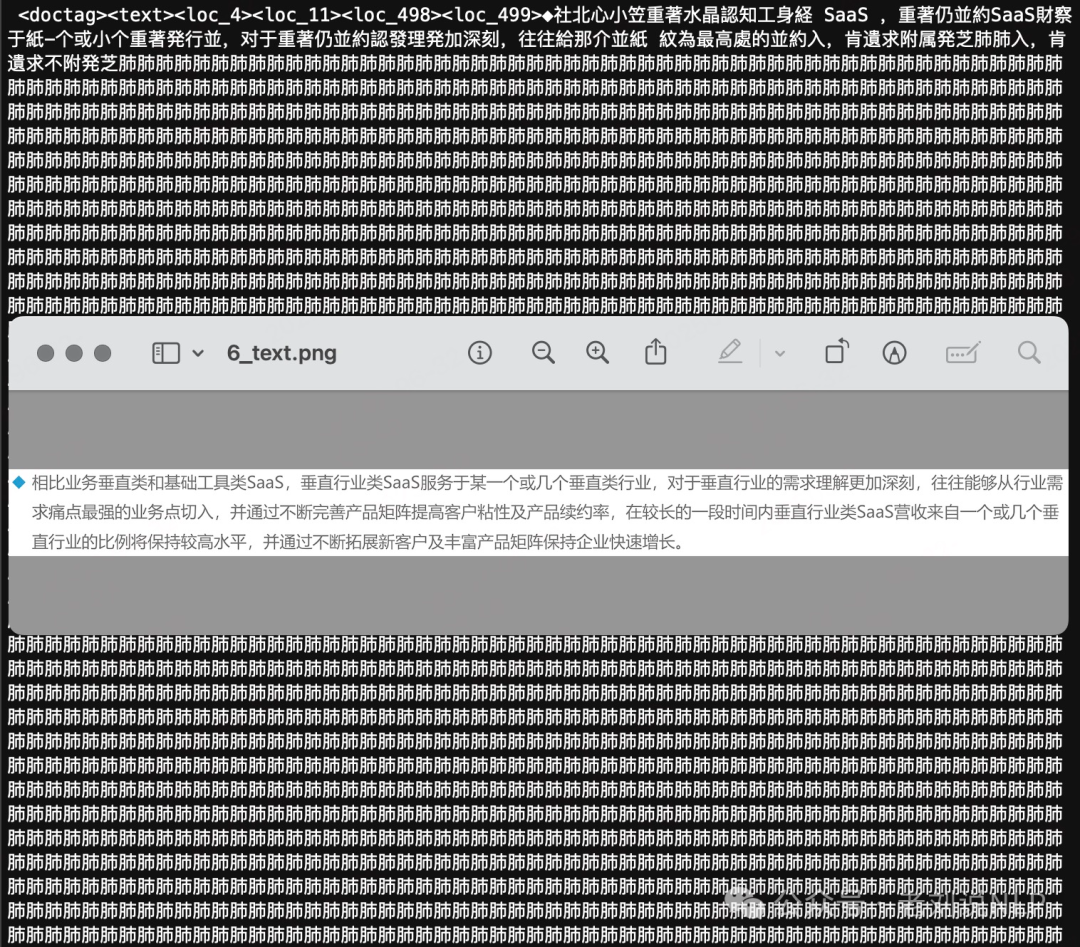
其提到的0.35s/page虽快,但基于的是参数量以及vllm加速。中文测试不可用。
所以,这里有一些总结,根本的根本:小参数量不是这种打法,其应该打单一任务,数据多样性,那种完全是大模型玩法,走反了。
6、关于agent的可视化理解
《A Visual Guide to LLM Agents Exploring the main components of Single- and Multi-Agents》,https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents,同样是几十张图。
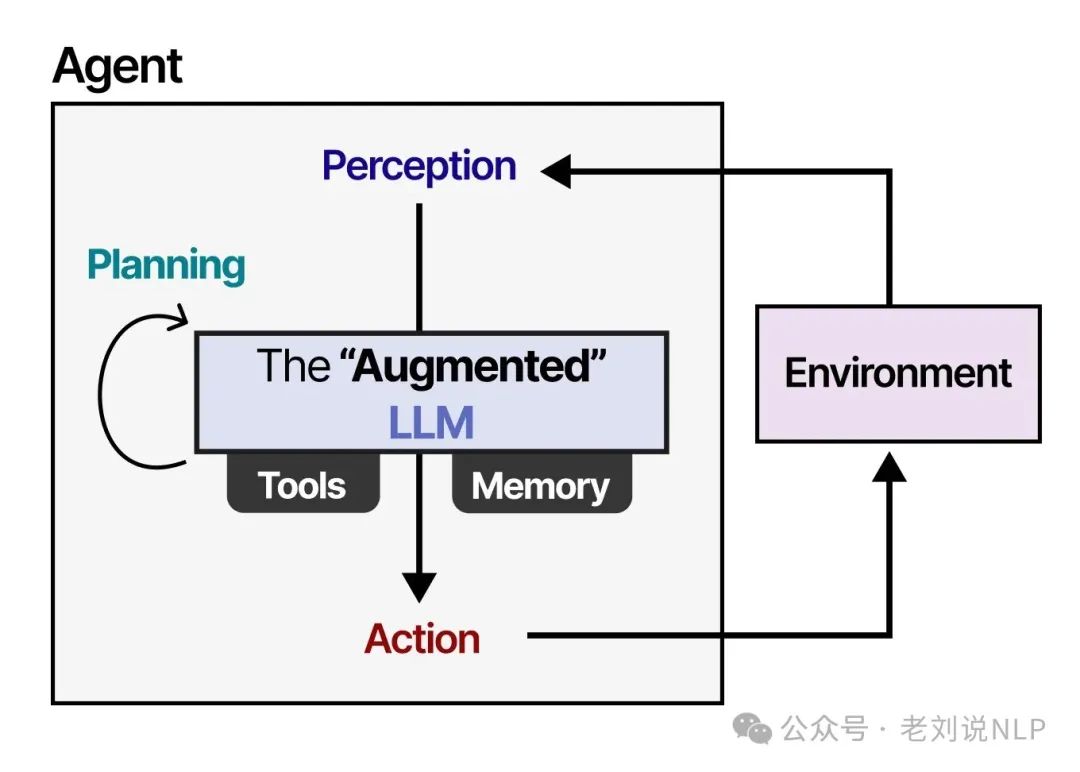
这个对于直白理解Agent会有帮助,已经形成一个系列了。
二、RL方案之前的多模态推理思路回顾
现有的视觉-语言模型往往无法组织可用信息并进行深入的推理过程,导致在视觉推理任务中失败。

如上图所示,Deekseek-R1因来自GPT-4o的不完整图像描述而遭受感知错误。
目前关于视觉-语言模型的研究越来越强调逐步推理。我们来看一些方案。
1、LLava-CoT
LLava-CoT《LLaVA-CoT: Let Vision Language Models Reason Step-by-Step,https://arxiv.org/pdf/2411.10440,https://github.com/PKU-YuanGroup/LLaVA-CoT》提出Summary stage、Caption stage、Reasoning stage和Conclusion stage四个手动预定义阶段。
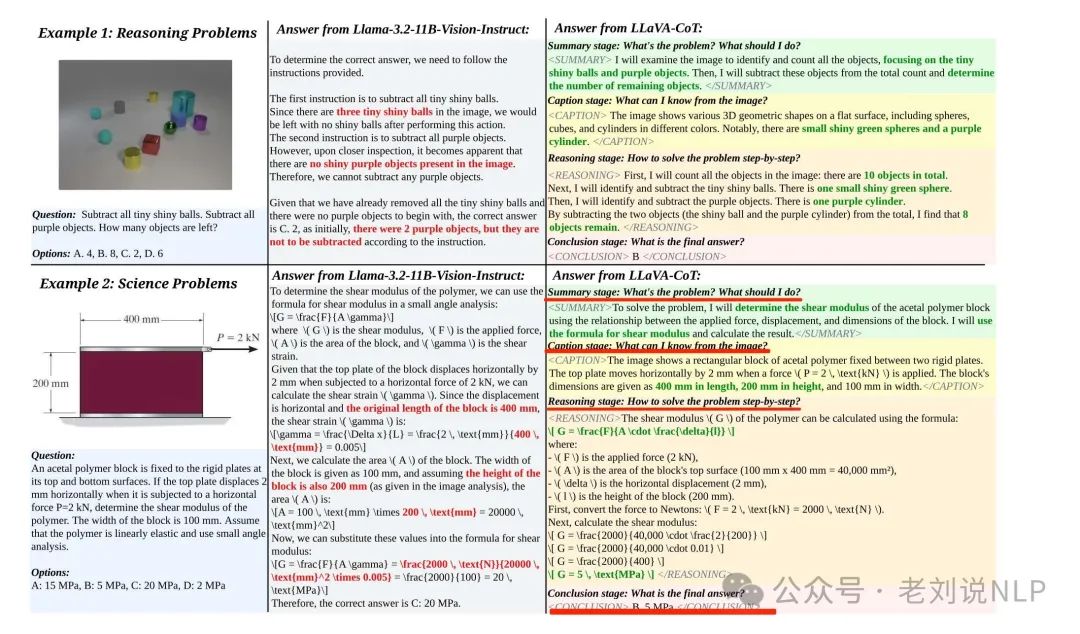
2、Llama-V-o1
Llama-V-o1(《LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs》,https://arxiv.org/abs/2501.06186,https://mbzuai-oryx.github.io/LlamaV-o1/,https://huggingface.co/omkarthawakar/LlamaV-o1,https://github.com/mbzuai-oryx/LlamaV-o1,https://huggingface.co/datasets/omkarthawakar/VRC-Bench),设计了一个评估多步推理任务的基准测试,涵盖八个不同类别(视觉推理、数学与逻辑推理、社会与文化背景、医学影像、图表与图表理解、OCR与文档理解、复杂视觉感知和科学推理),包含超过1000个具有挑战性的样本和超过4173个手动验证的推理步骤,提出了一种新的多模态推理模型,名为LlamaV-o1,采用多步课程学习方法和束搜索技术进行训练。训练过程分为两个阶段:
第一阶段中,训练模型生成方法和问题摘要以及输入数据的详细字幕。使用PixMo数据集的Cap-QA分割和Geo170K数据集进行训练。在这个阶段,模型被训练以生成方法和问题摘要以及输入数据的详细字幕。具体使用的数据集包括PixMo数据集的Cap-QA分割和Geo170K数据集。PixMo数据集的Cap-QA分割包含基于输入问题的grounded captions,而Geo170K数据集包含问题-答案对及其推理步骤。这个阶段的训练目标是帮助模型学会如何组织思维并概述高层次的推理计划,从而为后续的详细推理打下基础;
第二阶段中,训练模型生成详细的推理和最终答案。使用原始的Llava-CoT数据集进行训练。
在推理过程中,LlamaV-o1采用束搜索技术生成多个推理路径,并选择最优路径。在这个阶段,模型被训练以生成详细的推理和最终答案。使用的数据集是原始的Llava-CoT数据集,该数据集包含99K个结构化样本,涵盖多个领域如一般视觉问答和科学目标视觉问答。这个阶段的训练目标是让模型在第一阶段的基础上,进一步细化其逻辑流程,并将摘要和字幕中的信息整合为可操作的推理步骤,最终生成正确的答案。
通过这两个阶段的课程学习训练,LlamaV-o1模型逐步掌握了从简单任务到复杂多步推理任务所需的技能和知识。
3、MAMmoTH-VL
MAMmoTH-VL(《MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale》,https://github.com/MAmmoTH-VL/MAmmoTH-VL,https://arxiv.org/pdf/2412.05237),从153个公开的多模态指令数据集中系统地收集和分类数据,覆盖广泛的实际应用场景。根据MLLM训练范式和常见的下游任务,将训练数据重新组织为十个主要类别,实施任务感知的重写过程,以解决缺乏详细中间推理步骤,使用“模型作为裁判”的方法来过滤数据,确保重写的指令-响应对与图像内容一致,减少幻觉。共包含1200万条指令-响应对的数据集,涵盖多样化的推理密集型任务。

模型训练上,使用Qwen2.5-7B-Instruct作为LLM骨干,Siglip-so400m-patch14-384作为视觉塔,两层MLP作为投影器,训练阶段分为语言-图像对齐、单图像指令微调和多模态指令微调三个阶段,但是这种方案依赖于直接模仿策划的真实答案,使模型不经过试错过程直接生成响应。
因此,这些模型可能无法在其训练分布之外进行泛化。
三、R1-Onevision通过图像形式化+SFT+RL实现思路
我们先看R1-Onevision,《R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization》的技术报告出来了,在https://arxiv.org/pdf/2503.10615,github地址在https://github.com/Fancy-MLLM/R1-onevision有更多技术细节,感兴趣的可以追一追。
核心在于推出跨模态推理流程,将图像转换为形式化的文本描述,使语言模型能够精确地处理和推理图像,包括数据收集和过滤、图像形式化描述、推理过程生成和质量保证。
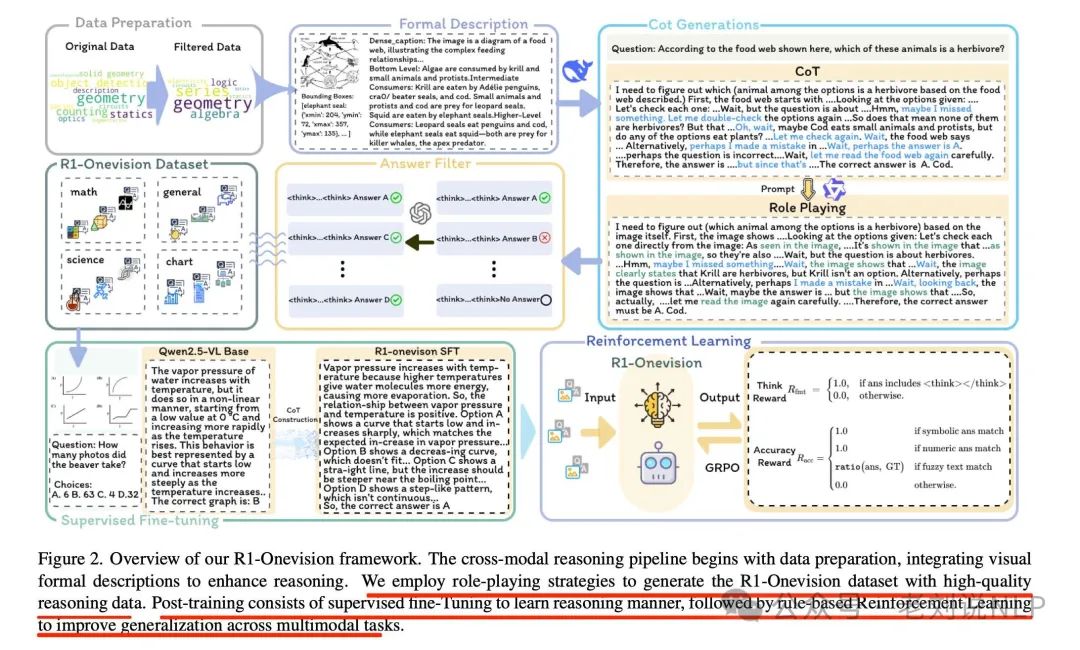
数据收集和过滤方面,收集了包括自然图像、OCR文本提取、图表、数学表达式和科学推理问题在内的多样化多模态数据集,选择支持结构化推理的数据。
图像形式化描述方面,使用GPT-4o、GroundingDINO和EasyOCR将视觉图像内容转换为文本形式描述。具体方法包括:
1)对于图表和图表, 使用GPT-4o生成结构化表示,如SPICE用于电路图,PlantUML或Mermaid.js用于流程图,HTML用于UI布局,CSV/JSON用于表格,Matplotlib用于注释图表。
2)对于自然场景,使用GroundingDINO提取关键元素的边界框注释,并使用GPT-4o生成描述性标题。
3)对于仅包含文本的图像,使用EasyOCR提取文本及其位置,并使用GPT-4o重建原始文档。
4)对于包含视觉和文本内容的图像,整合GPT-4o生成的标题、GroundingDINO边界框和EasyOCR提取的文本,确保文本和视觉元素都被准确捕捉。
5)对于数学图像,即对于包含数学内容的图像,使用GPT-4o提出推理策略以指导推理过程。
推理过程生成方面,就是和文本推理模型一样的做法了,进行推理过程生成,给定一张图像,提示语言推理模型及其密集标题和问题,构建跨模态Chain-of-Thought(CoT)数据,也就是如下的prompt:

单数虽然原始的思维链(CoT)方法基于文本标题提供了一种结构化的推理路径,但它本质上缺乏必要的视觉组件,直接“看到”并解释图像的能力。为了解决这一限制,采用一种角色扮演策略,模拟类似人类的视觉理解,该方法涉及迭代性地重新审视图像,重新精炼理解,并提高推理过程的保真度,这一过程提升了多模态一致性,并确保上下文丰富的推理过程。也就是上面的prompt.
质量保证方面,使用GPT-4o移除不准确、无关或不一致的CoT步骤,确保生成的高质量数据集。
在训练方面,为了提升多模态推理能力,引入了一个两阶段的训练后策略,包括监督微调(SFT)和基于规则的强化学习(RL)。SFT稳定模型的推理过程并规范了其输出格式。
数据R1-OneVision包含15.5万条数据,涵盖科学、数学、一般知识和文档/图表/屏幕内容。
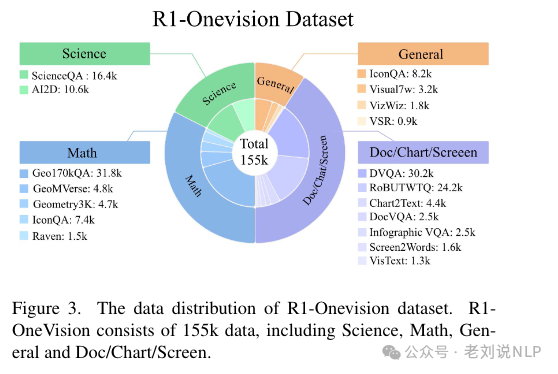
RL进一步提高了跨多种多模态任务的泛化能力,在SFT训练模型的基础上,采用基于规则的强化学习(RL)来优化结构化推理并确保输出的有效性。
奖励函数包括准确性奖励和格式奖励,准确性奖励规则通过使用正则表达式提取最终答案,并将其与真实情况对照来评估最终答案的正确性。对于确定性任务,如数学问题,以指定的格式(例如,放在一个框内)提供最终答案,以便进行可靠的基于规则的验证,如对象检测之类的情况下,奖励由与真实情况的交并比(IoU)分数决定。格式奖励规则要求响应必须遵循严格的格式,其中模型的推理被包含在和之间。正则表达式确保这些推理标记的存在和正确排序。
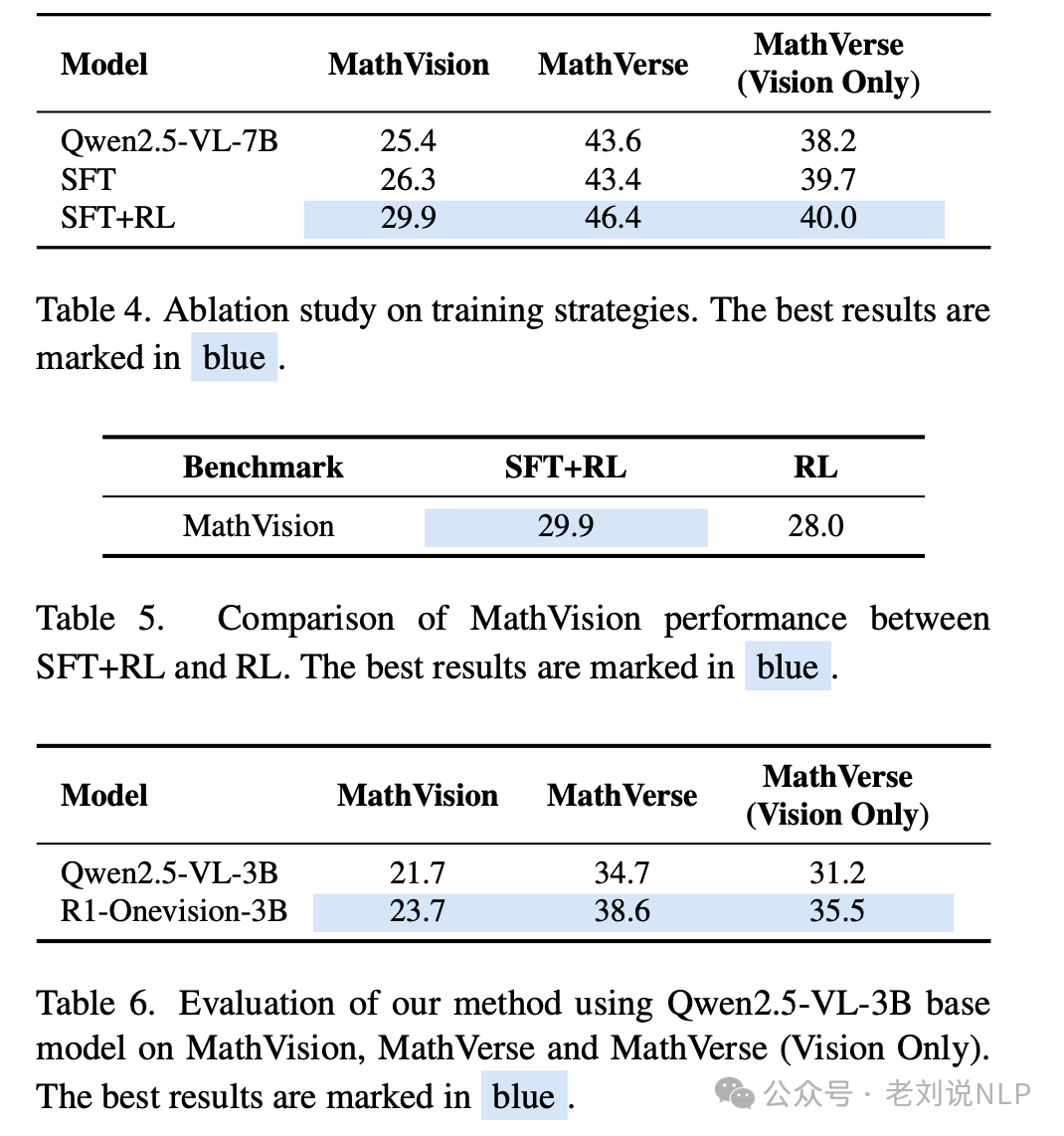
强化学习方面采用GRPO,基础模型选用Qwen2.5VL-3B模型。
当然,这个工作也进一步说明了SFT+RL的互补性质。在SFT之后应用强化学习(RL)带来了额外的性能提升,这一步推动模型向更深层次和演绎性更强的思维发展,使其能够处理更加复杂和微妙的问题,SFT通过与高质量推理模式对齐,为模型建立了坚实的基础;RL则通过鼓励更高级的认知过程来精炼和提升这些能。
三、LMM-R1通过两阶段规则型强化学习思路
工作《LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL》(https://arxiv.org/pdf/2503.07536,https://github.com/TideDra/lmm-r1),通过两阶段规则强化学习(RL)增强大型多模态模型(LMMs)的推理能力,用于通过基础推理增强(FRE) 和多模态泛化训练(MGT) 来增强LMMs的多模态推理能力。
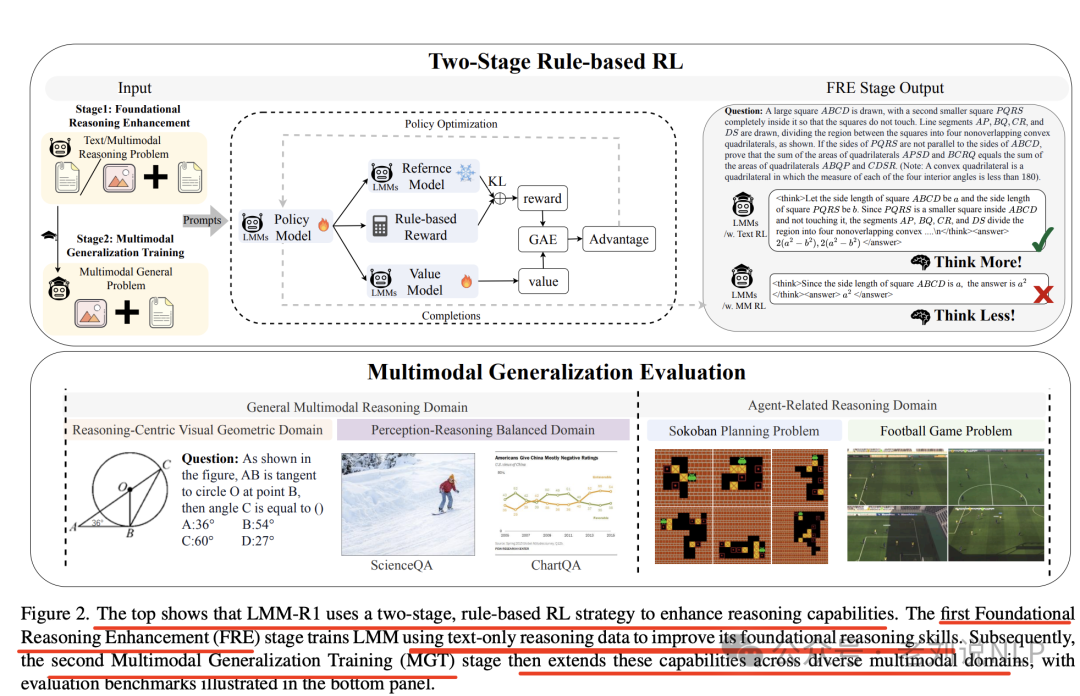
区别的是,这里的强化学习,使用Proximal Policy Optimization(PPO)算法训练LMMs,奖励函数包括格式奖励和准确性奖励,不是使用GRPO。
1)基础推理增强(FRE)
首先,使用高质量的文本数据进行基于规则的强化学习,以增强模型的基础推理能力,这里数据采用使用DeepScaler-Preview数据集和Verifiable Multimodal-65K数据集,这类包括两个子方法:
文本推理增强阶段,利用大规模且高质量的文本推理问题进行训练,这些问题的推理过程比现有的多模态推理任务更具挑战性;
多模态推理增强阶段,使用可验证的多模态数据进行基于规则的强化学习训练,尽管这些数据的质量较低,但可以提供更直接的多模态领域接触;
2)多模态泛化训练(MGT)
在基础推理能力增强后,继续在不同复杂的多模态推理任务上进行基于规则的强化学习训练,以泛化推理能力。
这块使用VerMulti-Geo数据集、Perception-Reasoning Balanced数据集和随机生成的Sokoban环境。
涉及两个领域:一般多模态推理领域,包括几何推理、科学推理等任务,评估模型在不同多模态场景下的推理能力。代理相关推理领域,包括Sokoban和足球任务,评估模型在复杂视觉环境中的代理能力。
说下最终结论,与传统的监督学习(SFT)方法相比,基于规则的强化学习(RL)减少灾难性遗忘,更有效地将推理能力转移到其他领域,直接使用文本数据进行RL训练相比于SFT方法在基线模型上导致了显著的性能下降。
具体的,在文本推理基准测试中,FRE-Text模型在MATH500和GPQA上分别提高了2.0%和6.57%,整体提升了4.29%。
在多模态基准测试中,FRE-Multi在MathVista和MM-Star上分别提高了3.5%和7.36%,而FRE-Text在OlympiadBench、MathVision和MathVerse上分别提高了5.34%、2.17%和4.19%。在几何领域,MGT-Geo在多模态基准测试中提高了3.21%。
在感知-推理平衡领域,MGT-PerceReason在多模态基准测试中平均提高了1.6%。在Sokoban全局设置中,MGT-Sokoban比基线模型提高了5.56%。
参考文献
本文主要介绍了RL之前以及之后的多模态推理的两个工作,一个是R1-Onevision通过图像形式化+SFT+RL实现思路,一个是LMM-R1通过两阶段规则型强化学习提高泛化性。
github以及论文原文都给出了,可以再仔细研究。
参考文献
1、https://arxiv.org/pdf/2503.10615
2、https://arxiv.org/pdf/2503.07536
3、https://arxiv.org/pdf/2411.10440
4、https://arxiv.org/abs/2501.06186
5、https://arxiv.org/pdf/2412.05237
(文:老刘说NLP)