

DeepSeek R1 发布已经两周了,而我们启动 open-r1 项目——试图补齐它缺失的训练流程和合成数据——也才过了一周。这篇文章简单聊聊:
-
Open-R1 在模仿 DeepSeek-R1 流程和数据方面的进展 -
我们对 DeepSeek-R1 的认识和相关讨论 -
DeepSeek-R1 发布后社区搞出来的有趣项目
这既是项目的最新动态,也是一些关于 DeepSeek-R1 的有趣资料合集。
一周后的进展
先来看看 Open-R1 这周干了啥。我们一周前才开始这个项目,经过团队和社区的小伙伴们一起努力,已经有点成果可以分享了。
评估
要模仿人家,第一步得确认我们能不能复现 DeepSeek 的成绩。我们在 MATH-500 基准测试上试了试,果然能跟 DeepSeek 公布的数据对上号:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
想知道怎么测的?去
我们还发现,DeepSeek 模型生成的回答特别长,评估起来都费劲。在 OpenThoughts 数据集里,DeepSeek-R1 的回答平均有 6000 个 token,有些甚至超过 20000 个 token。啥概念呢?一页书大概 500 个单词,一个单词可能由 1 个及以上的 token 组成,所以很多回答能写满 10 多页!(来源:
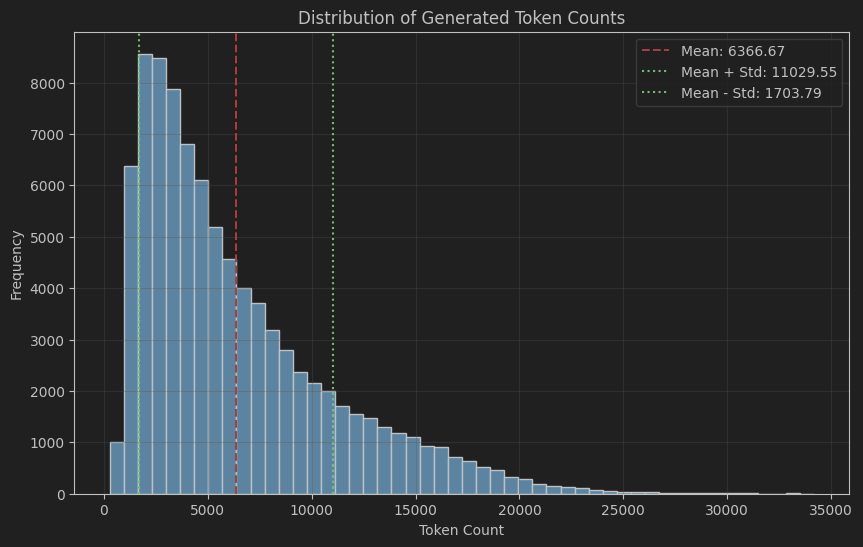
回答这么长,给后面用 GPRO 训练带来了很大的挑战。想要生成超长内容,需要很多的 GPU 显存来存储梯度和激活值。
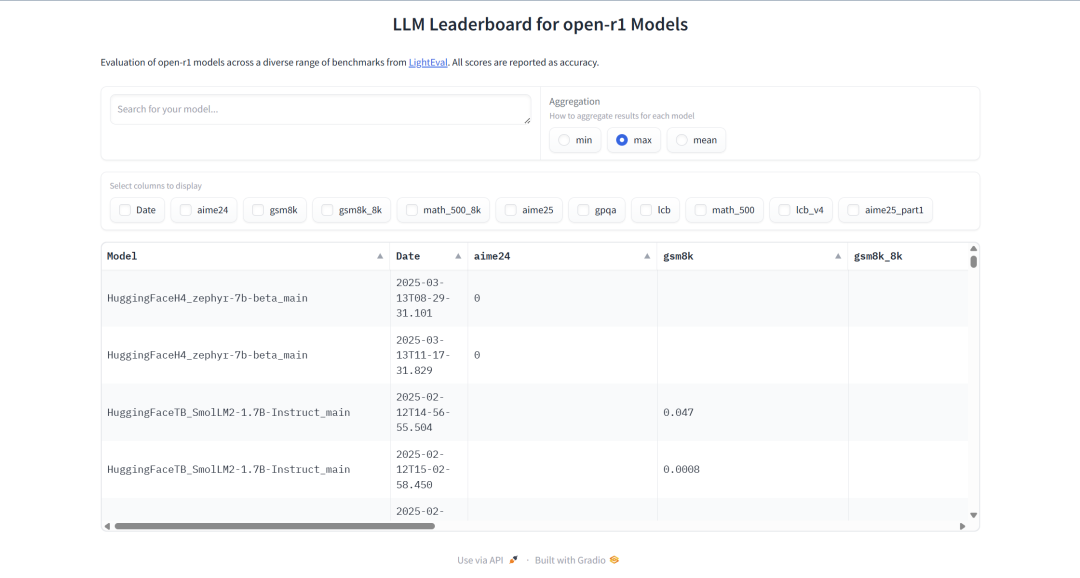
为了让大家都能看到进展,我们搞了个 open-r1 评估排行榜,社区可以在这里随时关注我们的复现情况:
训练流程
Open R1 发布后,GRPO (分组相对策略优化) 被集成到了最新版 TRL (
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# 简单奖励: 回答接近 20 个字符的给高分
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()
不过现在内存用量还是有点高,我们正在想办法优化。
合成数据生成
R1 报告里最让人兴奋的是,主模型能生成合成推理过程,小模型用这些数据微调后效果也能跟主模型差不多。所以我们也想能够复现这个合成推理数据集,让大家都能拿去调模型。
R1 这种大模型,难点在于怎么高效快速地生成数据。我们试了一周,调了各种配置。
一开始用两个 8xH100 节点跑模型,用 vLLM 当推理服务器。但效果不好,吞吐量低,只能同时处理 8 个请求,GPU 的 KV 缓存很快就满了。缓存一满,请求就被打断,如果设置了 PreemptionMode.RECOMPUTE ,就得等显存空出来再重跑。
后来我们换成 4 个 8xH100 节点,总共 32 个 GPU。这样显存够用,能同时跑 32 个请求,几乎不会因为缓存满而重新排队。
一开始我们批量发请求给 vLLM,但发现批量里慢的会拖后腿,GPU 利用率忽高忽低。新一批次得等上一批全跑完才开始。后来改成流式处理,GPU 利用率稳定多了:
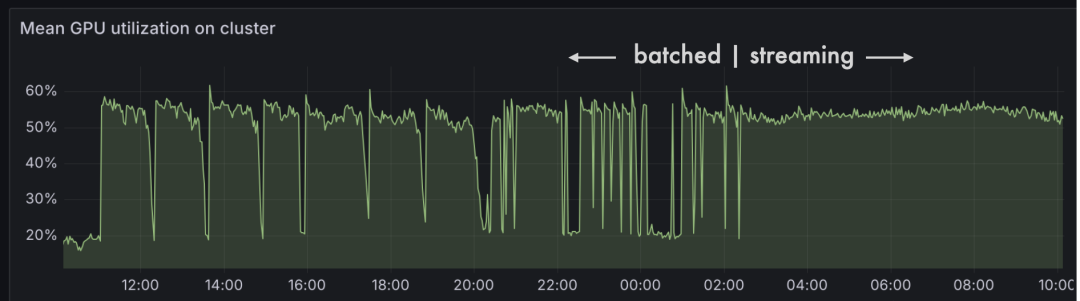
改代码也不难。原来的批量推理代码是:
# 每批 500 个请求
for batch in batch_generator(dataset, bs=500):
active_tasks = []
for row in batch:
task = asyncio.create_task(send_requests(row))
active_tasks.add(task)
if active_tasks:
await asyncio.gather(*active_tasks)
现在流式处理的代码是:
active_tasks = []
for row in dataset:
# 活跃请求控制在 500 个以下
while len(active_tasks) >= 500:
done, active_tasks = await asyncio.wait(
active_tasks,
return_when=asyncio.FIRST_COMPLETED
)
task = asyncio.create_task(send_requests(row))
active_tasks.add(task)
# 等所有任务跑完
if active_tasks:
await asyncio.gather(*active_tasks)
现在生成速度挺稳定,但我们还在琢磨,比如长请求被打断时,换用 CPU 缓存会不会更好。
想看现在的推理代码?参见
推广
open-r1 火了,连媒体都关注,过去一周团队成员频频上新闻:
-
Lewis 在 CNN 直播了! https://x.com/_lewtun/status/1884377909038833894?s=46 -
Thom 上彭博社: https://x.com/Thom_Wolf/status/1884353433865777520 -
Leandro 在 NPR《金钱星球》聊了会 (21 分钟左右): https://www.npr.org/2024/11/29/1215793948/deepseek-ai-china-us-semiconductors-stock-nvidia
还有一堆报道:
-
华盛顿邮报 https://www.washingtonpost.com/technology/2025/01/28/deepseek-ai-china-us-trump/ -
金融时报 https://www.msn.com/en-gb/technology/artificial-intelligence/china-s-emboldened-ai-industry-releases-flurry-of-model-updates/ar-AA1xZbTE?ocid=BingNewsVerp -
金融时报 https://www.ft.com/content/757950e1-a81d-4c66-983e-1cf333262d66 -
财富 https://www.msn.com/en-us/technology/artificial-intelligence/deepseek-isn-t-china-s-only-new-ai-model-and-analysts-are-calling-the-flurry-of-new-applications-a-coordinated-psyops/ar-AA1xZqi4?ocid=BingNewsVerp -
财富 https://fortune.com/2025/01/27/deepseek-just-flipped-the-ai-script-in-favor-of-open-source-and-the-irony-for-openai-and-anthropic-is-brutal/ -
The Verge https://www.theverge.com/ai-artificial-intelligence/598846/deepseek-big-tech-ai-industry-nvidia-impac -
金融评论 https://www.afr.com/technology/why-the-deepseek-breakthrough-is-actually-a-good-thing-20250128-p5l7pn -
Tech Crunch https://techcrunch.com/2025/01/28/hugging-face-researchers-are-trying-to-build-a-more-open-version-of-deepseeks-ai-reasoning-model/ -
时代周报 https://www.zeit.de/digital/internet/2025-01/deepseek-kuenstliche-intelligenz-startup-china-sprachmodell/seite-2 -
金融时报 https://www.ft.com/content/ea803121-196f-4c61-ab70-93b38043836e -
纽约时报 https://www.nytimes.com/2025/01/29/technology/deepseek-ai-startups-venture-capital.html -
华尔街日报 https://www.wsj.com/articles/how-deepseeks-ai-stacks-up-against-openais-model-e938c3d6 -
欧洲新闻 https://uk.news.yahoo.com/deepseek-wake-call-europe-ai-150850807.html -
巴伦周刊 https://www.barrons.com/news/behind-ai-makers-claims-to-share-open-source-models-8e8b8b8a -
纽约时报 https://www.nytimes.com/2025/01/29/technology/meta-deepseek-ai-open-source.html -
Vox https://www.vox.com/technology/397330/deepseek-openai-chatgpt-gemini-nvidia-china -
自然 https://www.nature.com/articles/d41586-025-00259-0 -
瑞士资讯 https://www.swissinfo.ch/eng/science/switzerland-caught-in-middle-of-us-china-race-for-ai-dominance/88804566 -
商报 https://www.handelsblatt.com/technik/ki/kuenstliche-intelligenz-durchbruch-oder-hype-so-innovativ-ist-deepseek/100094406.html -
商业内幕 https://www.businessinsider.com/deepseek-r1-open-source-replicate-ai-west-china-hugging-face-2025-1 -
IEEE Spectrum https://spectrum.ieee.org/deepseek -
MIT 技术评论 https://www.technologyreview.com/2025/01/31/1110740/how-deepseek-ripped-up-the-ai-playbook-and-why-everyones-going-to-follow-it/ -
世界报 https://www.lemonde.fr/en/opinion/article/2025/01/31/behind-deepseek-and-the-paris-summit-lies-the-challenge-of-open-and-economical-artificial-intelligence_6737615_23.html
DeepSeek-R1 给我们带来了什么启发?
虽然大家还在研究 DeepSeek-R1 的成果和报告,但这款模型在发布短短两周后,就已经火遍了大街小巷,吸引了无数目光。
R1 引发了哪些反响?
发布后的第一周还算风平浪静,但到了第二周,市场突然热闹起来,各大 AI 研究机构纷纷发表看法:
-
股市周一有点慌乱,但后面几天稳住了,甚至还有所回升: 链接 https://x.com/KobeissiLetter/status/1883831022149927352 -
OpenAI 的老板 Sam Altman 给 DeepSeek 点了赞,还透露他们会加快脚步,很快推出一些新东西: https://x.com/sama/status/1884066337103962416 -
OpenAI 的研究大牛 Mark Chen 说,DeepSeek 的思路跟他们 o1 的想法不谋而合: https://x.com/markchen90/status/1884303237186216272 -
Anthropic 的老板 Dario Amodei 借机强调出口限制,勾勒出一个要么两强争霸 -
要么一家独大的未来: https://x.com/DarioAmodei/status/1884636410839535967
与此同时,不少公司也忙着把 DeepSeek 模型塞进各种平台 (以下只是部分例子):
-
Dell: 联手 Hugging Face,Dell 的创始人兼老板 Michael Dell 推出了一套本地运行 DeepSeek-R1 的方案: https://x.com/MichaelDell/status/1884677233014398994 -
AWS: 亚马逊的老大 Andy Jassy 宣布 DeepSeek-R1 已经能在 Amazon BedRock 和 SageMaker 上玩起来了: https://x.com/ajassy/status/1885120938813120549 -
Hyperbolic AI: https://hyperbolic.xyz/blog/deepseek-r1-now-hosted-on-hyperbolic -
Together AI: https://x.com/togethercompute/status/1882110120274088278 -
Fireworks AI: https://fireworks.ai/models/fireworks/deepseek-r1
DeepSeek V3 的训练成本有多夸张?
大家对 V3 和 R1 的训练费用特别好奇。虽然具体数字可能没那么关键,但很多人还是拿计算器粗略估了估,结果发现这些数字大体靠谱。看看这些讨论就知道了:
-
马里兰大学的 Tom Goldstein 教授: https://x.com/tomgoldsteincs/status/1884651376854122774 -
MatX 的创始人 Reiner Pope 把 Llama3 和 DeepSeek V3 摆在一起比了比: https://x.com/reinerpope/status/1884056274893168896 -
OpenAI 前员工 Lukas Beyer (曾混迹 Google Brain 和 DeepMind),聊了聊 MFU 的来头: https://x.com/giffmana/status/1884160434846224688 -
SemiAnalysis 还搞了份报告,猜想 DeepSeek 背后有哪些硬件支持: https://x.com/SemiAnalysis_/status/1885192148037112023
不少团队正在努力复现训练过程,估计很快就能知道这个模型的训练效率到底有多牛。
训练数据那些事儿
上周有人猜想 DeepSeek 可能偷偷用了 OpenAI 的数据来训练自己的模型,比如《金融时报》就报道了这事儿。不过现在还不确定这些说法会闹出什么结果。
开源社区也很热闹
围绕 DeepSeek-R1,开源社区简直火爆得不行,好多人都在基于这个模型搞出各种有意思的项目。
有哪些好玩的项目?
有些项目试着以较小的规模复制基本的学习机制,让你自己在家就能试试:
-
Will Brown 就展示了一个方法,用TRL 里的 GRPO 训练器和 Llama 1B 模型,弄出一个简单的学习曲线。https://x.com/willccbb/status/1883414339518148960 https://hf.co/docs/trl/main/en/grpo_trainer -
TinyZero 更牛,花不到 30 美元,用一个 3B 的基础模型,就能让你自己体验到那种“哦,原来是这样!” 的瞬间。https://github.com/Jiayi-Pan/TinyZero https://x.com/jiayi_pirate/status/1882839370505621655 -
Philipp Schmid 还写了个 Mini-R1 教程 ,手把手教你怎么找到那个“顿悟”时刻。https://www.philschmid.de/mini-deepseek-r1 -
香港科技大学的研究员们尝试了更大的模型,他们在一篇 博客里 讲了怎么用 7B 的数学模型搞出推理能力。https://hkust-nlp.notion.site/simplerl-reason -
Evolving LLM 实验室的人已经开始折腾 R1 的多模态版本了,地址在这儿: https://github.com/EvolvingLMMs-Lab/open-r1-multimodal -
Stepanov 则用 R1 从文本里提取图表,教程在这儿: https://hf.co/blog/Ihor/replicating-deepseek-r1-for-information-extraction

TinyZero 的结果,模型的推理能力变强了
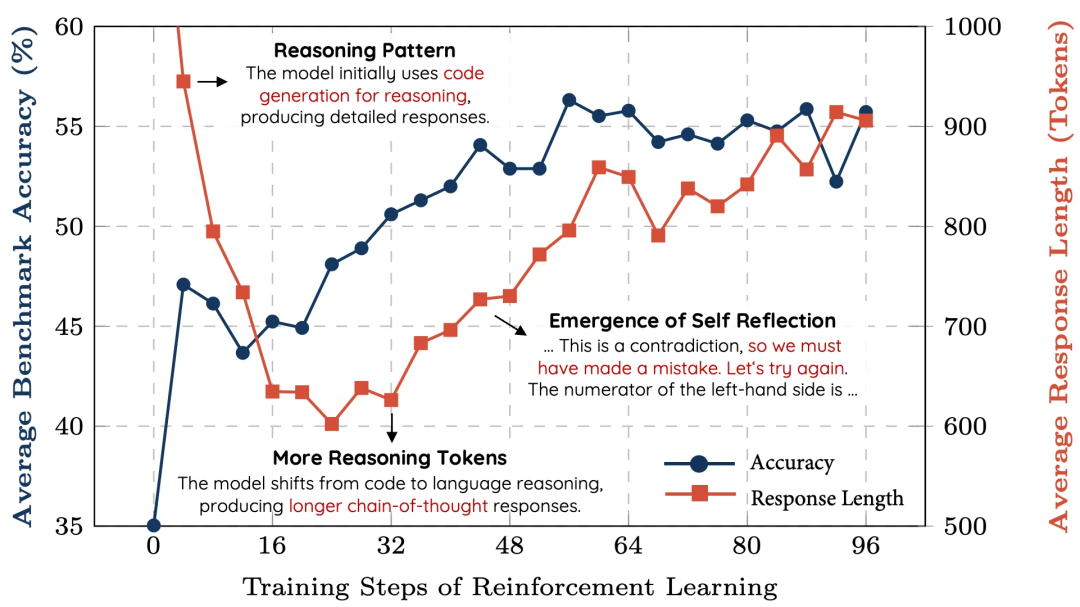
香港科大的图表,随着训练越久,模型的推理过程越长
数据集也忙得不亦乐乎
社区里好多人都在忙着搞 R1 相关的数据集,亮点有这些:
-
bespokelabs/Bespoke-Stratos-17k : 模仿Berkeley Sky-T1 的数据流程,用 DeepSeek-R1 创建出一堆问题https://hf.co/datasets/bespokelabs/Bespoke-Stratos-17k https://novasky-ai.github.io/posts/sky-t1/ -
推理过程和答案,然后拿去微调 7B 和 32B 的 Qwen 模型。 -
open-thoughts/OpenThoughts-114k : 一个超棒的合成推理数据集,有 114k 个例子,数学、科学、代码、谜题啥都有。Open Thoughts 工作的一部分https://hf.co/datasets/open-thoughts/OpenThoughts-114k -
cognitivecomputations/dolphin-r1 : 80 万样本的大集合,混了 DeepSeek-R1https://hf.co/datasets/cognitivecomputations/dolphin-r1 -
Gemini flash 还有 Dolphin 聊天的 20 万样本,想帮着训练 R1 那样的模型。 -
ServiceNow-AI/R1-Distill-SFT : 现在有 1.7 万样本,ServiceNow 的语言模型团队做的,用于支持 Open-R1 计划。https://hf.co/datasets/ServiceNow-AI/R1-Distill-SFT -
NovaSky-AI/Sky-T1_data_17k : 用来训练 Sky-T1-32B-Preview 的数据,花不到 450 美元就搞定,详情看这篇博客 。https://hf.co/datasets/NovaSky-AI/Sky-T1_data_17k https://novasky-ai.github.io/posts/sky-t1/ -
Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B : 扩展了Magpie 的方法,生成带推理的指令数据,挺有意思。https://hf.co/datasets/Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B https://hf.co/papers/2406.08464
此列表仅涵盖 Hub 上的少量推理和问题解决相关数据集。我们期待可以看到社区在未来几周内能够构建其他哪些数据集。
下一步干啥?
我们这才刚起步呢,打算把训练流程弄完,在小模型上试试,再用放大版的推理流程搞出高质量的数据集。想帮忙的话,去 GitHub 上看
-
open-r1 仓库 https://github.com/huggingface/open-r1 -
open-r1 组织 https://hf.co/open-r1
英文原文:
https://hf.co/blog/open-r1/update-1 原文作者: Leandro von Werra, Lewis Tunstall, Quentin Gallouédec, Guilherme Penedo, Edward Beeching, Anton Lozhkov, Brigitte Tousignant, Daniel van Strien
译者: yaoqih
(文:Hugging Face)