

极市导读
中山大学联合上海人工智能实验室提出了LOKI,这是一个面向多模态合成数据检测的全新测试基准,涵盖图像、视频、3D、文本、音频等模态,旨在系统评估大模型在合成数据检测任务中的能力与局限,相关成果已被ICLR 2025接收为Spotlight论文。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近年来,AI生成内容(AIGC)快速发展,从逼真的图像、视频到深度伪造音频,AI合成数据已广泛渗透到媒体、娱乐、教育等多个领域。然而,这一技术的滥用也引发了深刻的安全隐患,如何精准识别这些合成数据成为当前的重要挑战。
中山大学联合上海人工智能实验室提出了LOKI,一种面向多模态合成数据检测的全新测试基准。LOKI涵盖了图像、视频、3D、文本、音频等多个模态,构建了丰富的任务类型与异常注释体系,可系统评估大模型在合成数据检测任务中的能力与局限。该成果已被 ICLR 2025(Spotlight)接收。
-
论文题目:LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models -
论文链接: https://arxiv.org/pdf/2410.09732 -
项目主页: https://opendatalab.github.io/LOKI/ -
数据&代码:https://github.com/opendatalab/LOKI

LOKI的亮点:
-
全面模态评估:LOKI涵盖了图像、视频、3D、文本、音频五大模态,收集了近期热门合成模型生成的高质量多模态数据,全面挑战LMM在多模态数据场景下的识别能力。 -
异构数据覆盖:数据集中包含28个细致分类,覆盖卫星、医学等专业图像,以及哲学、文言文等文本,极具挑战性。 -
多层次标注体系:LOKI的题目设置覆盖了基础的真假判断题、多项选择题、异常细节选择题、异常解释题等,支持从基础到复杂任务的全面测试。 -
多模态检测框架:LOKI支持主流多模态模型(如GPT-4o、Claude-3、LLaVA等)使用多种数据格式输入,涵盖视频、图像、文本、音频、点云等,全面评估LMM在复杂数据环境下的泛化能力。
研究动机
随着扩散模型和大型语言模型(LLM)的快速发展,人工智能生成内容(AIGC)技术已被广泛应用于图像、视频、音频、文本等多种数据类型。
例如,SORA可合成高度逼真的视频,Suno能够创作出与专业音乐家相媲美的音乐作品。然而,AI合成数据的泛滥也带来了诸多风险,包括虚假信息传播、诈骗、甚至互联网训练数据污染等问题,严重影响了内容的可信度和真实性。
尽管合成数据检测领域近年来取得了一定进展,但大多数现有方法主要侧重于判断数据的真实性,缺乏对模型判断过程的解释,难以应对更复杂的多模态合成场景。
多模态大模型(LMM)的快速发展为合成数据检测提供了新思路,LMM不仅能够通过自然语言提供推理过程,还展现出了对更复杂、多样化数据的泛化能力。
基于此,研究团队提出了LOKI基准,以系统化评估LMM在合成数据检测中的性能,为更安全、可信的AI应用提供支持。

LOKI基准构建
多模态数据覆盖
LOKI基准涵盖了五大核心数据模态,以确保在多样化场景下全面测试LMM在合成数据检测中的性能。
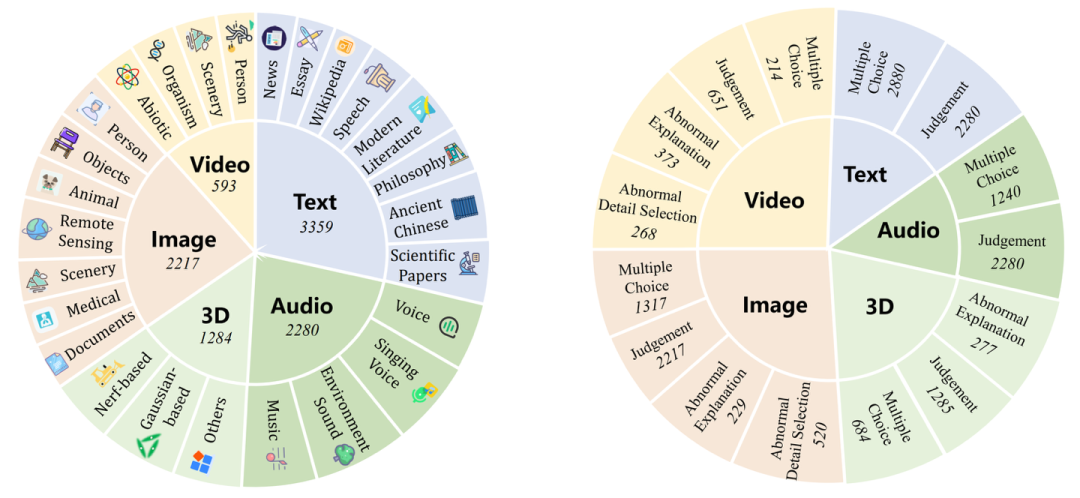
图像:收集了来自FLUX、MidJourney、Stable Diffusion等模型生成的2,200余幅图像,涵盖人像、风景、物品等类型。图像数据不仅提供了整体真伪标签,还通过细粒度标注对异常区域和特征进行了标记,以帮助模型识别细节差异及局部特征异常。
视频:LOKI基准的视频数据来源于SORA、Keling、Open_sora等闭源与开源模型,共收集500余个文本生成视频片段及其真实样本。每个视频样本标注了异常片段、异常关键帧及异常描述。例如,异常类型可能包括“帧闪烁”或“违反自然物理规律”等复杂情况,充分测试模型对时序数据中的异常模式感知能力。
3D模型:LOKI基准整合了超过1,200个3D模型样本,基于OmniObject3D进行了分析。数据包括多个领域的3D模型,涵盖建筑、家具、物品等类别,并配有纹理异常和整体异常标注。每个3D模型样本还提供了多视角的RGB图像,帮助模型更全面地感知3D结构及异常特征。
音频:音频数据涵盖语音、歌声、环境音、音乐等多种类型,数据来源于ASVSpoof2019、CtrSVDD Benchmark、DCASE 2023 Task 7等数据集。音频样本包含非自然音调、音轨断裂、环境声失真等异常特征,并且在标注中对每个样本的异常类型及来源进行了详细说明,提升模型在音频数据异常检测中的表现。
文本:文本数据来自GPT-4、Qwen-Max、LLaMA等模型生成,使用了总结再生方法生成与原始文本相似的伪造文本。文本样本涉及新闻、文学、对话等类型,共计3,359篇,并根据长度和语言进行分类。文本数据包含干扰信息、风格不匹配等异常特征,以全面测试LMM对文本数据合成特征的识别能力。
细粒度标注机制
LOKI基准引入了多层次的细粒度标注体系,每个数据样本都附带真实/合成标签,并标注了更精细的异常细节,确保模型在识别异常特征时具备更强的可解释性。此外,数据样本还附带了对应的推理题目,以考察LMM在判断异常原因和分析合成痕迹方面的推理能力。
多样化任务类型
-
判断题:判定输入数据是真实还是合成。 -
多选题:从合成和真实数据中正确选择 AI 生成的数据或真实数据。 -
异常细节选择题:定位并指出合成数据的异常区域; -
异常解释题:要求模型解释合成数据的生成原理和异常特征。

LMMs评估结果
本研究一共评估了22个开源LMMs、6个闭源LMMs和几个专家合成检测模型。LOKI基准中各类模型在判断、选择题及异常解释任务上的表现结果显示,GPT-4o在合成数据判断任务中表现最佳,总体准确率(不包括音频)达到63.9%。在多项选择题中,GPT-4o的表现进一步提升,准确率达到73.7%。
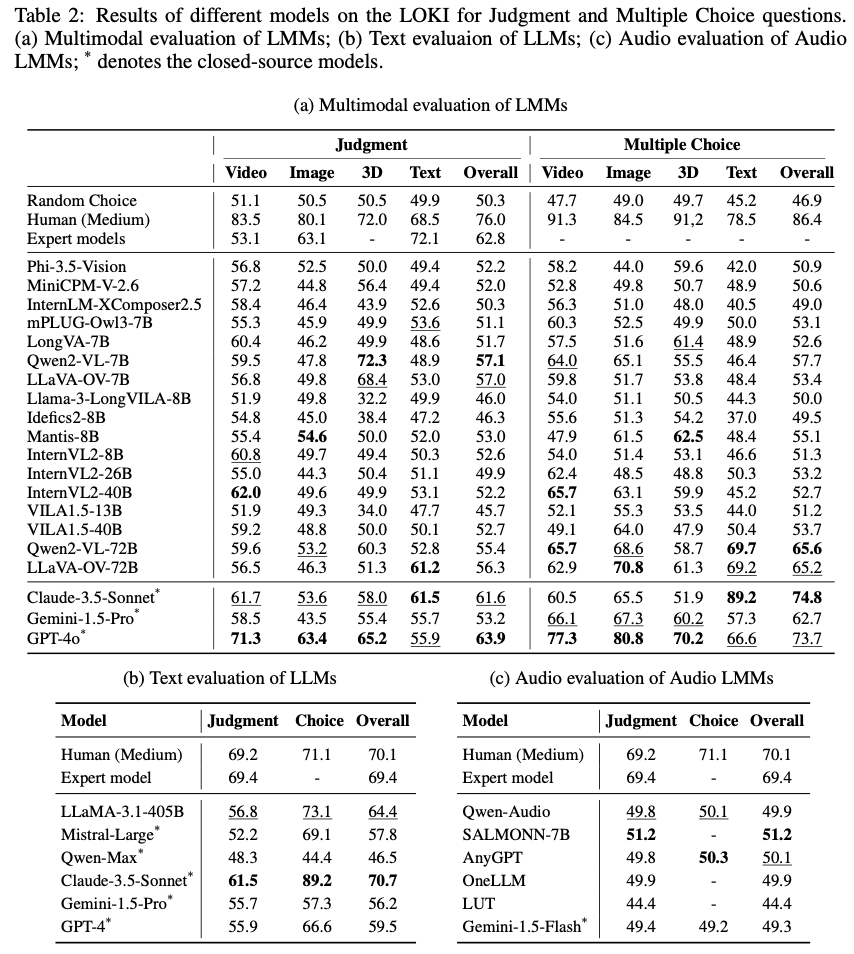
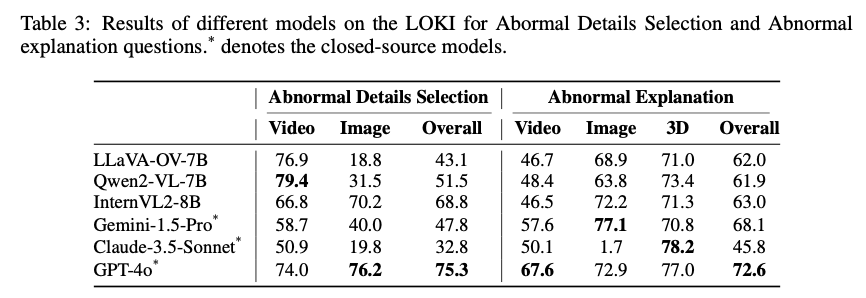
在文本模态中,Claude-3.5的表现优于其他LMM和LLM,准确率超过70%,在对长文本的判断中尤为突出,展现出更强的文本理解和分析能力。
与之相比,GPT-4o在文本任务中更擅长短文本的异常检测,表现出不同模型在文本类型上的差异。在音频模态中,无论是开源模型还是闭源模型,表现均接近于随机选择,显示出当前LMM在音频合成数据检测上的显著局限。
尤其在环境音、复杂音效场景中,模型的准确率明显下降,提示未来音频检测方法仍需优化。
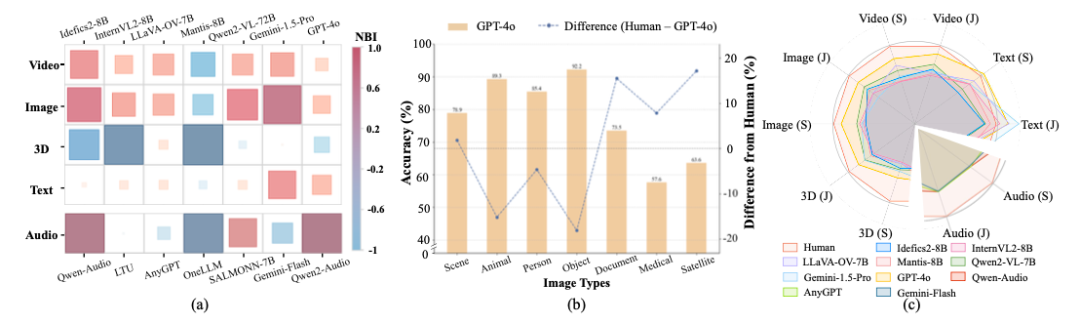
模型偏差分析
LOKI基准揭示了LMM在合成数据检测中的显著偏差。实验结果表明,大多数模型在判断数据真实性时存在系统性倾向。例如,GPT-4o更易将文本数据误判为真实,而在3D数据中则倾向于判断为AI生成。尽管采用了多种提示优化(如Chain-of-Thought)后,偏差问题仍然存在,显示出当前LMM在真实性判断上的固有局限。
专家领域知识匮乏
实验发现,LMM在医学影像、卫星图像等专业领域数据上的表现明显逊于常规图像。GPT-4o尽管在通用图像任务中表现优异,但在专业图像场景中的判断准确率显著下降,突显出当前LMM在特定领域数据中的适应能力不足。
多模态能力不均衡
LOKI实验揭示,当前LMM在图像和文本任务中表现优异,但在3D和音频等非主流模态数据中表现明显不足。尤其在音频异常检测和复杂3D模型分析中,模型的准确率接近随机选择,突显了多模态能力的严重不均衡问题。
不同问题难度下的模型表现
LMM在处理复杂问题时表现出明显的性能下降趋势。尽管在简单问题上表现良好,但在处理复杂合成数据检测任务时,其表现明显下降,甚至低于随机选择,显示出当前LMM在复杂任务上的不足。
提示策略对模型性能的提升
提示策略(Prompting Strategies)在提升LMM性能上效果显著。Chain-of-Thought(CoT)提示在某些模型上带来了明显性能提升,显示出提示优化在合成数据检测中的积极作用。GPT-4o表现出较强的内在推理能力,能够在不使用CoT提示时依然取得良好表现,而部分开源模型更依赖提示优化来弥补其推理能力的不足。
总结
本文提出了一个用于评估多模态大模型在检测各种模态合成数据方面性能的测试基准LOKI。LOKI基准不仅全面评估了LMM在多模态合成数据检测中的表现,还揭示了当前模型在偏差控制、专业领域知识、以及多模态任务中的不足。
研究发现,LMM在部分任务中已具备较强的异常检测与解释能力,尤其在文本与图像任务中表现突出。然而,模型在3D、音频等非主流模态上的表现仍显不足,进一步暴露出当前LMM在复杂任务场景下的局限性。
LOKI的提出为探索更强大、更具解释性的合成数据检测方法提供了重要参考。随着AI合成技术的迅猛发展,更精准的合成检测器不仅有助于提升模型的安全性和可靠性,也将推动AI合成数据的合理应用。
未来,更强大、更具解释性的检测器将进一步促进AI生成与检测技术的共同进步,形成“攻防并行、互促互进”的发展趋势。
(文:极市干货)