

姜东志,香港中文大学MMLab博士,研究方向为理解与生成统一的多大模型及多模态推理。在ICML, ICLR, NeurIPS, ECCV, ICCV等顶级会议上发表过论文。
最近的大语言模型(LLMs)如 OpenAI o1 和 DeepSeek-R1,已经在数学和编程等领域展示了相当强的推理能力。通过强化学习(RL),这些模型在提供答案之前使用全面的思维链(CoT)逐步分析问题,显著提高了输出准确性。最近也有工作将这种形式拓展到图片理解的多模态大模型中(LMMs)中。然而,这种 CoT 推理策略如何应用于自回归的图片生成领域仍然处于探索阶段,我们之前的工作 Image Generation with CoT(https://github.com/ZiyuGuo99/Image-Generation-CoT)对这一领域有过首次初步的尝试。
与图片理解不同,图片生成任务需要跨模态的文本与图片的对齐以及细粒度的视觉细节的生成。为此,我们提出了 T2I-R1—— 一种基于双层次 CoT 推理框架与强化学习的新型文本生成图像模型。

-
论文标题:T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
-
论文地址:https://arxiv.org/pdf/2505.00703
-
代码地址:https://github.com/CaraJ7/T2I-R1
-
机构:港中文 MMLab、上海 AI Lab
方法介绍
具体而言,我们提出了适用于图片生成的两个不同层次的 CoT 推理:
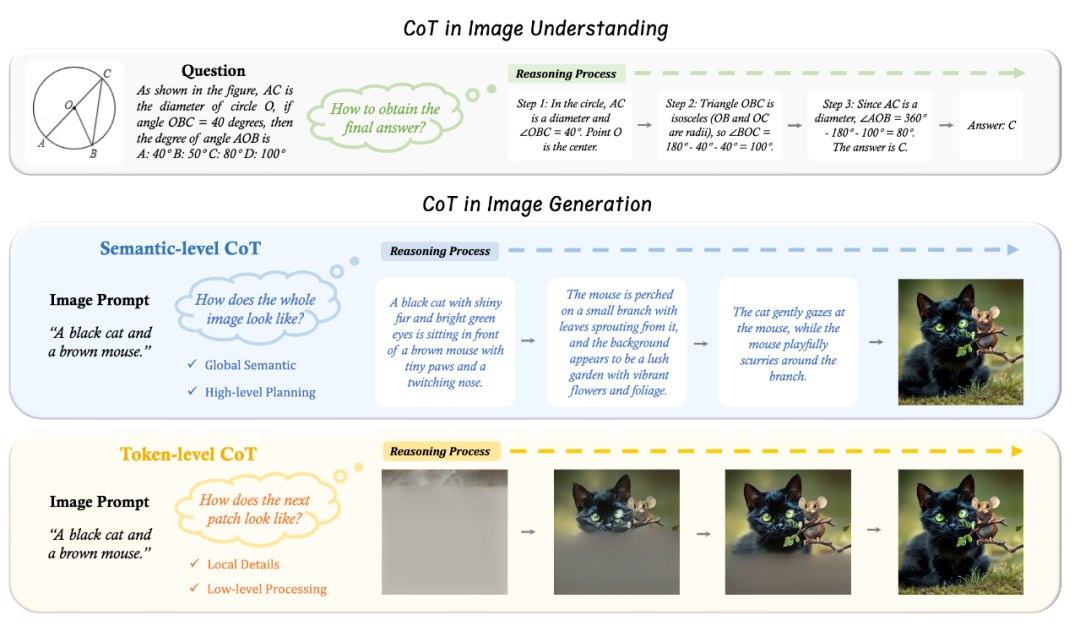
Semantic-CoT
-
Semantic-CoT 是对于要生成的图像的文本推理,在图像生成之前进行。
-
负责设计图像的全局结构,例如每个对象的外观和位置。
-
优化 Semantic-CoT 可以在图片 Token 的生成之前显式地对于 Prompt 进行规划和推理,使生成更容易。
Token-CoT
-
Token-CoT 是图片 Token 的逐块的生成过程。这个过程可以被视为一种 CoT 形式,因为它同样是在离散空间中基于所有先前的 Token 输出后续的 Token,与文本 CoT 类似。
-
Token-CoT 更专注于底层的细节,比如像素的生成和维持相邻 Patch 之间的视觉连贯性。
-
优化 Token-CoT 可以提高生成图片的质量以及 Prompt 与生成图片之间的对齐。

然而,尽管认识到这两个层次的 CoT,一个关键问题仍然存在:我们怎么能协调与融合它们?
当前主流的自回归图片生成模型如 VAR 完全基于生成目标进行训练,缺乏 Semantic-CoT 推理所需的显式文本理解。虽然引入一个专门用于提示解释的独立模型(例如 LLM)在技术上是可行的,但这种方法会显著增加计算成本、复杂性和部署的困难。最近,出现了一种将视觉理解和生成合并到单一模型中的趋势。在 LMMs 的基础上,这些统一 LMMs(ULMs)不仅可以理解视觉输入,还可以从文本提示生成图像。然而,它们的两种能力仍然是解耦的,通常在两个独立阶段进行预训练,没有明确证据表明理解能力可以使生成受益。
鉴于这些潜力和问题,我们从一个 ULM(Janus-Pro)开始,增强它以将 Semantic-CoT 以及 Token-CoT 统一到一个框架中用于文本生成图像:

我们提出了 BiCoT-GRPO,一种使用强化学习的方法来联合优化 ULM 的两个层次的 CoT:
我们首先指示 ULM 基于 Image Prompt 来想象和规划图像来获得 Semantic-CoT。然后,我们将 Image Prompt 和 Semantic-CoT 重新输入 ULM 来生成图片以获得 Token-CoT。我们对于一个 Image Prompt 生成多组 Semantic-CoT 和 Token-CoT,对于得到的图像计算组内的相对奖励,从而使用 GRPO 的方法来在一个训练迭代内,同时优化两个层次的 CoT。
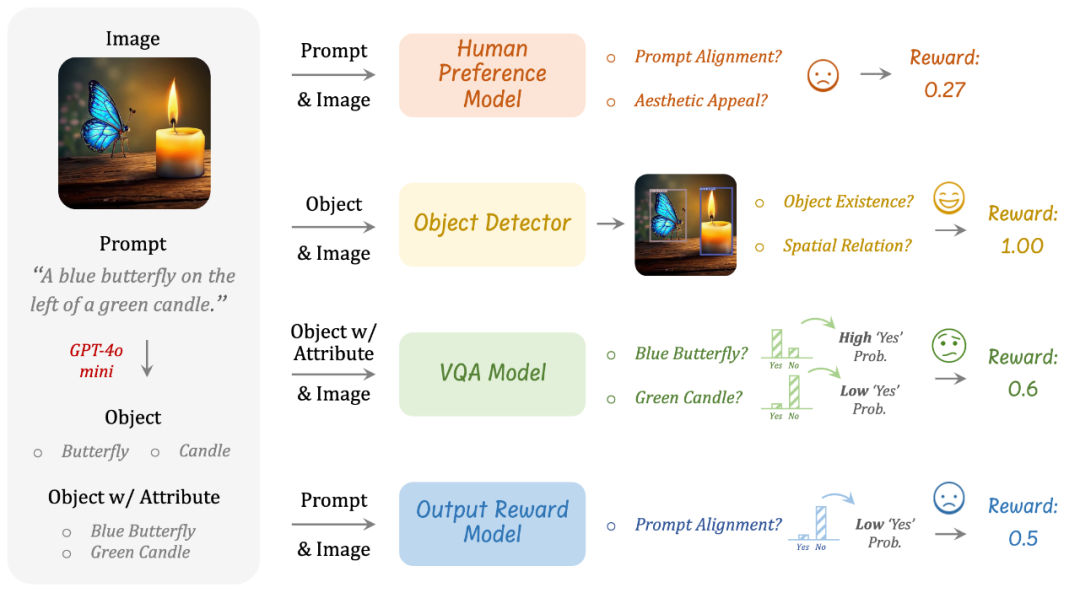
与图片的理解任务不同,理解任务有明确定义的奖励规则,图像生成中不存在这样的标准化的规则。为此,我们提出使用多个不同的视觉专家模型的集成来作为奖励模型。这种奖励设计有两个关键的目的:
-
它从多个维度评估生成的图像以确保可靠的质量评估
-
作为一种正则化方法来防止 ULM 过拟合到某个单一的奖励模型
根据我们提出的方法,我们获得了 T2I-R1,这是第一个基于强化学习的推理增强的文生图模型。
实验
根据 T2I-R1 生成的图片,我们发现我们的方法使模型能够通过推理 Image Prompt 背后的真实意图来生成更符合人类期望的结果,并在处理不寻常场景时展现出增强的鲁棒性。

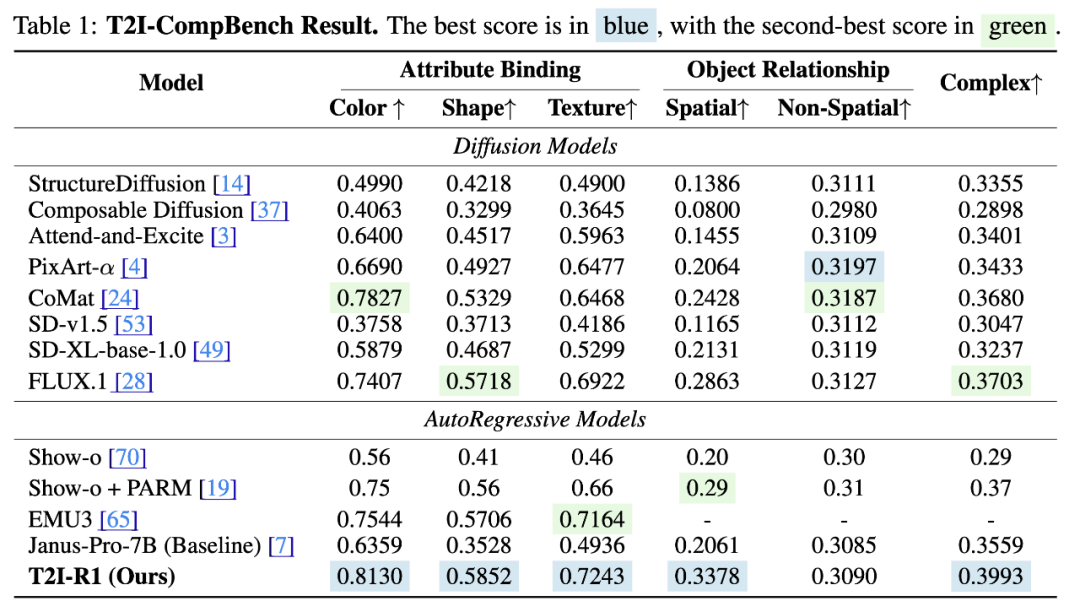
同时,定量的实验结果也表明了我们方法的有效性。T2I-R1 在 T2I-CompBench 和 WISE 的 Benchmark 上分别比 baseline 模型提高了 13% 和 19% 的性能,在多个子任务上甚至超越了之前最先进的模型 FLUX.1。

©
(文:机器之心)