

极市导读
能否以端到端的方式联合微调 VAE 和 LDM,以实现最佳生成性能? >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
解锁 VAE,端到端调优 Latent Diffusion Model。
本文的思路可以用图 1 概括,回答了:是否可以以 end-to-end 的方式同时训练 Latent Diffusion Model 和 VAE tokenizer?传统的深度学习告诉我们:如果 end-to-end 训练可行,就 end-to-end 训练。
但是对于 LDM 而言,观察到使用标准 diffusion loss 端到端训练 VAE 和 LDM 无效,甚至导致最终性能下降。
本文表明,虽然 diffusion loss 无效,但可以通过 representation-alignment (REPA) loss 来解锁 end-to-end 训练,即允许联合训练 VAE 和 LDM。本文的方法很简单,如图 1 所示,比 REPA 和原始的 training recipe 加速扩散模型训练超过 17× 和 45×。
有趣的是,观察到使用 REPA-E 的端到端训练也提高了 VAE 本身;从而提高了潜在空间结构和下游生成性能。在最终性能方面,REPA-E 在 ImageNet 256×256 上使用和不使用 cfg 的情况下,实现了 1.26 和 1.83 的 FID。

本文目录
1 REPA-E:解锁 VAE,端到端调优 Latent 扩散模型
(来自澳大利亚国立大学)
1 REPA-E 论文解读
1.1 REPA-E 研究背景
1.2 REPA-E 的动机和分析
1.3 REPA-E 方法介绍
1.4 实验设置
1.5 实验结果
1.6 REPA-E 的泛化性
1 REPA-E:解锁 VAE,端到端调优 Latent 扩散模型
论文名称:REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
论文地址:
https://arxiv.org/pdf/2504.10483
项目主页:
https://end2end-diffusion.github.io/
1.1 REPA-E 研究背景
在过去的十年中,端到端训练推动了深度学习领域的发展。话虽如此,latent diffusion models (LDM) 的训练方案仍是两阶段的:
-
训练变分自动编码器 (variational autoencoder, VAE),借助 reconstruction loss。 -
固定住 VAE,训练扩散模型,借助 diffusion loss。
这种两阶段的做法很受欢迎,但是这个优化的任务却很有挑战性:”如何从第一阶段 VAE 中得到最好的表征,以在第二阶段训练扩散模型时获得最佳的性能?”
虽然最近的工作研究了两个阶段的性能之间的相互作用[1][2],但它们往往局限于实证分析,这可能因 VAE 和 Diffusion Model 的体系结构和训练设置而异。例如,在[2]中表明流行的 AE 的 Latent space,如 SD-VAE 存在高频噪声的影响。

因此,本文提出了一个基本问题:”能否以端到端的方式联合微调 VAE 和 LDM,以实现最佳生成性能?“从技术上讲,通过简单地将 diffusion loss 反向传播到 VAE tokenizer 来端到端 LDM 训练很简单。然而,实验表明这种简单方法进行端到端训练是无效的。diffusion loss 鼓励学习更简单的 latent 空间结构,这对于去噪目标更容易,但会导致生成性能下降,如图 3 所示。

为了解决这个问题,本文提出 REPA-E,使用 representation alignment loss 的端到端训练方法。这种方案允许在训练过程中联合优化 VAE 和 LDM。本文证明了使用 REPA-E 的端到端调整有几个优点:
-
端到端训练导致加速生成模型训练: 与 REPA 和 vanilla training recipe 相比,REPA-E 可分别加速训练超过 17 倍和 45 倍 (图 3)。此外,它还有助于显着提高最终生成性能。如图 3 所示,使用流行的 SiT-XL 架构时,REPA-E 在 400K 步内达到 4.07 的 FID,显着提升了即使在 4M 步之后仅达到 5.9 的最终 FID。 -
端到端训练改善了 VAE 的 latent space: 如图 2 所示,在联合优化 VAE 和 LDM,可以改善不同 VAE 架构的 latent space。例如,对于 SD-VAE,观察到原始 latent space 存在高频噪声 (图 2)。端到端优化有助于学习更平滑的潜在空间表示。相比之下,IN-VAE 的 latent space 过度平滑。应用 REPA-E 会自动帮助学习更详细的 latent space 结构以最好地支持生成性能。 -
端到端调优提高了 VAE 性能: 一旦使用 REPA-E,端到端调优的 VAE 替代原始 VAE (例如 SD-VAE),在不同训练设置和模型架构上取得更好的生成性能。
1.2 REPA-E 的动机和分析
给定一个 VAE 和 LDM (如 SiT),本文希望以端到端方式联合调优 VAE 的 latent 表征和扩散模型的特征,以优化最终的生成性能。本文给了3个 insights:
-
naive 地进行端到端训练,即直接将 diffusion loss 反向传播到 VAE 是无效的。diffusion loss 鼓励学习更简单的 latent space 结构 (图 3),这对于最小化 denoising objective 很容易,但会降低最终生成性能。 -
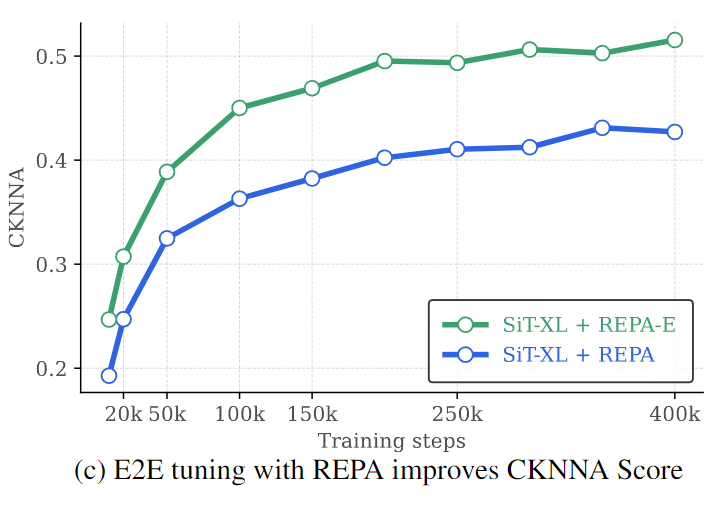
较高的 representation-alignment 分数与提高生成性能相关 (图 6)。这提供了一种替代路径,以使用表示对齐分数作为代理来提高最终生成性能。 -
原始 REPA 的最大可实现的对齐分数受 VAE latent space 特征的瓶颈。在训练期间将 REPA loss 反向传播到 VAE 可以帮助解决这个限制,显著提高最终的表征分数 (图 7)。
根据上述 insight,最终提出 REPA-E。REPA-E 的关键思想很简单:不是直接使用 diffusion loss 进行端到端调优,而是使用 representation-alignment loss 来执行端到端训练。使用 REPA loss 进行端到端训练有助于更好地提高最终表征对齐分数,反过来又可以提高最终生成性能。
下面逐点讲解。
naive 地进行端到端训练无效
作者首先尝试了下直接将 diffusion loss 反向传播到 VAE tokenizer。
如图 3 所示,可以观察到直接将 diffusion loss 反向传播鼓励学习更简单的 latent space 结构,沿空间维度的方差较低(图5)。更简单的 latent space 结构对 denoising objective 更容易实现,但同时会导致生成性能下降(图3)。考虑任何时间步 的中间 latent 。denoising objective 旨在预测 。从 VAE 特征 和时间步 估计最初添加的噪声 。
随着 VAE latent 的空间维度的方差下降,denoising objective 简化为预测偏置项以恢复最初添加的噪声 。因此,反向传播 diffusion loss 会破坏 latent space 结构,创建更容易的去噪问题,但导致生成性能下降。

更高的表示对齐与更好的生成性能相关
与 REPA 的发现类似,作者还使用不同的模型大小和训练迭代中的 CKNNA scores 测量表征对齐。如图 6 所示,可以观察到训练过程中较高的表示对齐可以提高生成性能。这表明了一种提高生成性能的替代路径,即:通过使用 REPA 作为端到端训练的目标,而不是 diffusion loss。

表示对齐受到 VAE 特征的限制
如图 7 所示,虽然 REPA loss 可提升表征对齐 (CKNNA) 的分数,但最大可实现的 CKNNA 分数仍然受 VAE 特征的限制,饱和在 0.4 值左右 (最大值为 1)。此外,本文发现将 REPA loss 反向传播到 VAE 有助于解决这一限制:允许端到端优化 VAE 特征,以最好地支持表征对齐的目标。
1.3 REPA-E 方法介绍
REPA-E 是一种联合训练 VAE 和 LDM 特征的端到端方法。REPA-E 使用 REPA loss 来执行端到端训练,而非直接使用 diffusion loss。使用 REPA loss 进行端到端训练有助于更好地提高最终表征对齐的分数,反过来又可以提高最终生成性能。下面是方法细节。
对 VAE latent 使用 Batch Norm 归一化
为了实现端到端训练,作者首先在 VAE 和 LDM 之间引入了一个 Batch Norm 层 (图 1)。典型的 LDM 训练包括使用预先计算的 latent 统计数据 (如 SD-VAE 的 std = 1/ 0.1825) 对 VAE 特征进行归一化,有助于将 VAE latent 输出归一化为零均值和单位方差,以更有效训练扩散模型。
但是如果现在是端到端训练,每当更新 VAE 模型时,都需要重新计算统计数据。
为了解决这个问题,本文提出使用 Batch Norm 层,它使用指数移动平均 (EMA) 均值和方差作为数据集级统计信息的代理。因此,Batch Norm 层其实相当于是充当可微归一化算子,无需在每个优化步骤后重新计算数据集级别统计信息。
端到端 REPA Loss
接下来使用 REPA loss 在训练期间更新 VAE 和 LDM 的参数来实现端到端训练。
令 表示 VAE, 为扩散模型, 为 REPA 的固定预训练感知模型(如 DINO-v2), 为干净图像。同样类似于 REPA,考虑 是 DiT hidden state 通过可训练投影层 的投影。然后,通过在 LDM 和 VAE 上应用 REPA loss 来执行端到端训练:
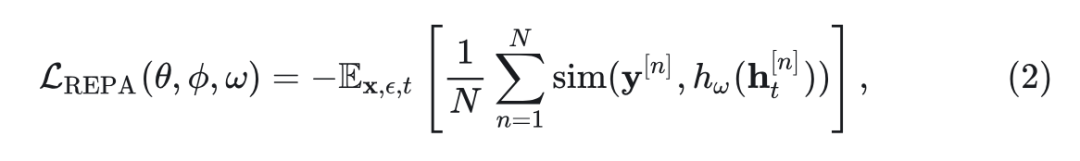
其中, 是预训练感知模型(如 DINOv2)的输出, 是 patch 的数量, 计算的是感知模型输出 和 DiT hidden state 之间的 patch-wise 的余弦相似度。
对 diffusion loss 做 stop-gradient
将 diffusion loss 反向传播到 VAE 会导致 latent space 结构的退化。为了避免这一点,REPA- E 引入了一个简单的 stopgrad 操作,将 diffusion loss 的应用范围限制为仅 LDM 的参数 。
VAE 正则化损失
为 VAE 引入了正则化损失 ,以确保端到端训练过程不会影响原始 VAE 的重建性能 (rFID)。具体而言,使用了 3 种 loss:
1.Reconstruction Loss 2.GAN Loss 3.KL divergence loss
总的损失函数:

以端到端的方式执行整体训练,其中, 分别表示 LDM、VAE 和可训练 REPA 投影层的参数。
1.4 实验设置
作者尝试了几种可用的 VAE 模型,包括 SD-VAE(f8d4),VA-VAE(f16d32),还有本文的 IN- VAE(f16d32)。根据 VAE 下采样率,分别对 4 倍和 16 倍下采样率采用 SiT-XL/ 1 和 SiT-XL/2模型,其中1和2表示 Transformer embedding 层中的 patch size。禁用 BN 的 affine transformation 操作。VAE 正则化损失结合了多个目标,定义为: 。对于对齐损失,使用 DINOv2 作为外部视觉特征,并对 SiT 模型第 8 层进行对齐。
对于采样,遵循 SiT 和 REPA 中的方法,使用具有 250 步的 SDE Euler-Maruyama 采样器。在 VAE 基准测试中,以 256×256 的分辨率从 ImageNet val 中测量 50K 图像的重建 FID (rFID)。
1.5 实验结果
训练速度和性能
首先如图 8 所示,作者将 REPA-E 与各种 LDM 基线进行了比较。有两个观察:
-
端到端可以更快训练:改进生成 FID (gFID):19.40 → 12.83 (20 epoch)、111.10 → 7.17 (40 epoch) 和 7.90 → 4.07 (80 epoch)。
-
端到端训练可以带来更好的最终性能:80 Epoch 的 REPA-E 超过训练了 400 个 epoch 的 FasterDiT (gFID=7.91),甚至训练了超过 1400 个 epoch 的 MaskDiT、DiT 和 SiT。REPA-E 在 400K 步达到 4.07 的 FID,而对比来讲 REPA 即使在 4M 步后只达到 5.9 的最终 FID。
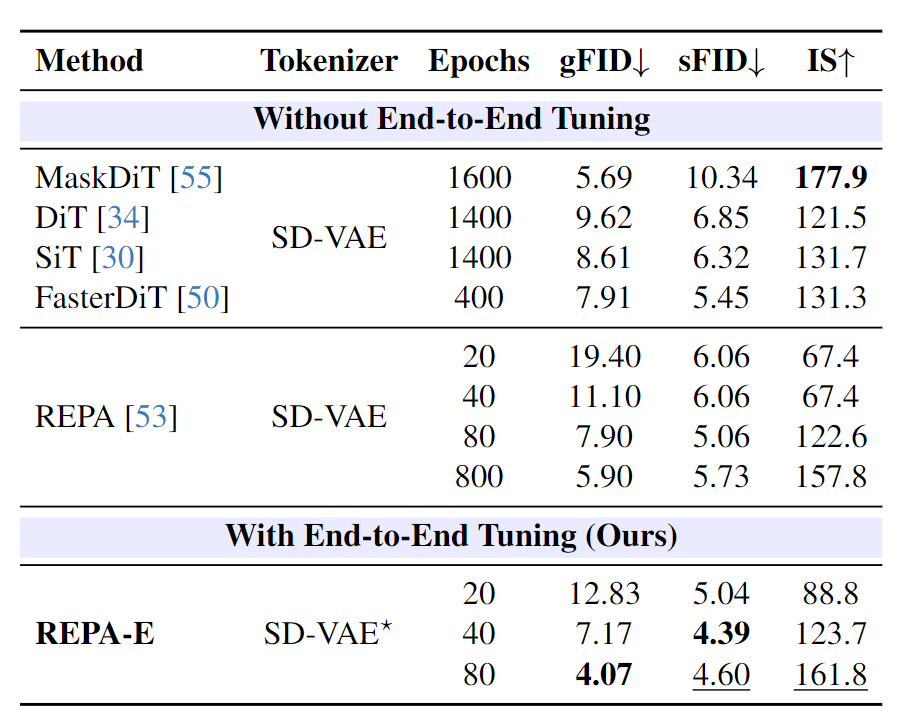
图 9 中提供了 REPA 和 REPA-E 之间的定性比较。分别使用 50K、100K 和 400K 训练迭代的检查点从相同的噪声和标签生成图像。如图 9 所示,REPA-E 与 REPA 基线相比具有更好的图像生成质量,同时也在训练过程中的早期阶段生成了更多结构有意义的图像。

对 VAE 的影响
作者分析了端到端训练对 VAE 的影响。首先表明端到端调优可以改进 latent space 结构 (图 11)。一旦使用 REPA-E 进行调整,微调后的 VAE 可以用作原始 VAE 的替代品,显著提高生成性能。
端到端调优可以改进 latent space 结构
如图 11 所示,作者使用主成分分析 (PCA) 可视化 latent space 结构,将 latent space 结构投影到 RGB 三个通道。考虑 3 种不同的 VAE:SD-VAE,IN-VAE (16 倍下采样,ImageNet 上训练的 32 通道 VAE),VA-VAE。
观察到使用 REPA-E 的端到端调整自动改进了原始 VAE 的 latent space 结构。观察到 SD-VAE 在 latent space 中存在较高的噪声成分。应用端到端训练有助于调整 latent space 以学习减少噪声。相比之下,最近提出的 VA-VAE 等其他 VAE 都存在过度平滑的 latent space。使用 REPA-E 进行端到端调优可以帮助学习到更详细的 latent space 结构,更好地支持生成性能。

端到端训练提高了 VAE 性能
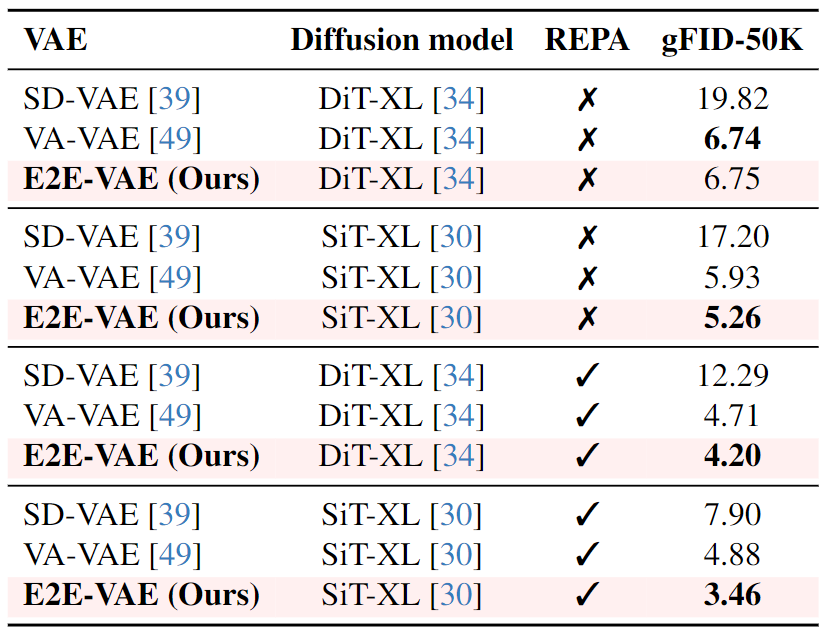
下面作者评估端到端训练对 VAE 下游生成性能的影响。作者首先使用端到端调优来微调 VA-VAE。然后,使用得到的端到端微调之后的 VAE (命名为 E2E-VAE),将其下游生成性能与当前最先进的 VAE 进行比较。
为此,训练 LDM (w/o REPA-E),在做这个实验的时候保持 VAE 冻结,同时更新生成器网络。图 12 显示了 VAE 下游生成性能的比较。可以观察到,端到端调优的 VAE 在不同的 LDM 架构和训练设置下,其下游生成任务性能优于原始 VAE。有趣的是,观察到使用 SiT-XL 调优的 VAE 即使在使用不同的 LDM 架构 (如 DiT-XL) 时也能产生性能改进,证明了本文方法的有效性。
1.6 REPA-E 的泛化性
本节分析 REPA-E 对训练设置变化的泛化性,包括模型大小、tokenizer 架构、视觉 Encoder、对齐深度等。除非另有说明,所有分析和消融都使用 SiT-L 作为生成模型,SD-VAE 作为 VAE,DINOv2-B 作为 REPA loss 的预训练视觉模型。使用默认 REPA 对齐深度为 8。训练每个变体 100K iterations,并报告没有 cfg 的结果。所有 baseline 数字均报告原始 REPA 结果,并与使用 REPA-E 的端到端训练进行比较。
模型大小
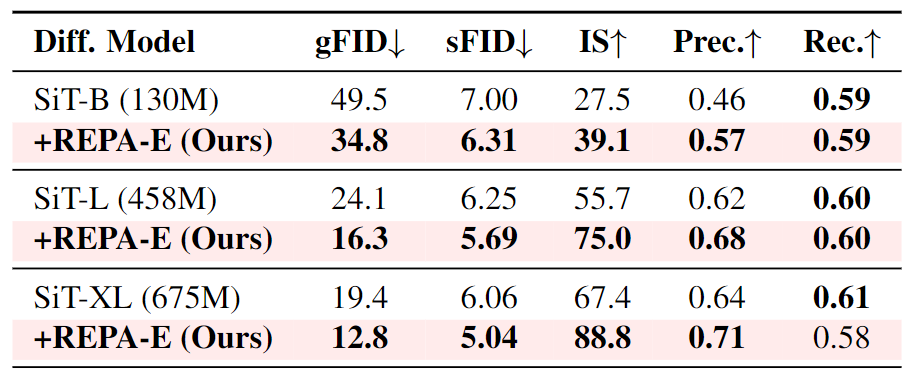
图 12 比较了 SiT-B、SiTL 和 SiT-XL 的结果。两点观察:
-
不同的模型尺寸下,REPA-E 始终提高了 REPA 基线的性能。
-
使用 REPA-E 相比 REPA 实现的 gFID 的百分比增益随着模型大小的增加而提高。这一趋势突出了 REPA-E 的可扩展性。更大的模型相比原始 REPA 获得了更高的百分比增益。
不同视觉 Encoder 的影响
图 13 报告了不同感知模型视觉 Encoder (CLIP-L、I-JEPA-H、DINOv2-B 和 DINOv2-L) 的结果。观察到,对于不同的感知编码器模型,REPA-E 相较于 REPA 都提供了改进。尤其是使用 DINOv2-B 和 DINOv2-L,REPA-E 显着降低 gFID。

不同 VAE 的影响
图 14 评估了不同 VAE 对 REPA-E 性能的影响。报告了 3 种不同的 VAE 的结果 1) SD-VAE、2) VA-VAE 和 3) IN-VAE。在所有变体中,REPA-E 始终比 REPA 基线提高性能。结果表明,REPA-E 对于不同的 VAE 架构、预训练数据集和训练设置,都稳健地提高了生成质量。

扩散模型对齐深度的影响
图 15 研究了在扩散模型的不同层应用对齐损失的效果。可以观察到,REPA-E 在不同的对齐深度,始终提高 REPA 基线的生成质量。

消融实验
消融研究分析了每个组件的重要性,结果如图 16 所示。每个组件在 REPA-E 的最终性能中起着关键作用。尤其是可以观察到 stopgrad 操作有助于防止潜在空间结构的退化。

参考
-
Eq-vae: Equivariance regularized latent space for improved generative image modeling -
Improving the diffusability of autoencoders
(文:极市干货)