

新智元报道
新智元报道
【新智元导读】3D生成模型高光时刻来临!DreamTech联手南大、复旦、牛津发布的Direct3D-S2登顶HuggingFace热榜。仅用8块GPU训练,效果超闭源模型,直指影视级精细度。
HuggingFace是全球最大的开源大模型社区,汇集了来自世界各地的上百个开源大模型。
其趋势榜(HuggingFace Trending)展示了各类开源大模型在全球开发者中的受欢迎程度,DeepSeek、Qwen等大模型就因曾登顶HuggingFace榜单而获得了全球开发者的关注与热议。可以说,这是当前最具权威性的榜单之一。
最近一周,由DreamTech推出的Direct3D-S2 3D大模型登顶HuggingFace 3D modeling应用趋势榜,并在涵盖文本、图像和视频的综合榜单上跃居至第4位。
这个大模型不仅赢得了海外知名AI精选博主AK (@_akhaliq) 的推荐,还在全球3D及AI领域的开发者和爱好者中引起了广泛关注。
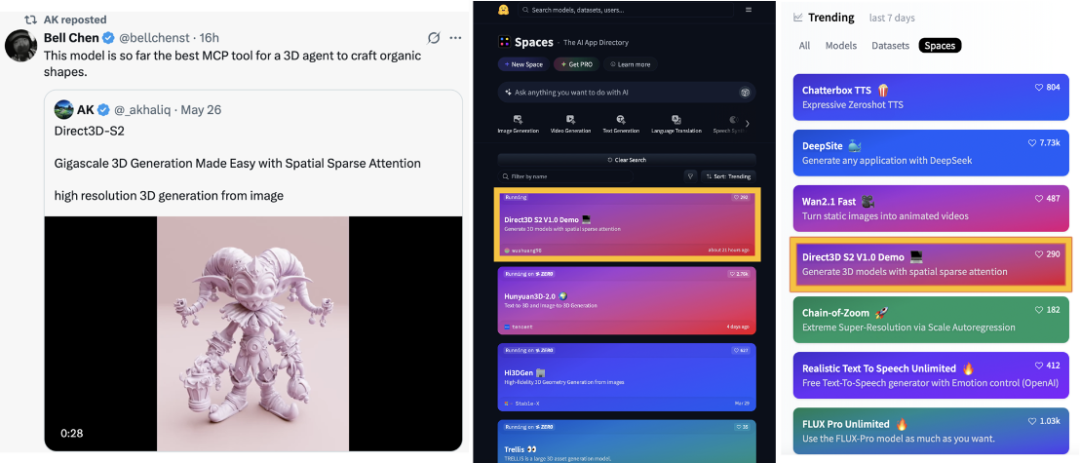
Direct3D-S2仅需8张GPU训练,生成效果远超数百张GPU训练的闭源商用模型,训练效率提升近20倍,相比现有的大模型,token吞吐量从4K提升到256K,直接提高64倍,目标直指影视级别高精细度3D模型生成。
许多开发者表示Direct3D-S2就是「最强开源3D大模型」,直呼「3D生成的概念神」。
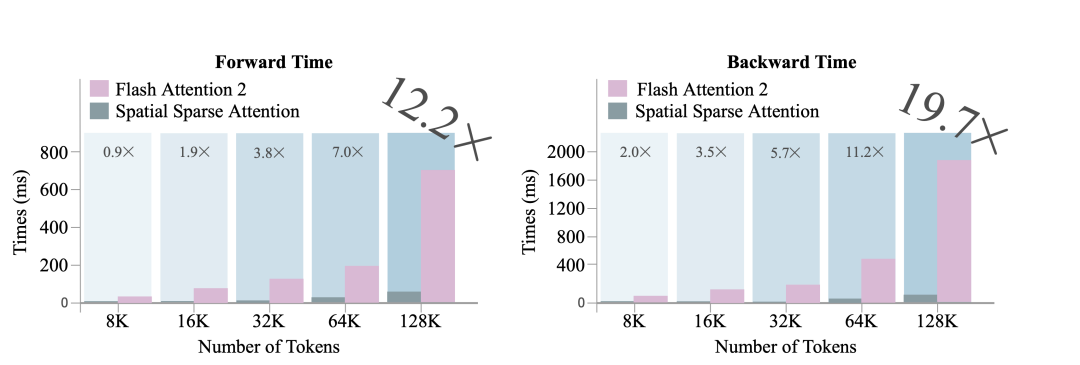
为什么一个3D大模型能在AI行业引起如此高的关注度呢?
从DreamTech团队发布的论文中,我们或许能找到答案。Direct3D-S2所实现的突破性进展,不仅提升了3D模型的精度与效率,也开启了新的应用场景和技术可能性。
这不仅是对技术边界的探索,也是其在AI领域创新能力的一次重要展示。

论文地址:https://arxiv.org/pdf/2505.17412
从游戏角色、电影特效,到VR体验和3D打印产品,背后都离不开一个关键技术——3D建模。它就是数字世界的基础手艺,但传统建模过程复杂又耗时。
AI正在改变这一切。近年来,越来越多的公司开始用来替代人工建模,AI不仅更快,效果也越来越逼真。微软、Meta、腾讯、字节跳动等行业巨头,以及众多创新企业纷纷发力,推出了各种AI 3D生成工具,掀起了一场技术热潮。
而在所有探索中,如何让AI生成的3D模型更清晰、更精细,已经成为大家最关心的问题之一。

现在AI已经能轻松生成高清的图片和视频了,但为什么利用AI进行高质量的3D建模却仍旧这么难?这背后有两个关键原因。
-
3D数据比2D复杂得多。图像和视频只是平面信息,而3D模型要完整地表达一个物体在空间中的形状,它的细节是「立方级」的复杂度。也就是说,分辨率越高,需要处理的token数量会呈立方倍增长。比如,把分辨率从128提升到256,token数量的差别不是2倍,而是2³=8倍。
-
AI模型本身的计算压力也很大。目前主流的AI架构Transformer在处理大量细节时会变得特别吃力,Transoform核心的Attention(注意力)机制的运算复杂度是随着数据token数量呈平方增长的。这意味着,当你想要更精细的模型时,算力需求几乎是指数爆炸式上升。
举个例子:即使是分辨率为256级的3D生成任务,通常也需要动用32至64块高端GPU进行训练。
而如果要生成1024级分辨率甚至影视级别超高精细度的3D任务,则需要几千甚至上万块GPU训练。这种训练方式成本高昂,技术挑战也非常大。
如何在有限的资源下实现高质量的3D生成,已经成为整个行业都在攻克的核心难题。
DreamTech联合南京大学、牛津大学提出了Direct3D-S2,解决了高分辨率3D生成的瓶颈问题。
在Direct3D-S2中,DreamTech团队提出了一项核心创新——空间稀疏注意力机制(Spatial Sparse Attention, SSA)。
这一机制专为解决当前Diffusion Transformer(DiT)在处理高分辨率3D生成时效率低、精细度差的问题而设计,堪称3D生成领域的效率引擎。
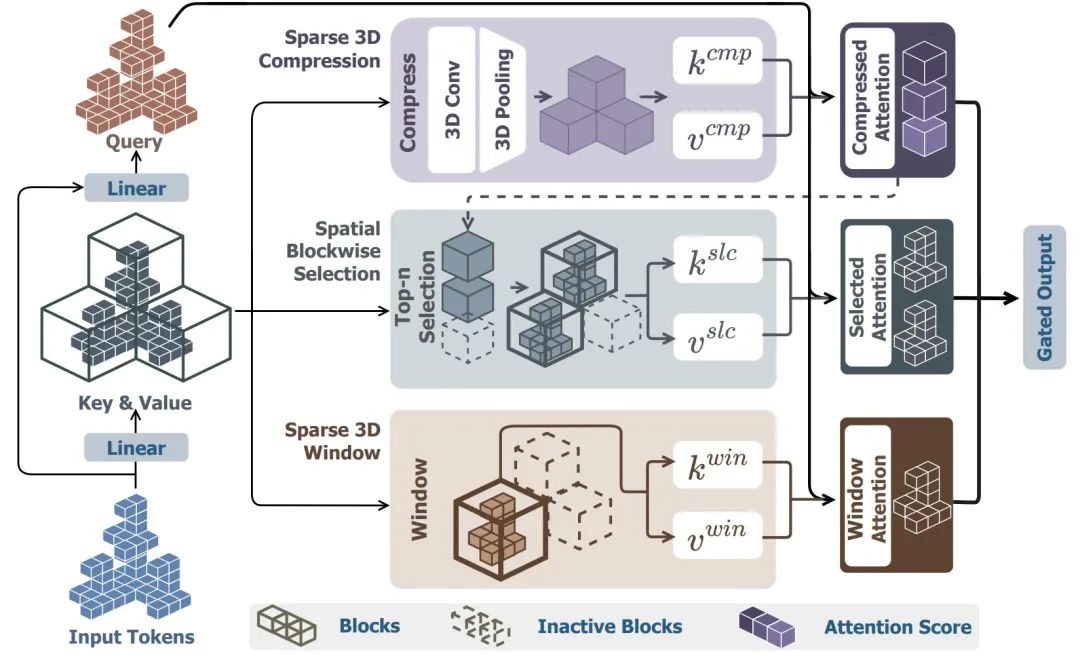

通过自适应3D空间分块策略,SSA可以让模型只关注真正重要的体素区域,避免大量冗余计算。
即使面对1024³的超高分辨率,模型也能轻松处理数十万级tokens,token吞吐量提高64倍!
在大幅提高效率的同时,SSA并没有牺牲质量。
它基于空间几何连续性概率分布对tokens进行智能分块,确保局部结构完整、表面平滑自然,避免了传统方法中常见的「断裂」或「扭曲」现象。
除了SSA注意力机制的创新,Direct3D-S2还引入了适配SSA的全新架构,包括稀疏SDF VAE和稀疏DiT,实现了从输入到输出的全流程效率提升。
Direct3D-S2首次将3D生成表征统一到SDF(符号距离函数)体素场中,无需依赖传统的点云、多视角图像或隐式空间等复杂转换过程。
简化了训练流程,将模型训练的稳定性和训练速度提升到极致。
Direct3D-S2支持基于3D几何空间的multi-scale训练与推理,仅用8块A100 GPU,2天即可完成训练,整体效率提升4倍以上。
同时,借助稀疏条件机制,模型能聚焦于前景物体的关键区域,实现更高效的交叉注意力计算,从而显著增强细节生成能力。

在3D生成领域,细节决定成败。
Direct3D-S2在生成质量上的突破,正是体现在它对复杂几何结构和精细纹理的出色还原能力上。
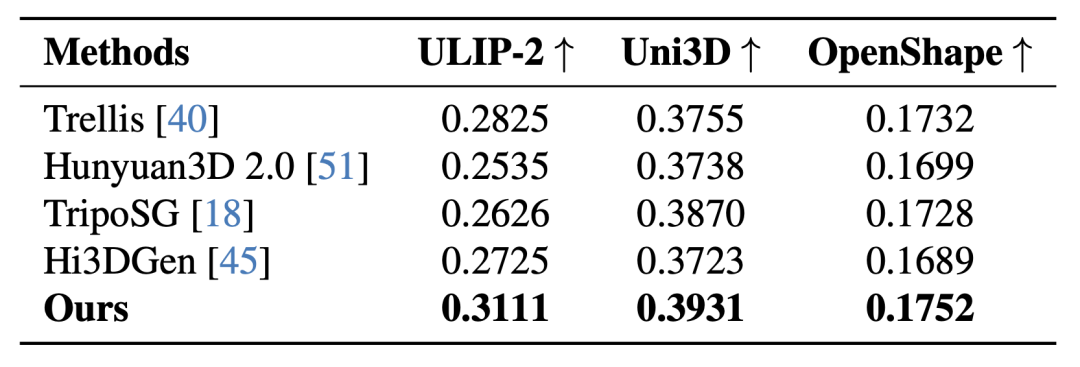
在多项关键指标对比中,Direct3D-S2全面超越当前主流开源3D生成模型,在所有数值评测中全部领先。
无论是细节丰富程度、几何精度、表面光滑度,还是整体结构的一致性,Direct3D-S2都展现出显著优势。
不仅如此,在由数十位艺术家与开发者参与的盲测评估中,Direct3D-S2也在「图像一致性」与「几何质量」两个核心维度上获得最高评分。
这意味着,不仅数据亮眼,实际效果也真正能打动专业人士。
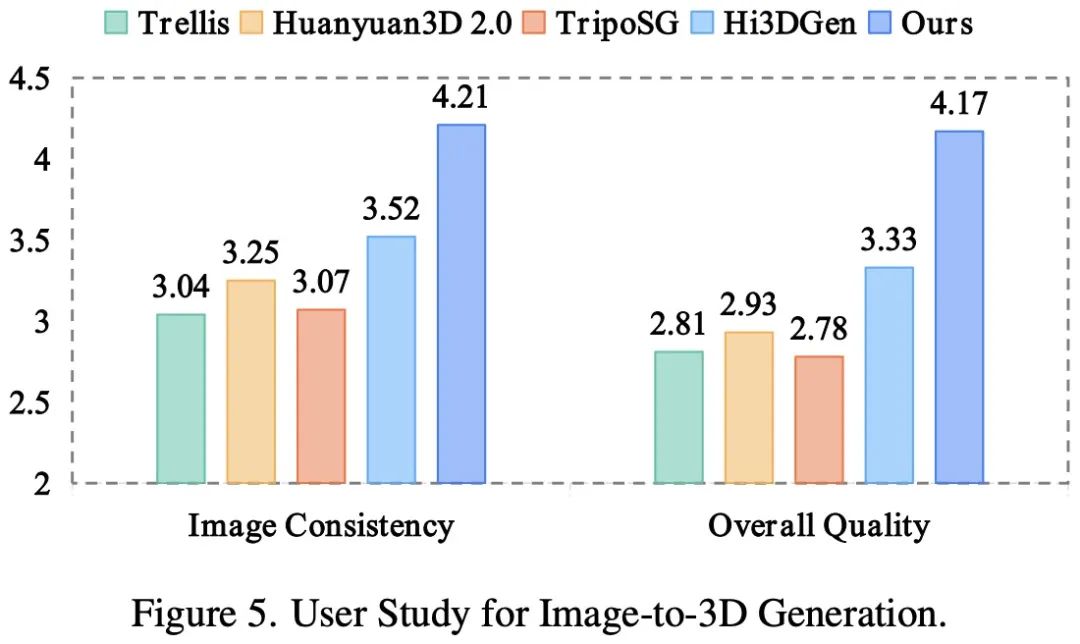
与当前流行的开源3D生成大模型对比,Direct3D-S2在细节和精细度表现上超越了全部的开源3D大模型。
尽管只使用8张A100显卡和公开数据集训练,Direct3D-S2在生成的模型细节上甚至超过了目前市面上几乎全部的闭源商用模型。
换句话说,Direct3D-S2不仅是目前最强的开源3D生成大模型之一,更是首个在质量和实用性上真正接近工业级应用的开源方案。
DreamTech始终秉持「技术共享」的理念,已将Direct3D-S2全面开源,并采用最宽松的 MIT License协议,允许自由用于商业用途,堪称业界良心,这一举措赢得了行业的广泛赞誉。
为了让全球开发者更方便地体验与使用Direct3D-S2,DreamTech提供了多个开放入口:
· GitHub项目地址(开源代码):
https://github.com/DreamTechAI/Direct3D-S2
· 技术详情与论文访问:
https://www.neural4d.com/research/direct3d-s2/
· HuggingFace在线体验Demo:
https://huggingface.co/spaces/wushuang98/Direct3D-S2-v1.0-demo
此外,DreamTech官网还提供更强版本模型及一系列实用功能,供用户免费使用,助力开发者、艺术家和企业快速上手与落地应用。
· DreamTech官网入口:
www.neural4d.com
创新无边界,Direct3D-S2不仅是一次技术突破,更是推动3D生成普及化的重要一步。
DreamTech深耕于3D及4D AI技术领域,致力于用创新的产品和服务提升全球AIGC创作者及消费者的使用体验,公司的愿景是利用先进的AI技术打造与真实世界无缝对接、实时互动的时空智能体验,并通过模拟真实世界的复杂性和多样性实现通用人工智能(AGI)。


(文:新智元)