
原地址:https://leimao.github.io/blog/CUDA-Kernel-Execution-Overlap/ ,来自Lei Mao,已获得作者转载授权。后续会转载几十篇Lei Mao的CUDA相关Blog,Blog会从稍早一些的CUDA架构到当前最新的CUDA架构,也会包含实用工程技巧,底层指令分析,Cutlass分析等等多个课题,是一个时间线十分明确的专栏。
CUDA kernel执行重叠
介绍
在我之前的博客文章”CUDA Stream”(https://leimao.github.io/blog/CUDA-Stream/)中,我讨论了CUDA流如何帮助CUDA程序实现并发。在文章的最后,我还提到除了内存传输和 kernel执行重叠之外,不同 kernel之间的执行重叠也是被允许的。然而,许多CUDA程序员想知道为什么他们之前没有遇到过 kernel执行重叠。
在这篇博客文章中,我想讨论CUDA kernel执行重叠,以及为什么我们在实践中能够或无法看到它们。
CUDA kernel执行重叠
计算资源
如果有足够的计算资源来并行化多个 kernel执行,CUDA kernel执行就可以重叠。
在下面的例子中,通过将blocks_per_grid的值从小变到大,我们可以看到来自不同CUDA流的 kernel执行从完全并行化,到部分并行化,最后到几乎没有并行化。这是因为,当为一个CUDA kernel分配的计算资源变大时,为额外CUDA kernel分配的计算资源就会变小。
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#define CHECK_CUDA_ERROR(val) check((val), #val, __FILE__, __LINE__)
void check(cudaError_t err, const char* const func, const char* const file,
const int line)
{
if (err != cudaSuccess)
{
std::cerr << "CUDA Runtime Error at: " << file << ":" << line
<< std::endl;
std::cerr << cudaGetErrorString(err) << " " << func << std::endl;
std::exit(EXIT_FAILURE);
}
}
#define CHECK_LAST_CUDA_ERROR() checkLast(__FILE__, __LINE__)
void checkLast(const char* const file, const int line)
{
cudaError_t const err{cudaGetLastError()};
if (err != cudaSuccess)
{
std::cerr << "CUDA Runtime Error at: " << file << ":" << line
<< std::endl;
std::cerr << cudaGetErrorString(err) << std::endl;
std::exit(EXIT_FAILURE);
}
}
__global__ void float_add_one(float* buffer, uint32_t n)
{
uint32_tconst idx{blockDim.x * blockIdx.x + threadIdx.x};
uint32_tconst stride{blockDim.x * gridDim.x};
for (uint32_t i{idx}; i < n; i += stride)
{
buffer[i] += 1.0F;
}
}
void launch_float_add_one(float* buffer, uint32_t n,
dim3 const& threads_per_block,
dim3 const& blocks_per_grid, cudaStream_t stream)
{
float_add_one<<<blocks_per_grid, threads_per_block, 0, stream>>>(buffer, n);
CHECK_LAST_CUDA_ERROR();
}
int main(int argc, char** argv)
{
size_tconst buffer_size{1024 * 10240};
size_tconst num_streams{5};
dim3 const threads_per_block{1024};
// Try different values for blocks_per_grid
// 1, 2, 4, 8, 16, 32, 1024, 2048
dim3 const blocks_per_grid{32};
std::vector<float*> d_buffers(num_streams);
std::vector<cudaStream_t> streams(num_streams);
for (auto& d_buffer : d_buffers)
{
CHECK_CUDA_ERROR(cudaMalloc(&d_buffer, buffer_size * sizeof(float)));
}
for (auto& stream : streams)
{
CHECK_CUDA_ERROR(cudaStreamCreate(&stream));
}
for (size_t i = 0; i < num_streams; ++i)
{
launch_float_add_one(d_buffers[i], buffer_size, threads_per_block,
blocks_per_grid, streams[i]);
}
for (auto& stream : streams)
{
CHECK_CUDA_ERROR(cudaStreamSynchronize(stream));
}
for (auto& d_buffer : d_buffers)
{
CHECK_CUDA_ERROR(cudaFree(d_buffer));
}
for (auto& stream : streams)
{
CHECK_CUDA_ERROR(cudaStreamDestroy(stream));
}
return0;
}
$ nvcc overlap.cu -o overlap
$ ./overlap
我们观察到当blocks_per_grid = 1时出现完全并行化。然而,我们也可以看到完成所有 kernel所花费的时间很长,因为GPU没有被充分利用。
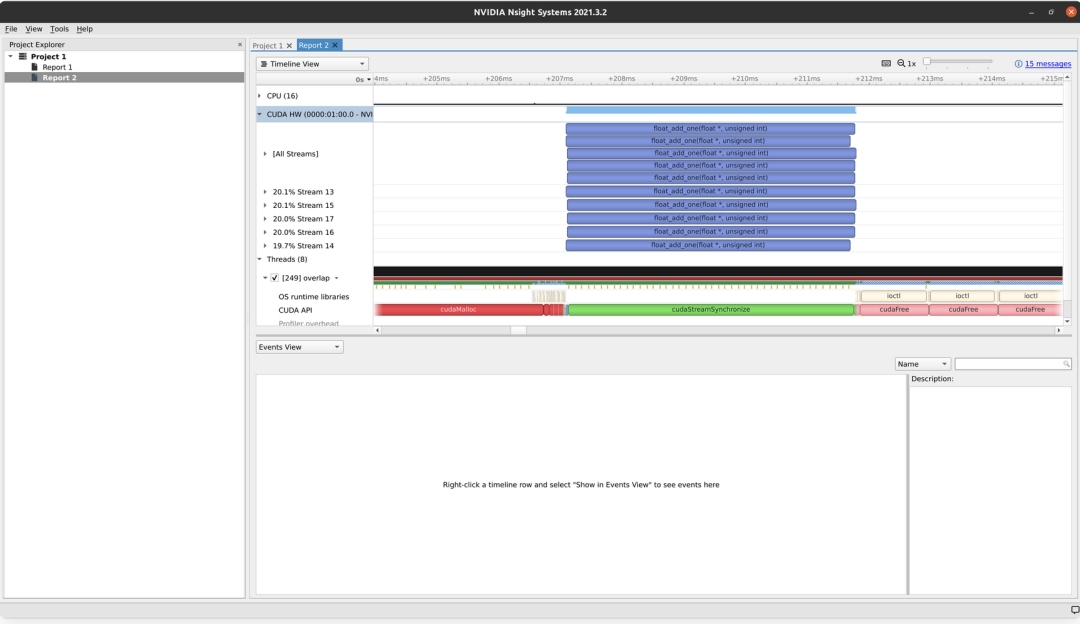
当我们设置blocks_per_grid = 32时,只有部分 kernel执行被并行化。然而,GPU被充分利用,完成所有 kernel所花费的时间比blocks_per_grid = 1时少得多。
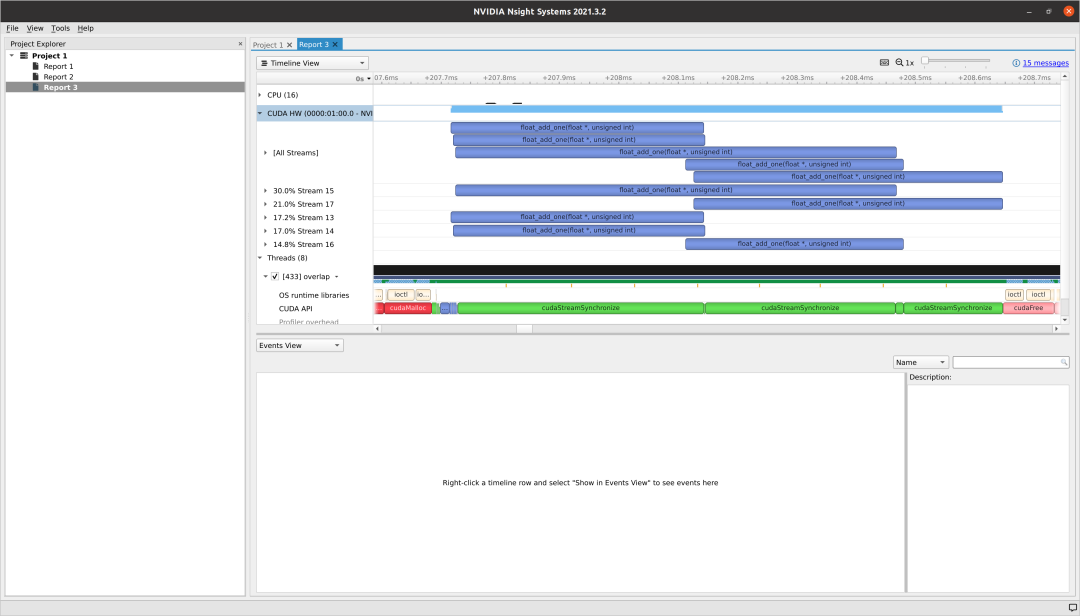
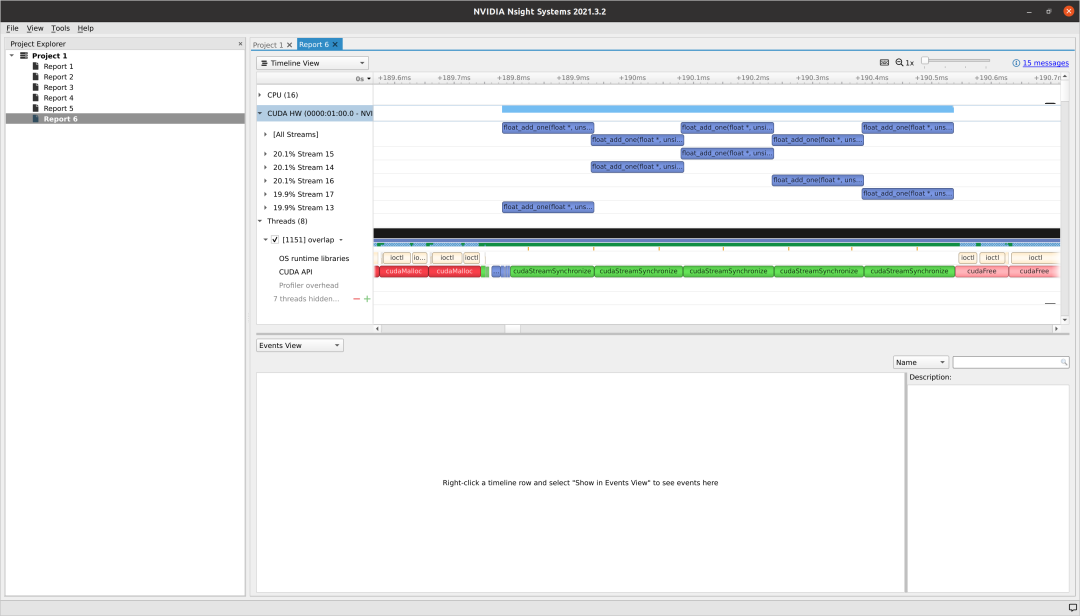
与blocks_per_grid = 32相同,当我们设置blocks_per_grid = 5120时,几乎没有 kernel执行被并行化。然而,GPU仍然被充分利用,完成所有 kernel所花费的时间比blocks_per_grid = 1时少得多。
隐式同步
即使有足够的计算资源,也可能没有 kernel执行重叠。这可能是由于主机线程向default Stream 发出的CUDA命令在来自其他不同流的其他CUDA命令之间造成隐式同步(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#implicit-synchronization)。
在我看来,由于CUDA程序员通常编写CUDA程序的方式,这在单线程CUDA程序中很少发生。然而,这在多线程CUDA程序中肯定会发生。为了克服这种情况,从CUDA 7开始,创建了一个per-thread default Stream 编译模式。用户只需要在NVCC编译器构建标志中指定--default-stream per-thread,而无需更改现有的CUDA程序来禁用隐式同步。要了解更多关于如何使用per-threaddefault Stream 简化CUDA并发的详细信息,请阅读Mark Harris的博客文章(https://developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/)。
截至CUDA 11.4,默认的构建参数仍然是legacy。用户必须手动将其更改为per-thread才能使用per-threaddefault Stream 。来自CUDA 11.4 NVCC帮助:
--default-stream {legacy|null|per-thread} (-default-stream)
Specify the stream that CUDA commands from the compiled program will be sent
to by default.
legacy
The CUDA legacy stream (per context, implicitly synchronizes with
other streams).
per-thread
A normal CUDA stream (per thread, does not implicitly
synchronize with other streams).
'null' is a deprecated alias for 'legacy'.
Allowed values for this option: 'legacy','null','per-thread'.
Default value: 'legacy'.
结论
如果默认CUDA流没有隐式同步,部分或没有CUDA kernel执行并行化通常表示GPU利用率高,而完全CUDA kernel执行并行化通常表示GPU可能没有被充分利用。
如果没有CUDA kernel执行重叠是由于默认CUDA流的隐式同步造成的,我们应该考虑通过启用per-threaddefault Stream 来禁用它。
参考资料
-
GPU Pro Tip: CUDA 7 Streams Simplify Concurrency(developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/) -
Nsight Systems in Docker(https://leimao.github.io/blog/Docker-Nsight-Systems/)
(文:GiantPandaCV)