
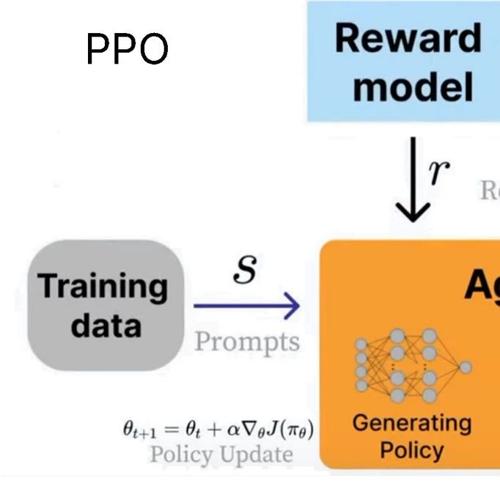
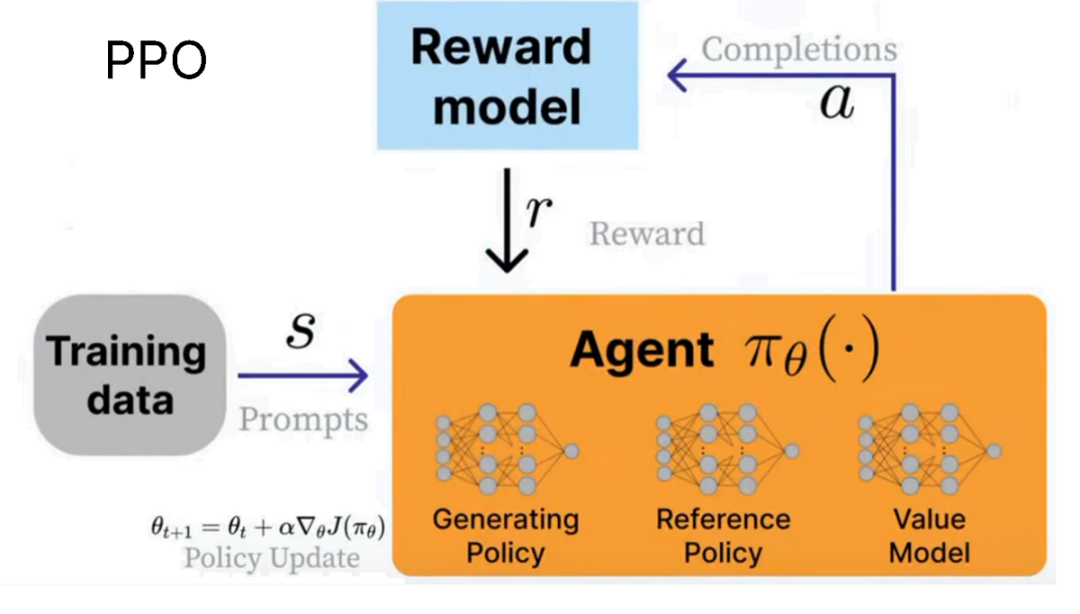
unsloth制作了一份关于大模型强化学习的完整指南。内容包括:
-
强化学习的目标及其在构建智能 AI 代理中的关键作用 -
o3、Claude 4 和 R1 为何使用强化学习 -
GRPO、RLHF、DPO、奖励函数 -
通过 Unsloth 训练本地 R1 模型
参考文献:
[1] http://docs.unsloth.ai/basics/reinforcement-learning-guide
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)