


当一个强大的多模态大模型(MLLM)在解决复杂的数学几何问题时,你是否想过它会“走神”?
我们发现,在进行多步、长链条的推理时,即便是最先进的 MLLM,也会逐渐“忘记”最初给它的图像信息,越来越依赖自己生成的文本,最终导致“一本正经地胡说八道”。我们称这种现象为“视觉遗忘”(Visual Forgetting)。
为了解决这个棘手的难题,我们非常荣幸地宣布,来自南京大学和腾讯的联合研究成果《Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning》已被自然语言处理顶会 ACL 2025 接收。
在本文中,我们不仅首次系统性地揭示并量化了“视觉遗忘”现象,还提出了一种全新的解决方案——伴随式视觉条件化(Take-along Visual Conditioning, TVC),显著提升了 MLLM 在长链推理任务上的表现!

论文标题:
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
论文链接:
https://arxiv.org/abs/2503.13360
代码及数据集:
https://github.com/sun-hailong/TVC

问题的核心:AI如何“忘记”图像?
在纯文本的长链推理(CoT)中,模型会不断重复关键信息(如“三角形 ABC”、“公式(1)”)来保持专注。但在多模态任务中,图像信息通常只在推理的最开始输入一次,之后便不再“露面”。随着推理链条的拉长,模型对视觉信息的注意力会急剧衰减。
我们做了一个大胆的实验:在模型推理到一半时,悄悄把图像拿走。结果惊人地发现,在 MathVista 数据集上,模型的准确率仅下降了约 2%!
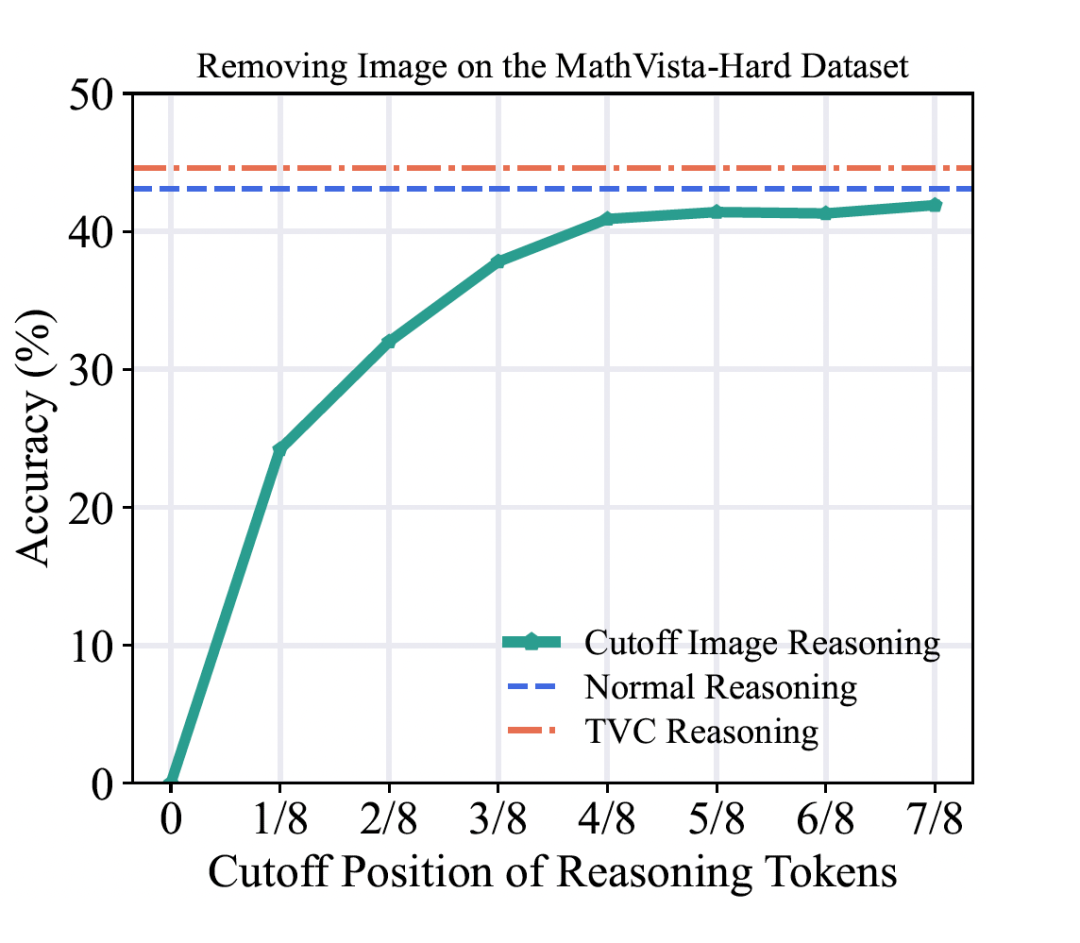
▲ 图1:在推理的不同阶段移除图像对模型性能的影响。曲线越平,说明模型对图像的依赖越低,遗忘越严重。
这有力地证明了,在推理的后半段,模型几乎完全依赖于之前生成的文本,而忽略了至关重要的视觉证据。我们进一步通过可视化注意力权重(如下图),直观地看到了模型注意力从图像(IMG)向文本(Response)的快速转移。
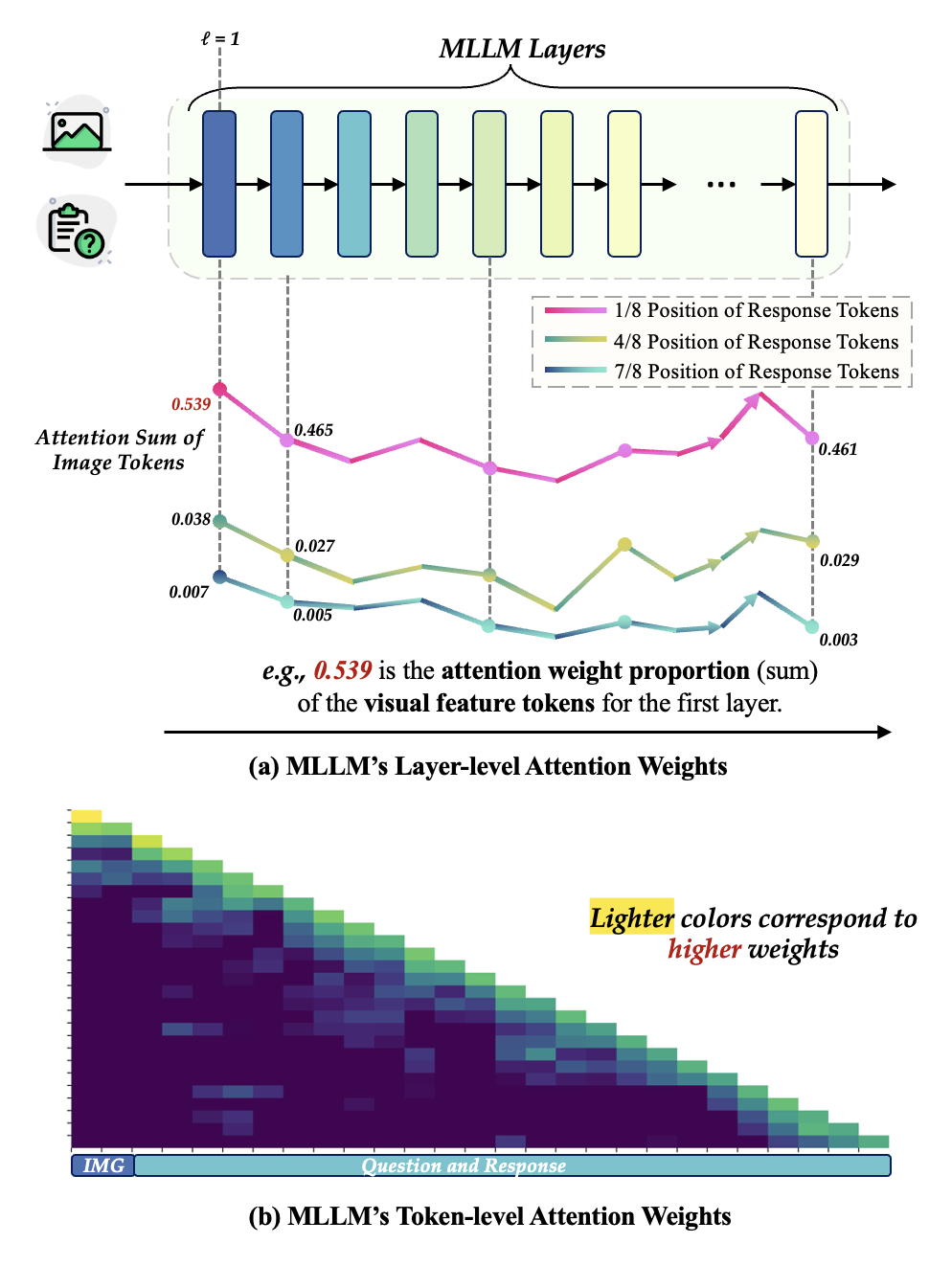
▲ 图2:模型注意力权重分布图,清晰展示了视觉注意力的衰减过程。

我们的解决方案:TVC-AI的“随身视觉草稿本”
TVC(Take-along Visual Conditioning)正是为此而生。它不是一个复杂的全新架构,而是一套精巧的、动态的视觉信息重注入机制,旨在模拟人类的这一认知行为。TVC 的核心思想可以分解为两个协同工作的阶段:训练阶段的“习惯养成”和推理阶段的“学以致用”。
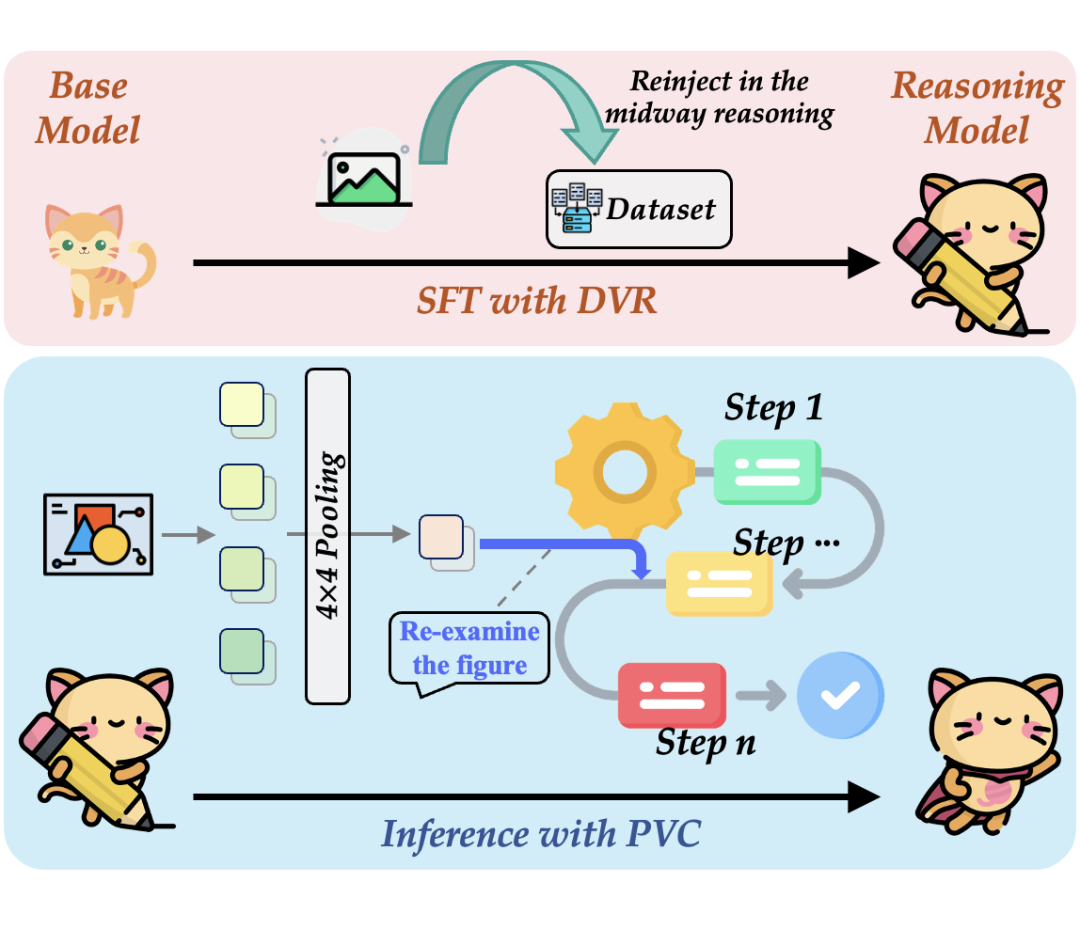
▲ 图3:TVC 系统设计总览
2.1 第一阶段:训练-教会模型“回头看”的习惯(DVR)
要让模型学会“回头看”,我们必须在训练数据中就为其创造这样的场景。我们称这个过程为动态视觉重确认(Dynamic Visual Reaffirmation, DVR)。
1. 打造高质量“教材”:长链推理数据策划
首先,我们需要一份好的教材。我们整合了 MathV360K、Geo170K 等高质量学术数据集,通过我们精心设计的数据生成流水线(详见后文),生成了大量包含完整、正确推理步骤的(图像,问题,长链回答)数据对。这份数据集是训练的基础。
2. 模拟“回头看”场景:视觉内容注入(Visual Content Injection)
这是 DVR 的关键。在原始的长链推理数据中,模型是一口气从头推到尾的。为了打破这种惯性,我们进行了如下操作:
-
定位注入点:对于一条包含 L 步推理的长链条,我们在中间(例如 0.5L 处)或者随机选择多个自我反思(Self-reflection)的节点。这些节点通常是模型进行关键步骤转换或检查的地方。
-
手动注入视觉信息:在这些节点上,我们“打断”模型的推理,将原始的视觉特征(Visual Embeddings)和一个桥接提示(Bridging Prompt)重新插入到推理上下文中。这个提示语就像在告诉模型:“等一下,让我再看看图确认一下。”
-
重新生成后续步骤:基于注入了视觉信息的新上下文,我们让模型重新生成后续的推理步骤,并确保其最终答案仍然正确。
通过在训练数据中大量引入这种“中途看图”的样本,模型被迫学会在文本推理的同时,不断地重新融合和利用视觉信息。这就像一个学生在做题时,被老师反复提醒要对照图形,久而久之,就养成了“凡事看图”的严谨习惯。
2.2 第二阶段:推理-在实战中灵活运用“回头看”(PVC)
当模型训练好后,在面对新的、未见过的问题时,如何自主地、高效地“回头看”呢?这就是周期性视觉校准(Periodic Visual Calibration, PVC)发挥作用的时候。
在推理过程中,当模型生成到某个预设的、或由模型自身判断需要反思的节点时,PVC 机制会被触发,并执行一套行云流水的“三步曲”:
1. 第一步:视觉信息“打包”-令牌压缩(Token Compression)
直接将原始的、高维的视觉令牌(通常有数百个)注入推理流,会带来两个问题:
-
计算开销大:增加推理的计算负担。
-
干扰文本连贯性:过多的视觉信息可能会“冲淡”模型对已有文本上下文的记忆,导致思路中断。
为了解决这个问题,我们首先使用平均池化(Average Pooling)对视觉令牌进行压缩。例如,将原本 16×16=256 个令牌压缩成 4×4=16 个。这个过程就像是将一张高清大图,在保持核心空间布局和语义的前提下,“打包”成一个轻量级的视觉摘要。
2. 第二步:为“新信息”腾出空间 – 视觉缓存重置(Visual Cache Reset)
现代大语言模型在生成文本时,会使用一种叫做 KV 缓存(KV Cache)的机制来存储之前生成内容的注意力信息,以加速后续的生成。为了让新注入的视觉信息能被模型“看到”并给予足够的重视,我们在此刻选择性地重置与视觉相关的 KV 缓存。
这相当于在模型的“工作记忆”中,为即将到来的视觉“草稿”腾出一块干净的地方,确保它不会被旧的注意力信息所淹没。
3. 第三步:精准“投喂” – 重注入图像与提示
最后一步,我们将“打包”好的压缩视觉令牌,连同一个桥接提示语(如 “[IMG TOKEN] Let me check the image again.”),一起添加到当前的生成提示(prompt)的最前端。
然后,模型会基于这个包含了最新视觉信息的“增强版”提示,继续进行后续的推理。这个过程确保了模型在每一个关键决策点,都能基于最准确、最及时的视觉证据来校准自己的思维路径,从而有效避免因“视觉遗忘”而导致的错误累积。
总结一下 TVC 的精髓:
-
DVR(训练时):通过数据增强,教会模型在推理中途处理视觉信息的能力,养成“回头看”的习惯。
-
PVC(推理时):建立一套高效、低干扰的机制,让模型在实战中能自主、灵活地运用这个习惯,周期性地用视觉信息来校准推理。
通过这套“训练习惯 + 推理应用”的组合拳,TVC成功地为多模态大模型在漫长的推理之旅中,提供了一个持续、可靠的视觉“锚”,让它不再“忘本”,从而在复杂的视觉推理任务中表现得更加精准和鲁棒。

高质量数据引擎:迭代式蒸馏与拒绝采样
为了训练出强大的长链推理能力,我们还设计了一套精密的数据生成流水线。我们采用迭代式蒸馏和拒绝采样的策略,从强大的教师模型(如 QVQ-72B)中“榨取”出高质量的推理数据,并对数据进行动态截断和反思词修剪,确保了训练数据的正确性、简洁性和高效性。
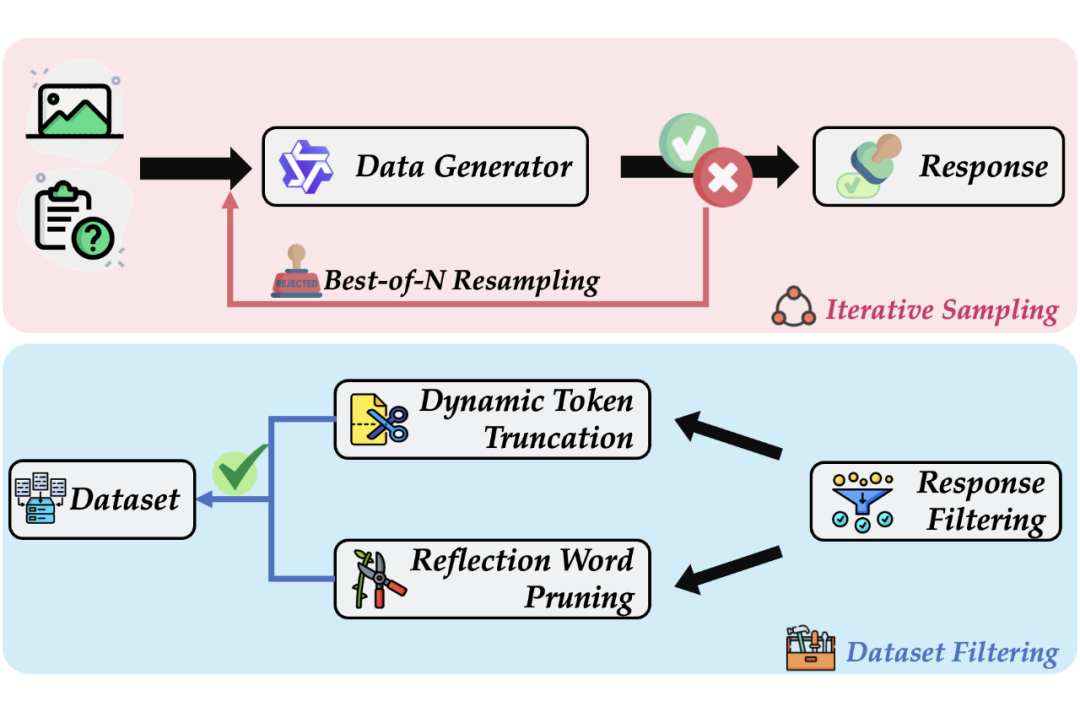
▲ 图4:TVC 的数据生成流水线

惊艳的效果:TVC表现如何?
我们在 MathVista, MathVerse 等五个主流的视觉推理基准上进行了全面评测。
结果显示,TVC 取得了 SOTA(State-of-the-Art)性能!
-
性能飞跃:在应用了 TVC 后,Qwen2-VL-72B 模型在多个基准上性能大幅提升,平均分高出之前 SOTA 模型 3.4 个点。
-
全面有效:无论是在通用的视觉推理任务还是在专精的数学推理任务上,TVC 都展现出强大的效果和泛化能力。
-
小模型也强大:搭载 TVC 的 7B 模型,在某些任务上甚至能超越未优化的 72B 模型,证明了我们方法的普适性。
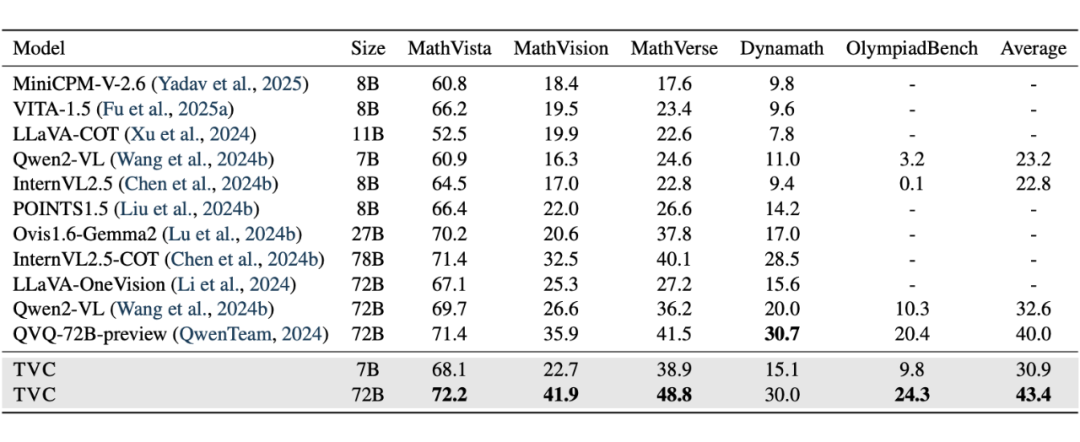
▲ 表1:TVC 在多个视觉推理基准上的 SOTA 表现
在下图中,基础模型因为没有仔细看材质(rubber vs. metallic),算错了数量。而 TVC 在推理过程中通过“回头看图”,精确识别了每个物体的材质,最终得出了正确答案。

▲ 图5:TVC 纠错案例,模型通过重新审视图中物体的材质,修正了最初的错误答案。

总结与展望
“视觉遗忘”是阻碍多模态大模型迈向更高阶认知能力的一大障碍。我们的工作不仅系统地揭示了这一问题,更提出了一个简洁而有效的解决方案——TVC。
TVC 通过模拟人类“反复看图”的行为,为 MLLM 在长链推理中提供了持续的视觉“锚点”,显著增强了其推理的准确性和鲁棒性。
再次感谢大家对我们工作的关注!
我们已将项目主页和代码开源,欢迎大家 Star、Fork、试用和交流!
论文链接:
https://arxiv.org/abs/2503.13360
代码及数据集:
https://github.com/sun-hailong/TVC
👉 点个“在看”,分享给更多对多模态推理感兴趣的朋友吧!
(文:PaperWeekly)