

极市导读
Meta等机构发布Pisces模型,它采用“双脑架构”,通过解耦视觉编码架构和三阶段渐进训练策略,实现了图像理解和生成任务的统一与协同,其在20多个图像理解基准和生成基准上表现出色,甚至超越了专用模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接: https://arxiv.org/pdf/2506.10395
亮点直击
解耦视觉编码架构:首创分任务设计视觉编码器,解决理解与生成的固有矛盾。 三阶段渐进训练:通过数据分层优化,实现细粒度多模态对齐与强指令跟随能力。 任务协同效应:首次揭示图像理解与生成在统一框架中的相互增强作用。 开源组件高效整合:巧妙结合CLIP、扩散模型和LLM,平衡性能与计算成本。

总结速览
解决的问题
-
统一多模态模型的性能差距:现有的统一多模态模型在图像理解和生成任务上表现不如专用模型,限制了实际应用。 -
视觉特征与训练差异:图像理解需要高分辨率、长序列视觉特征,而图像生成需要短序列特征以保持一致性,现有方法难以兼顾。 -
编码器不匹配问题:图像理解和生成任务的最佳视觉编码器通常不同,单一编码器难以同时优化两种任务。
提出的方案
-
解耦视觉编码架构:采用独立的视觉编码器、投影层和特征长度,分别优化图像理解(长序列)和生成(短序列)。
-
三阶段训练策略:
-
第一阶段:基础预训练(高质量图像-短标题对)。 -
第二阶段:细粒度对齐预训练(图像-详细标题对)。 -
第三阶段:指令微调(多样化任务指令数据)。 -
协同训练框架:通过统一的多模态框架联合训练图像理解与生成任务,利用任务间的协同效应提升性能。
应用的技术
-
预训练组件:基于CLIP图像编码器(理解)、扩散模型(生成)和LLM(语言建模)。 -
自回归多模态建模:统一处理图像与文本的生成和理解。 -
数据优化:精心策划的预训练与微调数据集,覆盖多样任务和指令。
达到的效果
-
性能领先:在20+个图像理解基准和GenEval生成基准上达到竞争性甚至超越专用模型的水平。 -
任务协同增益:发现图像理解与生成任务相互促进,联合训练显著提升双方性能。 -
灵活高效:解耦编码器降低推理成本,同时支持高分辨率理解与高质量生成。
模型架构
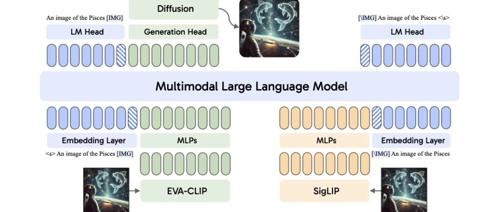
本文的模型设计受到近期多模态模型架构的启发,这些模型通过有效利用预训练模型实现了强劲性能。如下图2所示,本文提出了一种新颖的解耦视觉编码架构,用于支持自回归多模态模型同时完成图像理解和生成任务。该模型包含一个预训练的大型语言模型(LLM)、一个专用于图像理解的图像编码器、另一个专为图像生成优化的图像编码器,以及一个扩散模型。
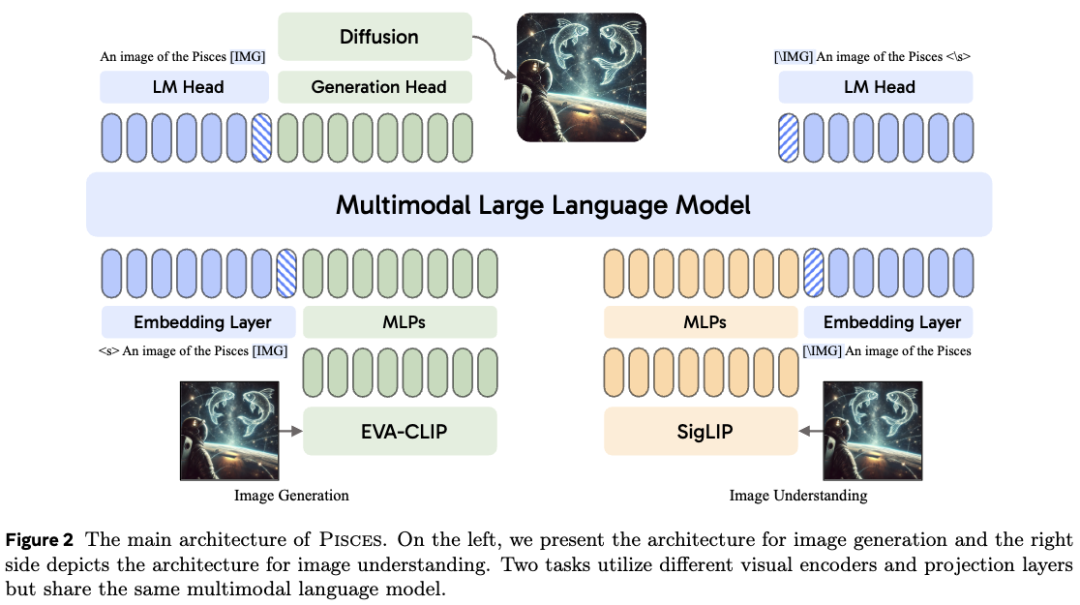
解耦视觉表示
解耦视觉编码架构的设计理念源于图像理解与图像生成任务对视觉表示的内在差异。图像理解要求视觉编码器从原始图像中提取丰富且详细的语义信息,以支持准确的分析与理解,因此需要较长的图像向量序列。相比之下,图像生成要求视觉编码器将像素级信息压缩为紧凑的向量序列,高效捕捉视觉外观的核心特征,同时优化自回归生成过程。后面分别介绍两种视觉编码过程的细节。
图像理解
给定输入图像 ,图像理解视觉编码器 将其处理为连续的图像表示序列 。这些表示随后通过一个多层感知机(MLP)模块投影到语言模型的隐空间,得到
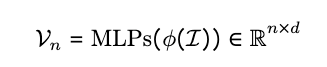
\text { 其中,} n \text { 表示视觉标记的数量,} d \text { 表示经过MLP投影后视觉标记的隐藏维度。 }
图像生成
图像生成视觉编码器 将图像 处理为连续的向量序列,表示为 。在图像生成任务中,LLM以自回归方式预测这些向量。然而,自回归生成如此长的连续图像向量序列对LLM提出了重大挑战。为缓解这一问题,本文采用平均池化减少视觉tokens数量,从而在保留关键视觉信息的同时使序列更易处理。图像tokens序列 首先被重塑为二维结构,随后应用步长为 的二维池化进行下采样,得到池化后的扁平化序列 个tokens。最后,额外的MLP层将这些池化后的图像向量投影至LLM的隐空间,生成图像生成任务的图像表示:
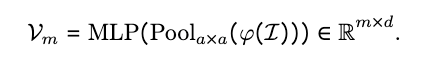
多模态大语言模型
为了有效管理图像理解和图像生成任务,精心设计的训练目标至关重要。给定一个图像-文本对:
-
对于图像理解,本文的目标是根据图像预测相应的文本 -
对于图像生成,文本被用作条件提示来生成图像
给定文本时,LLM的嵌入层将每个文本token映射为一个向量,形成文本嵌入 。对于图像理解任务,图像向量 被前置到文本嵌入前,形成 ,然后输入到LLM中。图像理解的训练目标是根据输入的图像向量和之前生成的文本token,预测下一个文本token的概率分布。
对于图像生成任务,图像向量 被追加到文本嵌入 后,形成 。在这个任务中,目标是根据输入的文本和之前生成的图像向量,预测下一个连续的图像向量。
因此,可以将这两个任务的统一训练目标定义为
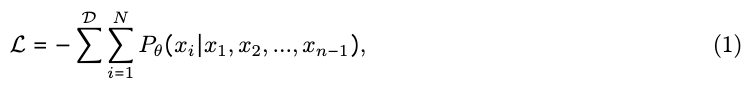
其中 表示离散文本token或连续图像向量, 表示多模态大语言模型的参数, 表示序列长度, 是包含图像理解和图像生成实例的训练数据集。这个统一目标通过两种损失函数进行优化:
-
对于图像理解,交叉熵损失函数减小预测文本token概率分布与真实分布之间的差异; -
对于图像生成,均方误差(MSE)损失函数最小化预测图像向量与图像编码器生成的真实图像向量之间的差异。
基于扩散模型的图像解码
给定预测的视觉向量V_m,使用条件扩散模型作为解码器从这些向量重建图像。这个条件扩散模型使用CLIP图像编码器进行预训练,根据CLIP模型的最后一层嵌入生成原始图像。在预训练期间,图像编码器保持冻结状态,而扩散模型会被更新。
推理
在图像生成的推理过程中,多模态大语言模型以自回归方式预测所有m个图像向量。这些向量随后通过图像生成头映射回图像编码器的向量空间,并输入到扩散模型中以指导去噪过程。遵循Sun等人(2024b)的方法,多模态模型使用空标题作为输入提供无分类器指导。对于图像理解,该过程遵循标准语言建模,使用下一个token预测来生成文本输出。
模型训练与数据
训练阶段1:多模态预训练
在预训练阶段,同时优化模型的图像描述和图像生成能力。对于图像生成,使用来自内部Shutterstock数据集的1.5亿个高质量图像-标题对,应用提示”请根据以下标题生成图像:<caption>[IMG]<image>[/IMG]”。对于图像理解,使用相同的1.5亿张图像,但使用Llama 3.2模型生成的详细标题。在描述任务中使用的提示是”[IMG]<image>[/IMG]请提供给定图像的详细描述。<caption>“。
训练阶段2:细粒度多模态预训练
在细粒度多模态预训练阶段,继续在7000万个图像和详细标题对上对Pisces进行预训练,同时用于生成和理解任务。与第一阶段使用的详细标题类似,这些详细标题由Llama 3.2模型生成。这个阶段旨在增强生成图像中文本token与视觉特征之间的对齐,同时避免图像理解性能的下降。图像生成和理解使用的提示与第一阶段相同。
训练阶段3:图像理解与生成的指令调优
在指令调优阶段,进一步优化Pisces在图像理解和生成方面的能力和泛化性。对于图像理解,精心策划了来自两个综合数据集的大量图像理解任务,最终得到800万个高质量的图像-文本对。对于图像生成,从预训练使用的Shutterstock数据集中随机抽取400万个图像和简短标题对,以及400万个图像和详细标题对。通过混合使用简短和长标题的实例,保留了更广泛的输入格式分布。图像生成和理解数据集被合并,在每个训练步骤随机采样实例以促进平衡有效的学习过程。
实现细节
在Pisces中,使用LLaMA-3.1-Instruct 8B初始化多模态语言模型,采用siglip-so400m-patch14-384作为图像理解的视觉编码器,并使用同时结合MAE重建损失和对比损失训练的CLIP模型作为图像生成的视觉编码器(记为gen-CLIP)。理解和生成投影层均为两层MLP,图像生成输出头也是两层MLP。对于图像解码,训练SDXL作为图像解码器,用于从gen-CLIP图像嵌入重建图像。使用4×4池化核将gen-CLIP嵌入池化为64个连续向量。在所有三个阶段中,训练多模态LLM和两个用于图像理解与生成的MLP,同时保持两个图像编码器冻结。学习率设为2e-5,并使用带warm-up的恒定学习率调度器,warm-up比例为0.03。前两个阶段的batch size为2048,第三阶段为1024。
评估
图像理解
基线模型:评估了模型与近期开源的统一模型(兼具图像理解和生成能力)以及专精于图像理解的强基线模型的对比。统一模型包括EMU2 Chat、Chameleon 7B和34B、Seed-X、CM3Leon、DreamLLM、Show-o和EMU3。与专用模型的比较中,使用专攻图像理解任务的LLaVA 1.5(7B和13B)。
评估基准:在四大类基准上评估不同MLLM模型的性能:通用多模态基准(VQAv2、GQA、MMBench(EN和CN)、VisWiz、POPE、MM-Vet、MME Perception、MME Cognition、SeedBench、HallusionBench、LLaVA in the Wild和MMStar);OCR与图表基准(TextVQA、OCRBench、DocVQA和InforVQA);基于知识的基准(AI2D、MathVista、MMMU和ScienceQA);以视觉为中心的基准(MMVP、RealworldQA和CV-Bench)。
图像生成
基线模型:本文与最先进的统一模型(兼具图像理解和生成能力)进行比较,包括CoDI、LWM、SEED-X、EMU、Chameleon、Transfusion、Show-o、EMU3和Janus。此外,还与专精于图像生成的模型进行基准测试,如SDv1.5、DALL-E 2、PixArt-alpha、Llama Gen、LDM、SDv2.1、SDXL和SDv3。
评估基准:在广泛采用的图像生成基准GenEval上评估Pisces的图像生成性能,使用GenEval官方实现的评估指标。
主要结果
图像理解
综合评估基准:如下表1b(a)所示,与开源统一模型相比,Pisces在大多数综合评估基准上实现了最先进的性能。它甚至超越了参数规模2-4倍的统一模型(如Seed-X 17B和Chameleon 34B),凸显了其作为通用视觉聊天助手的强大能力。此外,本文的模型大幅超越近期所有模型,如在MMBench上比EMU3高26.3%,在MME-P上比Seed-X高8.6%,在MM-Vet上比EMU3高34.4%。
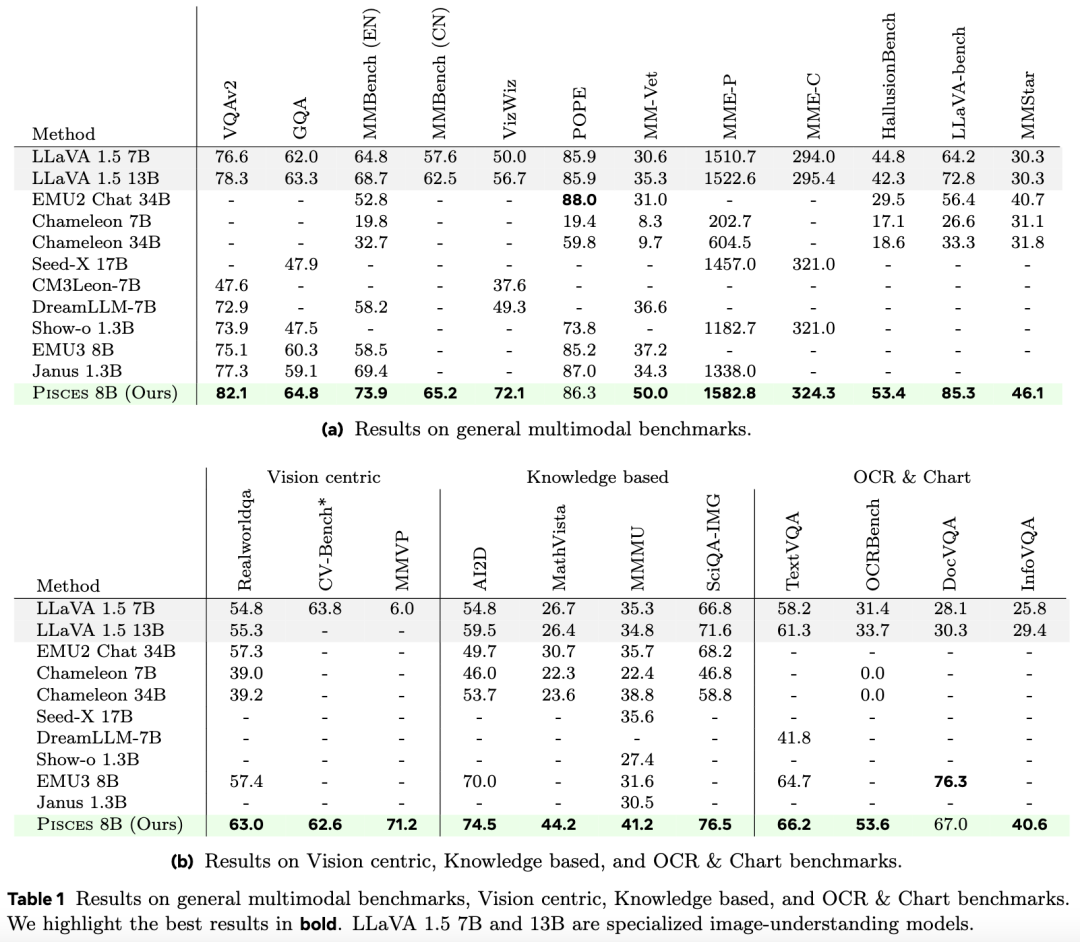
以视觉为中心、基于知识及OCR与图表基准:在表1b(b)中展示了Pisces在领域特定基准上的结果。可以看出,与开源统一模型相比,本文的模型在大多数任务上实现了最佳性能,甚至与专精于理解的强模型相比也取得了相当的性能。
条件图像生成
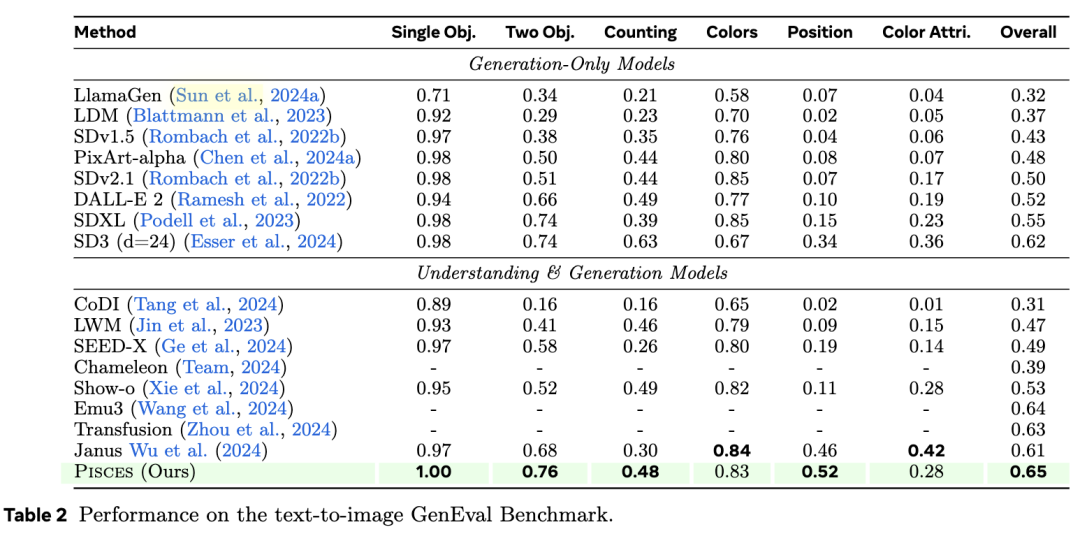
下表2中展示了Pisces在GenEval基准上的表现。值得注意的是,Pisces在GenEval上实现了与统一理解和生成模型相竞争的性能,突显了其在图像生成中强大的指令跟随能力。下图3中展示了Pisces与具有图像生成能力的统一模型之间的定性比较。可以看出,Pisces能够遵循复杂的用户提示生成高质量图像。

讨论
图像理解与图像生成的协同关系
在统一模型架构中图像理解与图像生成是否能相互促进。由于计算资源限制,从训练阶段1使用的数据中采样1500万图像-详细标题对用于预训练。指令调优阶段使用LLaVA-Instruct-150K数据集。本文在三种不同数据设置下训练模型变体:
-
PISCES:同时使用图像理解和生成数据进行预训练,后在LLaVA-Instruct-150K上指令调优; -
PISCES w/o Und:仅使用Shutterstock数据集预训练; -
PISCES w/o Gen:使用PixelProse数据集预训练并在LLaVA-Instruct-150K上微调。训练时保持两个图像编码器冻结,学习率设为,采用带warm-up的余弦衰减调度器(warm-up比例0.03),batch size为1024。
如下表3所示,在受限训练数据设置下,图像理解显著提升图像生成能力,反之亦然。这证实了两种任务间的协同关系。

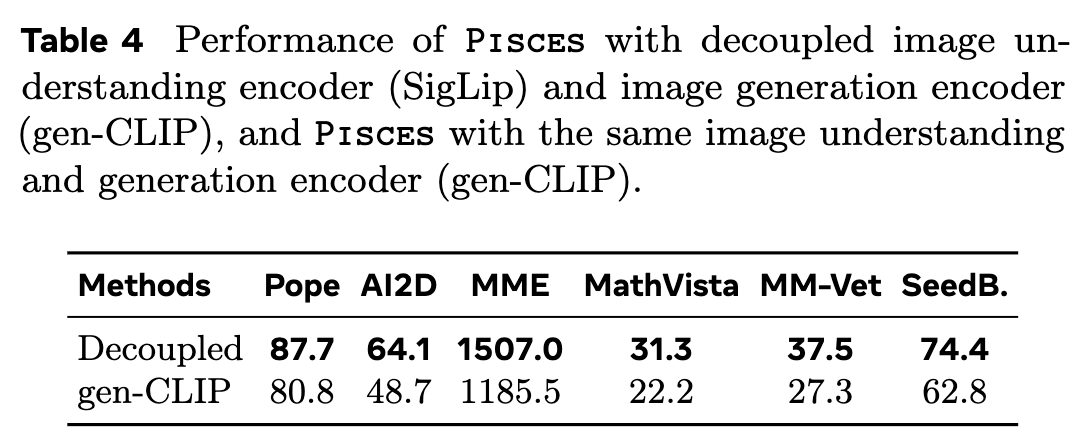
解耦视觉编码器的优势
本文通过消融实验验证解耦编码器的有效性:
-
使用gen-CLIP同时处理图像理解(1024个视觉token)和生成(池化为64个视觉token)。结果显示Pisces-gen-CLIP在生成任务上与原模型相当(FID 40.5 vs 38.2),但理解性能下降(下表4);
-
尝试使用SigLIP处理双任务时,尽管用3000万Shutterstock图像训练SDXL解码SigLIP特征,但由于SigLIP预训练缺少MAE损失,其重建性能不及Gen-CLIP+SDXL组合。这印证了为不同任务采用独立编码器的必要性。
图像生成视觉token数量的影响
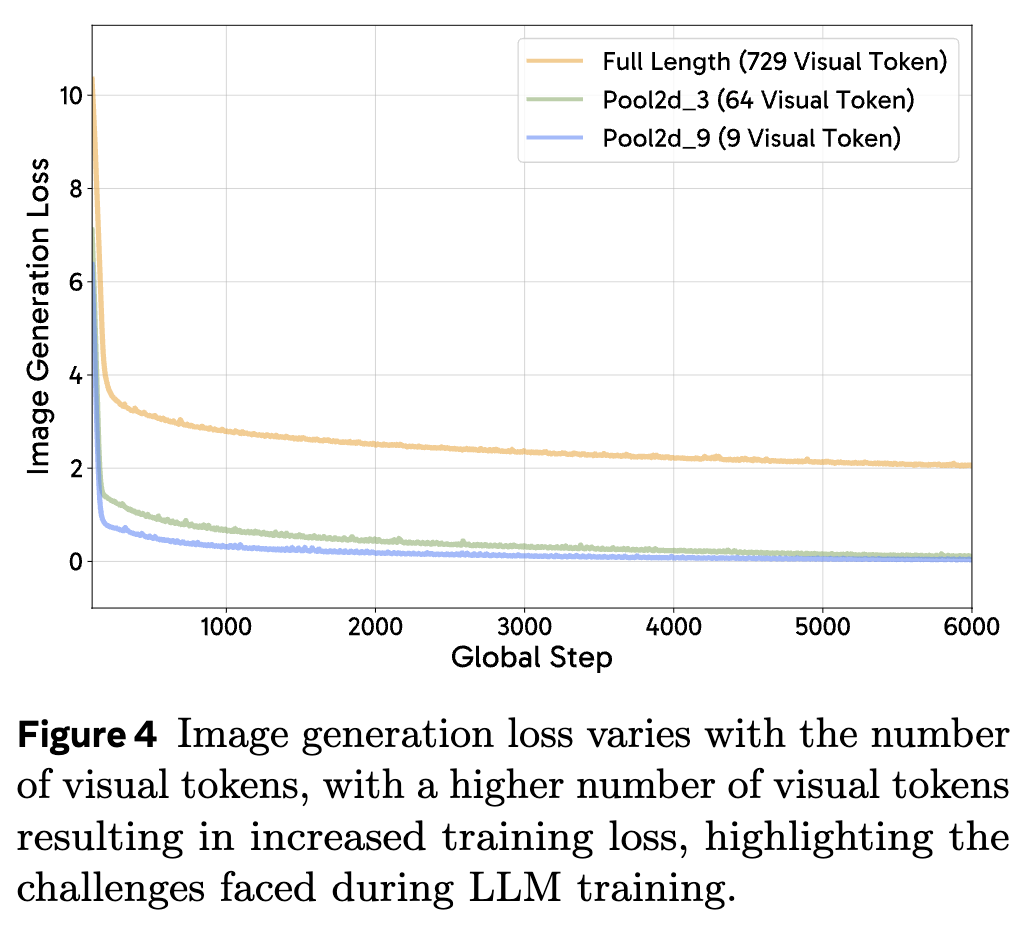
在图像生成任务中,LLM以自回归方式预测连续图像向量。实验采用SigLIP ViT-L/16@384,比较完整序列长度(729个token)与两种池化策略(步长3得81个token,步长9得9个token)。如下图4所示,完整序列训练损失最高,步长3取得平衡,而步长9虽损失最低但信息丢失严重导致生成质量下降。
详细标题对图像生成的影响
本文对比了两种第二阶段预训练设置:
-
使用7000万详细标题同时增强生成和理解能力; -
生成任务使用7000万简短标题,理解任务使用详细标题。
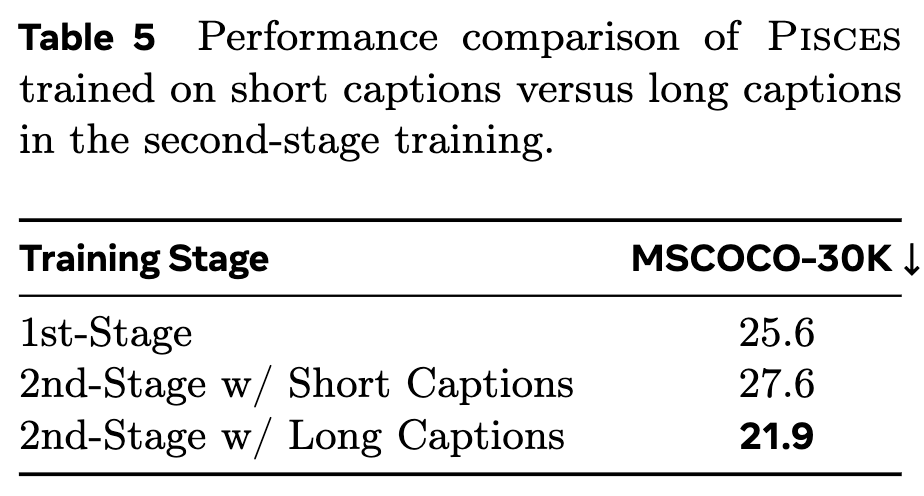
下表5显示MSCOCO-30K的FID分数表明,长标题能持续提升生成性能,而增加短标题则无进一步改善。
参考文献
[1] Pisces: An Auto-regressive Foundation Model forImage Understanding and Generation
(文:极市干货)