

编辑:杜伟、Panda
在国产大模型领域,华为盘古大模型一直是比较独特的存在。
该系列模型强调「不作诗,只做事」,深耕行业,赋能千行百业,推动产业智能化升级。从盘古 1.0 到盘古 5.0,华为专注于用大模型解决实际产业问题,并获得了市场的广泛认可。
就在刚刚,在华为开发者大会 2025(HDC 2025)上,华为重磅发布了盘古大模型 5.5,其中自然语言处理(NLP)能力比肩国际一流模型,并在多模态世界模型方面做到全国首创。
此次,全新升级的盘古大模型 5.5 包含了五大基础模型,分别面向 NLP、多模态、预测、科学计算、CV 领域,进一步推动大模型成为行业数智化转型的核心动力。

华为常务董事、华为云 CEO 张平安正式发布盘古大模型 5.5
会上,华为诺亚方舟实验室主任王云鹤对该系列模型的核心技术进行了大揭秘。

王云鹤
此次,盘古 5.5 在 NLP 领域主要有三大模型组成,即盘古 Ultra MoE、盘古 Pro MoE、盘古 Embedding;以及快慢思考合一的高效推理策略、盘古深度研究产品 DeepDiver。
我们接下来一一来看。
盘古 Ultra MoE
准万亿级别模型
盘古 Ultra MoE 是 7180 亿参数的 MoE 深度思考模型。作为一个准万亿参数级别的大模型,该模型基于昇腾全栈软硬件协同打造,做到了国内领先、比肩世界一流水平。

训练超大规模和极高稀疏性的 MoE 模型极具挑战,训练过程中的稳定性往往难以保障。针对这一难题,华为盘古团队在模型架构和训练方法上进行了创新性设计,成功地在基于昇腾 NPU 打造的「下一代 AI 数据中心架构」CloudMatrix384 集群上实现了准万亿 MoE 模型的全流程训练。
具体来讲,盘古团队提出了 Depth-Scaled Sandwich-Norm(DSSN)稳定架构和 TinyInit 小初始化的方法,在昇腾 NPU 上实现了 10+T token 数据的长期稳定训练。此外,华为还提出了 EP group loss 负载优化方法,这一设计不仅保证各个专家之间能保持较好的负载均衡,也提升专家的领域特化能力。同时,Pangu Ultra MoE 使用了业界先进的 MLA 和 MTP 架构,在训练时使用了 Dropless 训练策略。
得益于此,该模型具备了高效长序列、高效思考、DeepDiver、低幻觉等核心能力,并在知识推理、自然科学、数学等领域的大模型榜单上位列前沿。
更多技术细节可访问盘古 Ultra MoE 的技术报告或我们之前的报道《还得是华为!Pangu Ultra MoE 架构:不用 GPU,你也可以这样训练准万亿 MoE 大模型》:

报告地址:https://arxiv.org/pdf/2505.04519
盘古 Pro MoE 大模型
比肩 DeepSeek-R1
盘古 Pro MoE 是一个 72B A16B 的模型,即每次工作时会激活其中 160 亿参数。

王云鹤透露,该模型也代表盘古系列模型首次参与了外部打榜。在刚刚发布的五月底 SuperCLUE 榜单上,盘古 Pro MoE 在千亿参数量以内的模型中,排行并列国内第一。

https://www.superclueai.com
可以看到,其在智能体任务上打榜成绩甚至比肩 6710 亿参数的 DeepSeek-R1,在文本理解和创作领域也达到开源模型的第一名。
据介绍,该模型是针对昇腾硬件特性进行了大量仿真建模之后得到的最优架构,尤其适配 300I Duo 推理芯片的宽度、深度、专家数等。
此外,华为还针对不同芯片上专家负载不均衡的问题,提出了分组混合专家 MoGE 算法。该算法可实现跨芯片计算的负载均衡,从而显著提升盘古训推系统的吞吐效率。
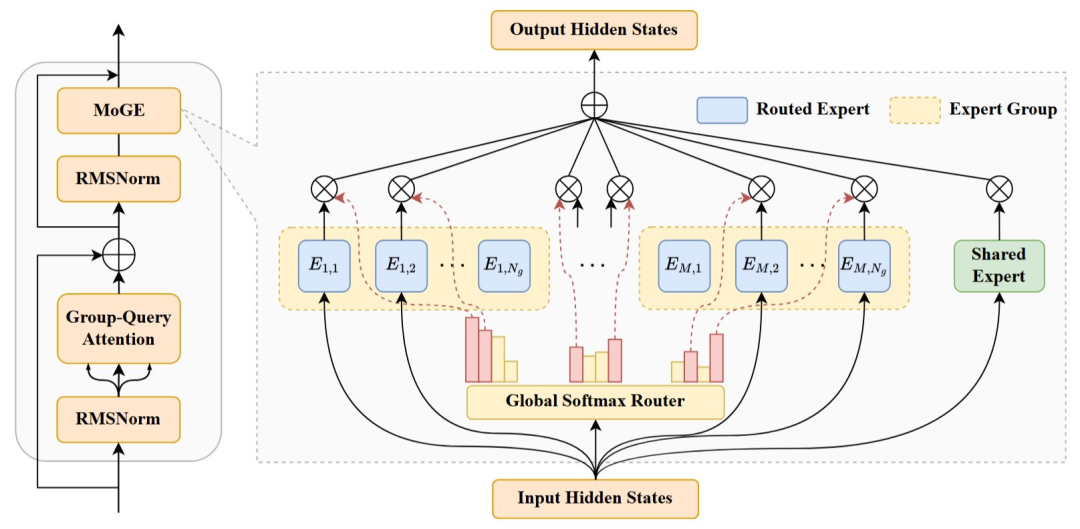
MoGE 架构设计示意图。N 个专家被均匀划分为 M 个不重叠的组并且每一个组内激活相同数量的专家。
最终,这些创新让盘古 Pro MoE 可在 300I Duo 上实现每秒 321 token 的吞吐量,而在性能更强大的 800I A2 上,吞吐速度更是可达每秒 1529 token,领先同规模业界模型 15% 以上。
华为已经在 5 月底发布了盘古 Pro MoE 的技术报告,感兴趣的读者可通过以下链接扩展阅读。另外,我们之前也已经报道过该模型:《华为盘古首次露出,昇腾原生 72B MoE 架构,SuperCLUE 千亿内模型并列国内第一》。

项目地址:https://gitcode.com/ascend-tribe/pangu-pro-moe
盘古 Embedding(7B)
小身手、大能量
华为也推出了一个相当能打的 7B 级小模型盘古 Embedding。该模型在学科知识、编码、数学和对话能力方面均优于同期同规模模型。
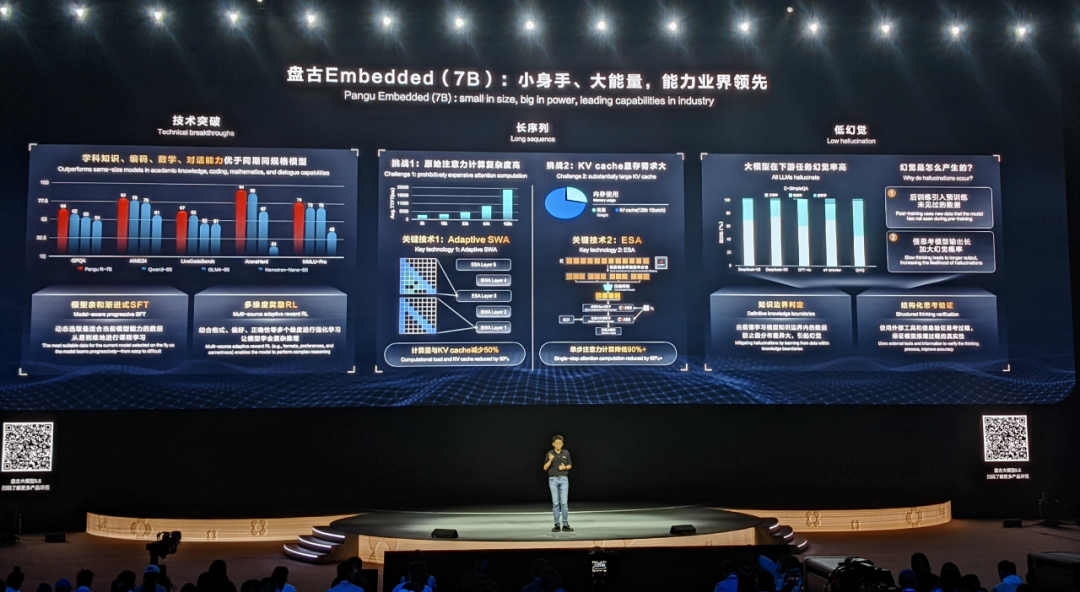
华为是如何做到这一点的呢?王云鹤介绍了一些重点:
-
在后训练阶段使用渐进式 SFT 和多维度奖励的强化学习,这提高了模型的推理能力。
-
针对长序列进行了重点优化,为此华为提出了 Adaptive SWA 和 ESA 两项关键技术来降低在长序列的场景中的计算量和 KV Cache;也由此,盘古 Embedding 可以相当轻松地应对 100 万 token 长度的上下文。
-
针对幻觉问题,华为提出了知识边界判定、结构化思考验证等创新方案,从而实现了模型推理准确度的提升。
同样地,该模型的技术报告也已经在 5 月底发布。

报告地址:https://arxiv.org/pdf/2505.22375
高效推理方案
自适应快慢思考合一
如今,以 DeepSeek-R1 为代表的思考模型受到了业界的广泛关注。思考模型又可以分为慢思考模型与快思考模型,其中慢思考模型普遍存在的过度思考问题受到了业界的广泛关注。
对于简单的问题(比如 1+1 等于几),快思考模型平均只需要十几个 token 就能解决,而慢思考却需要几百甚至上千个 token。这就导致用户体验不佳,对于行业应用部署也有不利影响。目前业界已有的一些方案通过 prompt 隔离进行切换,但这样做并不能真正地自动感知问题的难易程度。
为解决该问题,华为提出了自适应快慢思考合一技术,构建难度感知的快慢思考数据并提出两阶段渐进训练策略,让盘古模型可以根据问题难易程度自适应地切换快慢思考。这就达成了这样一种效果:简单问题快速回复,复杂问题深度思考,整体推理效率可以提升高达 8 倍。

不仅如此,华为还针对慢思考模式提出了反思投机和反思压缩等策略,在精度无损的情况下减少 50% 的慢思考时间,让盘古大模型不仅推理得准,速度还快。
盘古 DeepDiver
华为的 Deep Research 来了
进入到 2025 年,大模型的基础能力不再是厂商关注的唯一,模型应用同样受到高度重视。
其中,以深度研究(Deep Research)为代表的新一代 Agent 在科学助手、个性化教育以及复杂的行业报告调研等场景展现出了比传统大模型更强的能力。
不过,这类 Agent 在实际应用中面临着很多技术挑战,比如规划步数多、策略空间大、序列超长、信息噪声大等,这些不可避免地影响到执行效率和准确率。
针对这一挑战,华为发布了开放域信息获取 Agent—— 盘古 DeepDiver,在网页搜索、常识性问答等应用中,它可以让盘古 7B 大模型实现接近 DeepSeek-R1 这种超大模型的效果。

如何做到的呢?据王云鹤介绍,首先根据实际场景构建大量的合成交互数据,并通过渐进式奖励策略等优化方法,在开放环境进行强化学习训练。
效果不俗之外,执行效率也非常高,盘古 DeepDiver 可以在 5 分钟内完成超过 10 跳的复杂问答,并生成万字以上的专业调研报告。
得益于 DeepDiver,盘古大模型的自主规划、探索、反思等高阶能力得到了前所未有地加强。
更多技术细节请访问相应技术报告或我们之前的报道《真实联网搜索 Agent,7B 媲美满血 R1,华为盘古 DeepDiver 给出开域信息获取新解法》。

报告地址:https://arxiv.org/pdf/2505.24332
除了以上几大 NLP 大模型之外,盘古 5.5 还覆盖了以下几个领域的大模型:
-
盘古预测大模型:采用业界首创的 triplet transformer 统一预训练架构,将不同行业的数据进行统一的三元组编码,并在同一框架内高效处理和预训练,极大地提升预测大模型的精度,并大幅提升跨行业、跨场景的泛化性。
-
盘古科学计算大模型:华为云持续拓展盘古科学计算大模型与更多科学应用领域的结合。比如深圳气象局基于盘古进一步升级「智霁」大模型,首次实现 AI 集合预报,能更直观地反映天气系统的演变可能性,减少单一预报模型的误差。
-
盘古计算机视觉 CV 大模型:华为云发布全新 MoE 架构的 300 亿参数视觉大模型,这是目前业界最大的视觉模型,并全面支持图像、红外、激光点云、光谱、雷达等多维度、泛视觉的感知、分析与决策。另外盘古 CV 大模型通过跨维度生成模型,构建油气、交通、煤矿等工业场景稀缺的泛视觉故障样本库,极大地提升了业务场景的可识别种类与精度。
-
盘古多模态大模型:全新发布基于盘古多模态大模型的世界模型,可以为智能驾驶、具身智能机器人的训练,构建所需要的数字物理空间,实现持续优化迭代。例如,在智能驾驶领域,输入首帧的行车场景、行车控制信息和路网数据,盘古世界模型就可以生成每路摄像头的行车视频和激光雷达的点云,能够为智能驾驶生成大量的训练数据,而无需依赖高成本的路采。
至此,盘古大模型 5.5 通过多样化的架构与算法创新(如 MoE、深度思考、Triplet Transformer、自适应快慢思考),不仅在核心技术能力上达到领先水平,更在科学计算、工业预测、气象预报、能源优化、智能驾驶等关键应用领域展现出强大的落地价值和变革潜力。
©
(文:机器之心)