

今天是2025年6月23日,星期一,北京,晴
我们继续来看GraphRAG的趋势,谈谈自己的一些想法,也是周末的思考,做个分享。
之前在《多模态GraphRAG的一点思考:兼看多模态大模型用于数据增强总结》(https://mp.weixin.qq.com/s/c4JHBqiXpkQqU11VJoO6mw)中,我开始做了一些思考。
而到后面,随着文档解析方面工作的陆续开展,针对文档本身可以做的事情越来越多,所以,我们可以进一步提出一个更为成熟的点,叫做文档为中心多模态GraphRAG,底层依赖的知识库叫做MultimodalDocGraph。
当然,这个事情很容易做工程实现,所以自然可以看一个工程的实现项目,看了下代码,也看看。
一、文档为中心的多模态GraphRAG及MultimodalDocGraph
为什么要说这个多模态GraphRAG,尤其是面向文档场景,或者以文档为核心的GraphRAG,这是我们在实际落地过程中所遇到的一个难题例子,文档在进行表述时候,图表会作为一个链接元素被引用于文本描述当中,在RAG中常常会出现这类情况:一个问题召回出来的片段里,有xxxxxx,详见表1。这种问题本质上属于多跳情况。

所以,如上所述,解决方式,采用与知识图谱Entity-linking的方式,在原文中进行图表的链接。【但不局限于文图,通常还包括reference参考的链接】,这样能够将不同的模态之间联系起来,然后能够找回更为完整的信息,提升RAG检索性能。
所以,当时我想,索性是否直接可以有个Multimodal GraphRAG的概念,在Graph的基础上,进一步将Graph中的节点元素扩展到多模态元素。
对于具体定义,我们可以定一下:多模态GraphRAG(Multimodal Graph Retrieval-Augmented Generation)是一种结合图结构推理、多模态数据融合与检索增强生成的前沿技术,旨在解决复杂场景下的语义理解与生成问题。
其核心在于通过图结构显式建模跨模态实体关系,提升RAG的性能,而其中最为重要的是这个是个重点,需要将不同模态的信息组织起来。
例如,医学实体“肺癌”关联CT图像、病理报告文本和患者语音描述,在节点类型设计上,可以设计实体节点(如“肺癌”)、属性节点(如“发病率”)、模态节点(如CT图像哈希值);边类型的设计上,包括语义关系(“治疗”“属于”)、模态关联(“图像描述”“音频注释”)。
就拿文档这个场景来讲,其通过解析,可以拿到图片、表格、段落、公式、代码块、参考文献等各式各样的元素,尤其是其中的图片或者公式,其实很自然地就成为了多模态知识库的构建要素,对于图片,可以增加对图片的summary或者 caption描述,对于公式也可以进一步解读,对于表格,也可以增加对其结构信息的描述文本。
而进一步的,通过将图片、表格、公式等进行文本化后,有可能基于这个做实体抽取跟关系抽取,这样一来,就可以形成一个以文档为核心的多模态知识图谱。
我提了个概念,MultimodalDocGraph,如下图所示,老刘绘制的一个MultimodalDocGraph,其等于DocGraph+entityGraph,这是实现RAG的一个前提,文档多模态RAG的一个范式。
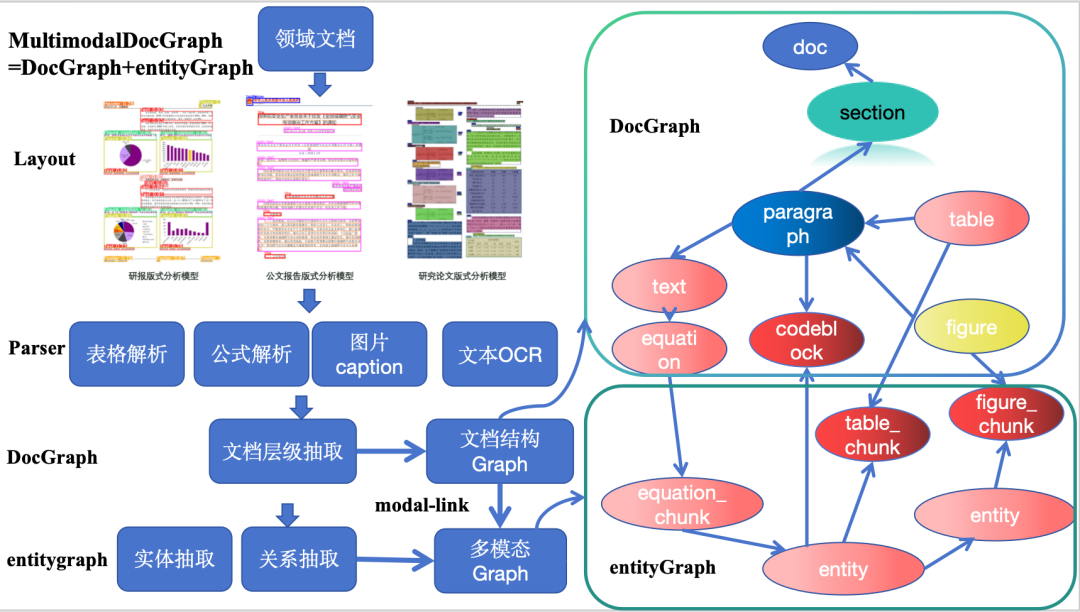
实体可以是chunk、modal_entity、entity,chunk表示文本段落、modal_entity 可以是多模态实体(图片、表格图、公式、图表、section、paragraph等),entity是经过信息抽取得到的实体实体(典型的spo中的s或者 o)
关系可以是:<entity, rel, entity>(例如,张三,媳妇儿,翠花), <entity, belongs_to, modal_entity>(铁矿石, belongs_to, 铁矿石图片base64), <chunk, related_to, modal_entity>(“赣州是江西的南大门”, related_to, 赣州卫星图片base64), <entity, locate_in, chunk>(“赣州”, locate_in, “赣州是江西的南大门”),其中的rel,又可以进一步分成多种,比如层级结构的关系。
二、看一个开源的简易实现项目
说到上述的思想,其实是很容易撞车的,很容易想到,并且做出来,但具体效果怎样其实很难讲,但从代码端是很好实现的。
这里看一个实现的项目,叫RAG-Anything,https://github.com/HKUDS/RAG-Anything
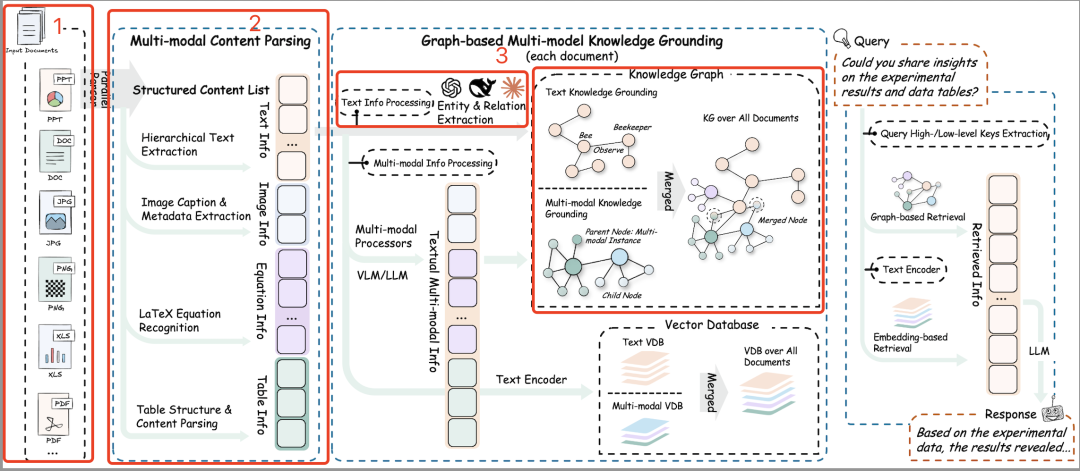
核心看几个点,看了下代码,讲几点:
1、总体结论如何?
1)文档处理方式很抽象,不合理,会慢死,有的改;
2)多模态图谱构建设计思路不错,考虑的很细,后续可以通过实体获取到图像信息,进而拿到图像描述信息,很好的link 思路。但这块会带来很多噪声,因为一个实体会存在多个图像对应关系,后续需要剪枝,这块收益很难讲【图像的收益未知,且依赖于多模态大模型的能力,容易出现幻觉,假设性很强】。
3)是个大框架,但很难讲是否有实际用处,可自行测试。
2、文档解析的逻辑怎么看?
文档解析中,文档处理的的具体执行逻辑其实有点为了统一处理而处理的目的(需要进一步思考)。
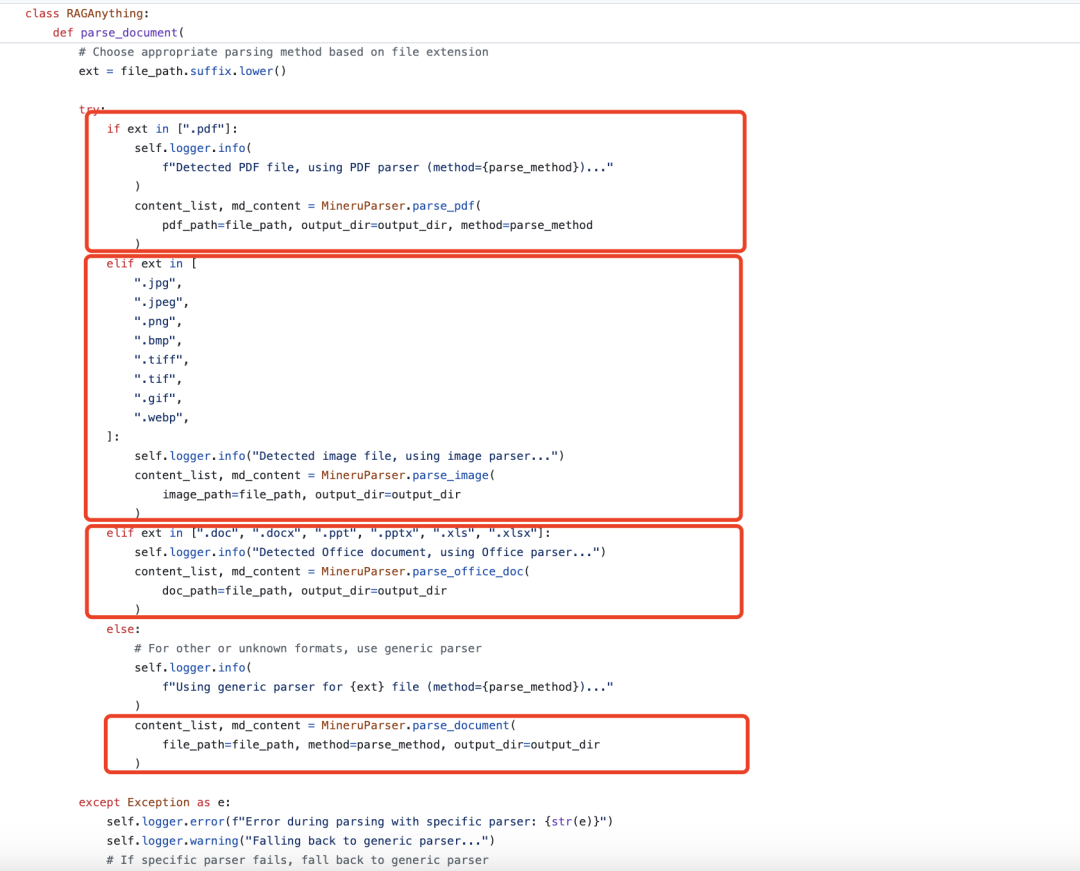
根据文件类型选择合适的解析器,如果文件是PDF格式,调用MineruParser.parse_pdf方法进行解析。
如果文件是图片格式,调用MineruParser.parse_image方法进行解析。如果文件是办公文档格式(如Word、PowerPoint、Excel),需要先转换为PDF,然后调用MineruParser.parse_office_doc方法进行解析。
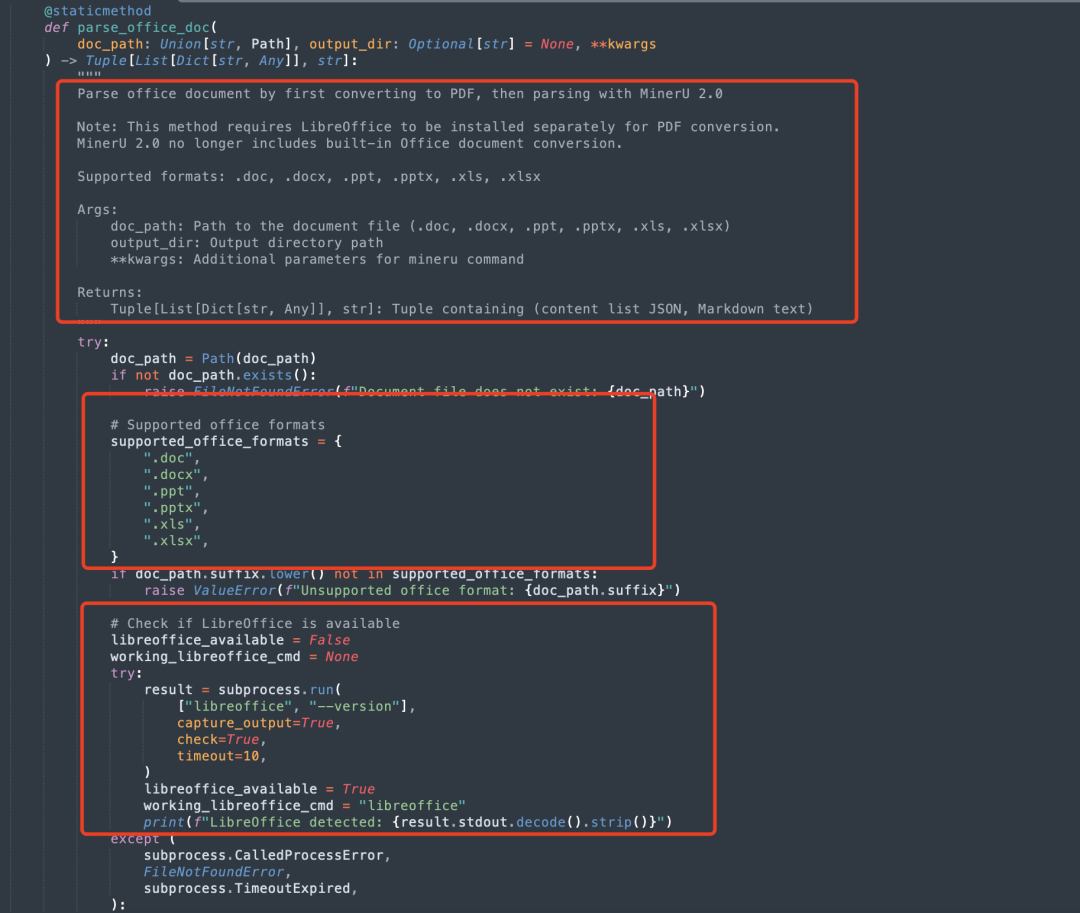
如果文件是文本格式(如.txt、.md),也是先转换成PDF,然后调用MineruParser.parse_text_file方法进行解析。
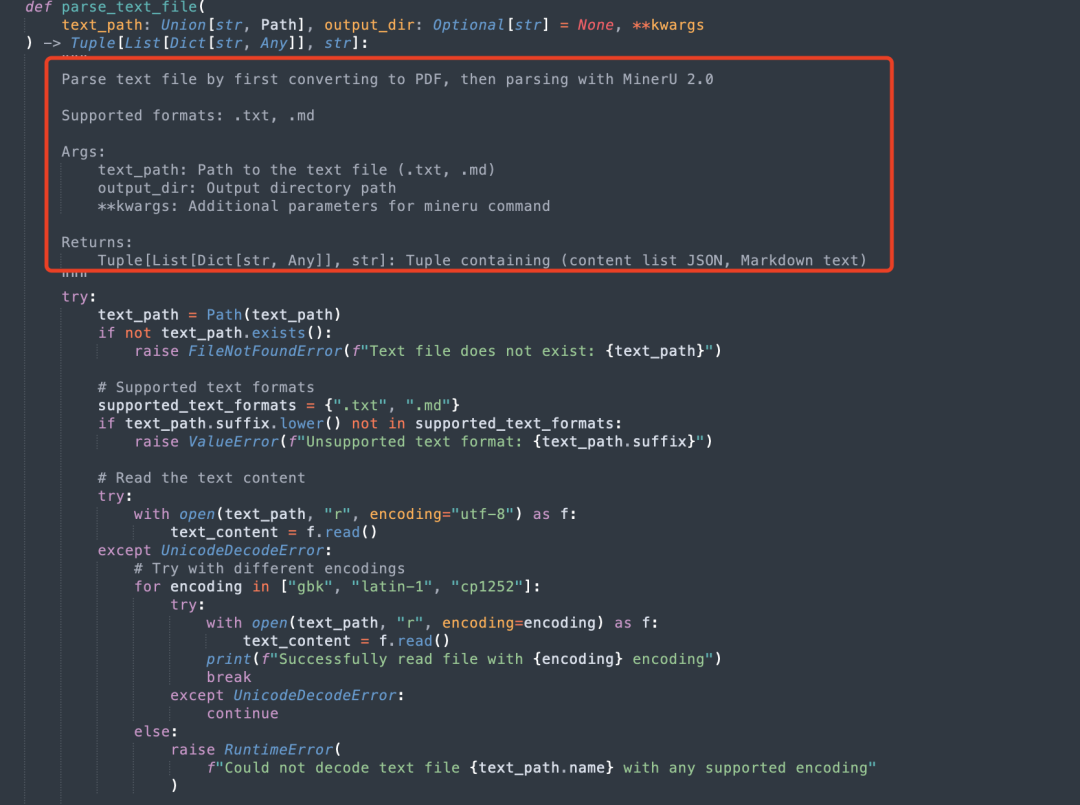
3、多模态元素解析流程怎么看?
用于处理不同类型的模态内容(如图像、表格、方程等),ImageModalProcessor 处理图像内容,需要将图像编码为base64格式;TableModalProcessor 处理表格内容,解析表格结构;EquationModalProcessor处理方程内容,解析方程文本。每个模态的prompt都旨在生成一个详细的描述和一个简洁的实体信息。
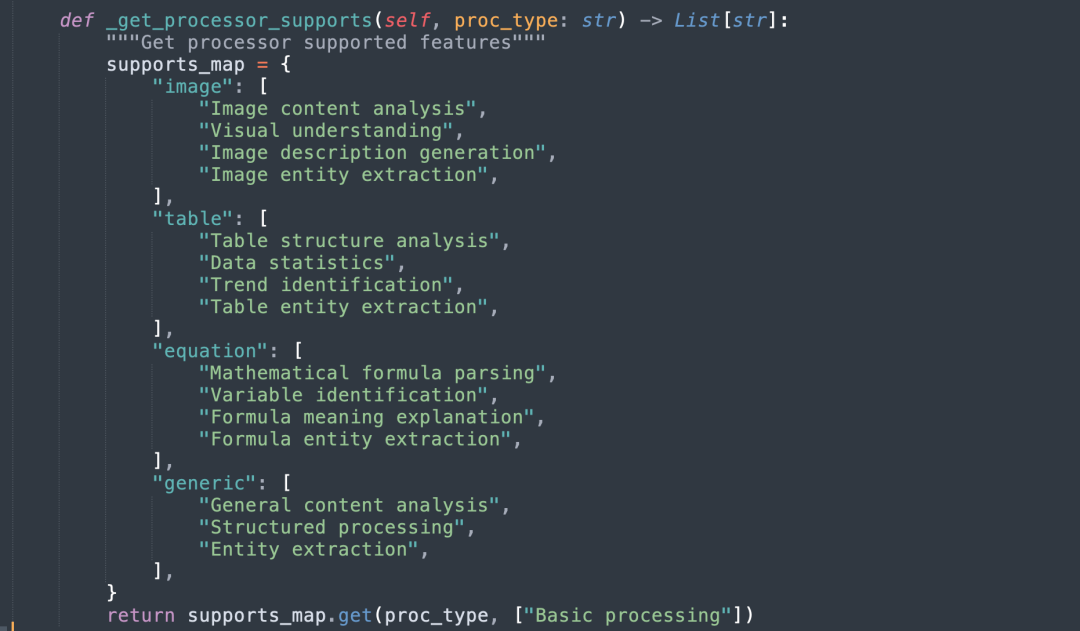
详细描述提供了对内容的全面分析,而实体信息则提供了一个简洁的总结,强调内容的重要性和目的。这些内容将被存储到知识图谱和向量数据库中,以便后续的知识检索和分析。
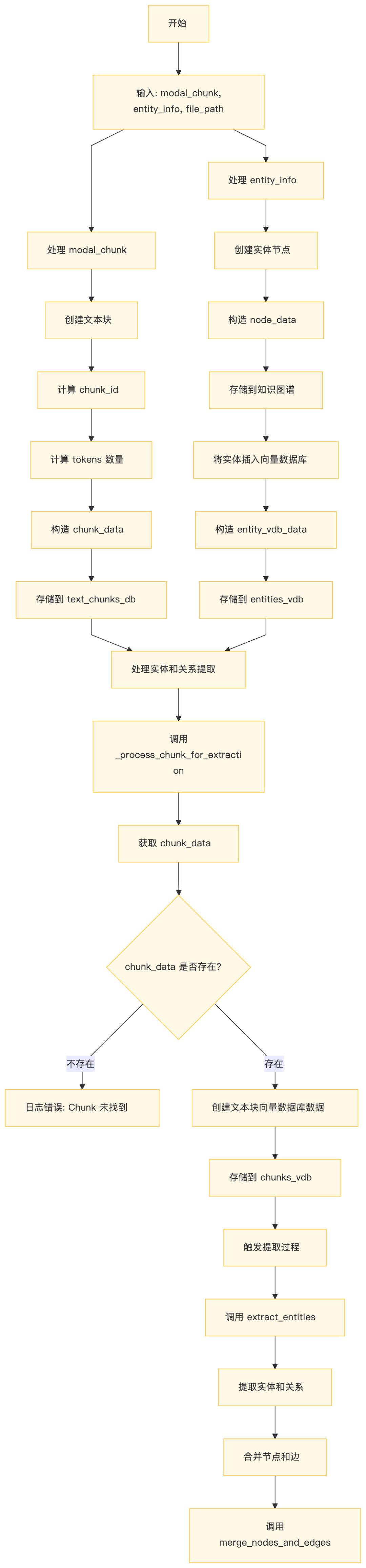
4、chunk 切分及图谱构建怎么看?
纯文本部分进行实体、关系抽取,构图。多模态部分利用对应要素作为chunk 提取实体和关系,然后为每个提取到的实体(entity_name)与“模态实体”(modal_entity_name)建立“属于”关系。
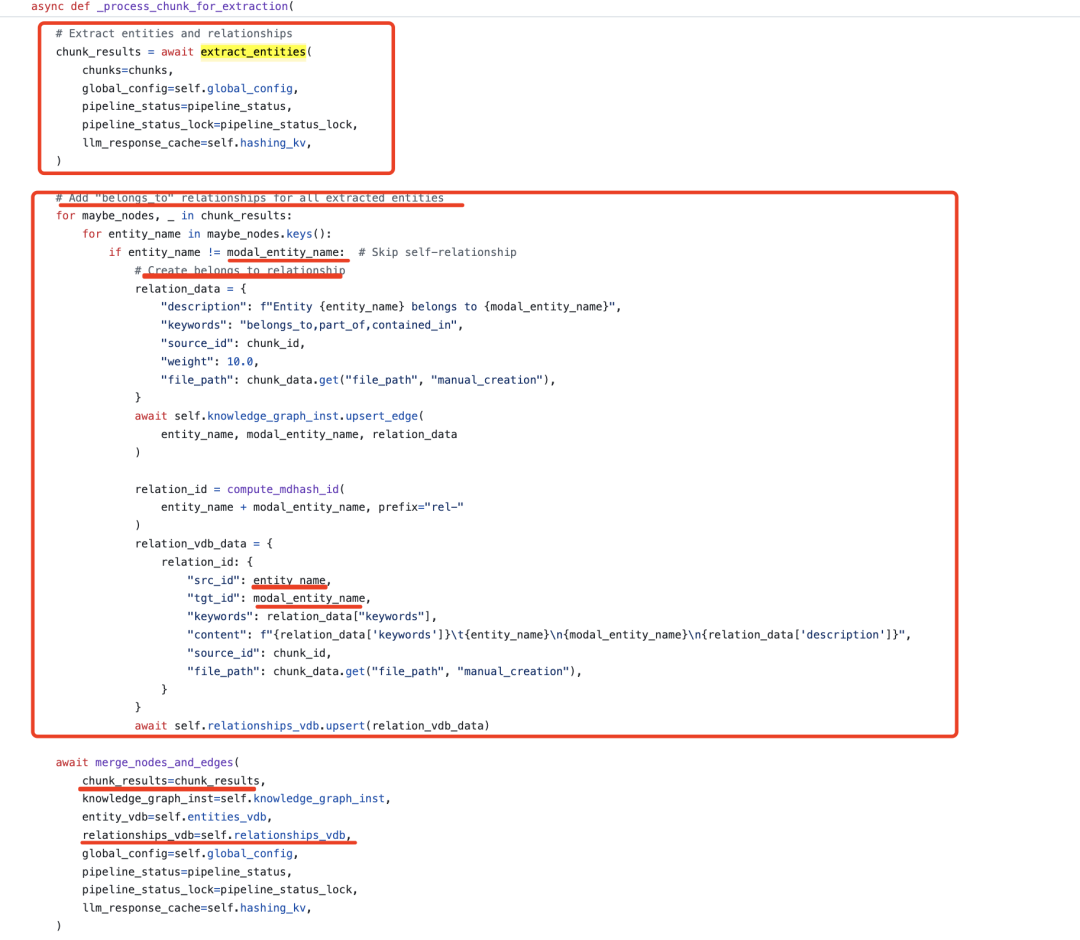
最终构成chunk、modal_entity、entity 三种实体、<entity, rel, entity>, <entity, belongs_to, modal_entity>, <chunk, related_to, modal_entity>, <entity, locate_in, chunk>4 种关系的图谱。
总结
文档为中心的多模态GraphRAG及MultimodalDocGraph是个很好的故事,这个可以讲一个比较好的故事,多模态、kg、文档解析、rag都通了。
(文:老刘说NLP)