

今天是2025年6月27日,星期五,重庆,晴
我们来看两个问题。
一个是Agent,看看推理大模型规划能力搭建Agent应用的一些变化,那些是稳妥、次稳妥、激进的思路。
一个是技术侧看文档智能,主要看多模态大模型的分辨率处理策略,看目前有哪些主流应对方案。
一、Agent应用搭建的5个问题
Agent的东西已经讲了很多了,Agent已经成为互联网的新流量入口。我们站在现在众多智能体产品,如manus,百度心响、天工超级智能体等节点上,再来看看这个问题。
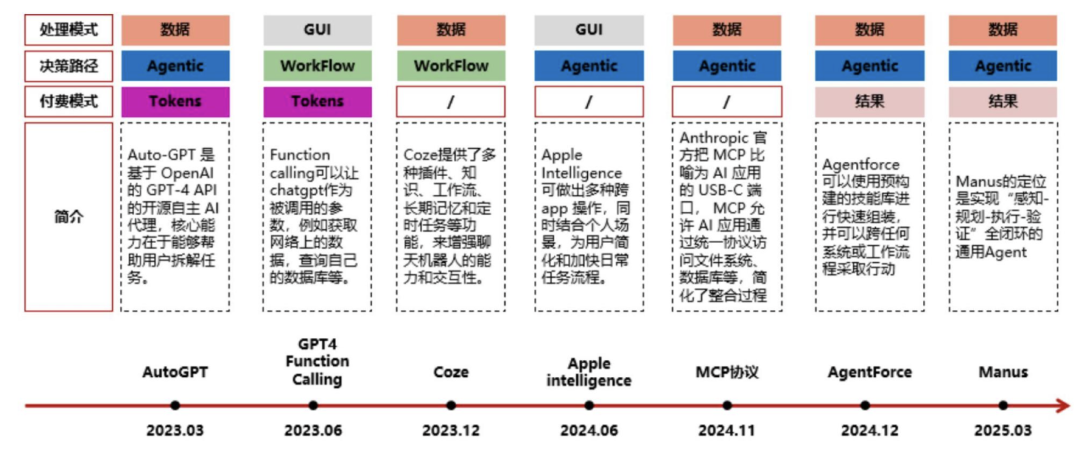
1、Agent的构成跟核心?
LLM是Agent的大脑,其核心能力是 “逻辑推理 ”,其中包括多个部件
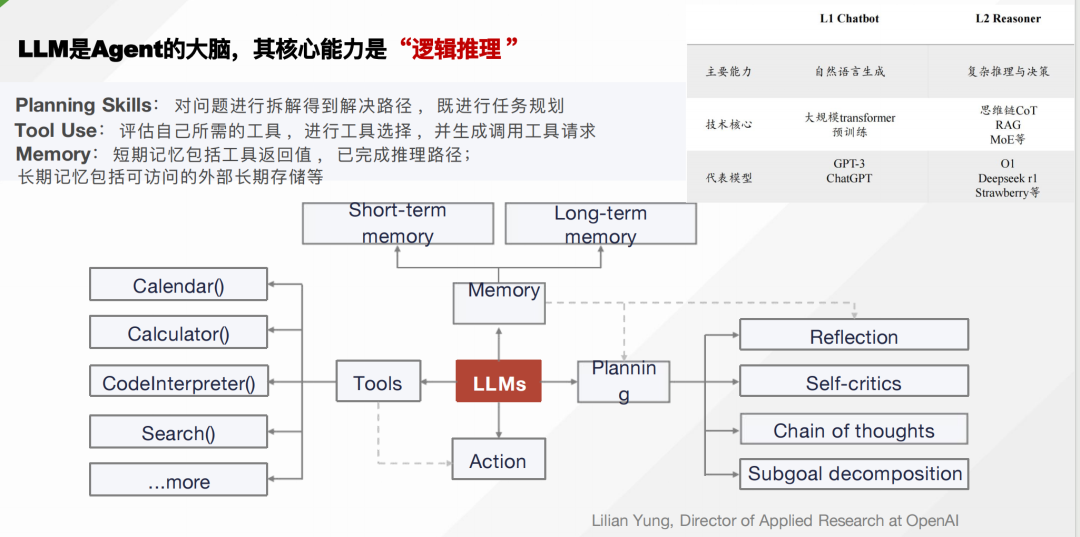
Planning Skills:对问题进行拆解得到解决路径 ,既进行任务规划; Tool Use:评估自⼰所需的工具,进行工具选择 ,并生成调用工具请求;
Memory:短期记忆包括工具返回值,已完成推理路径;
长期记忆包括可访问的外部长期存储等。
2、Agent研发的实际窘境?
Deepseek等大模型的能力持续快速提升,带动AI智能体的能力提升。
但是,现在依旧存在多个问题,例如:
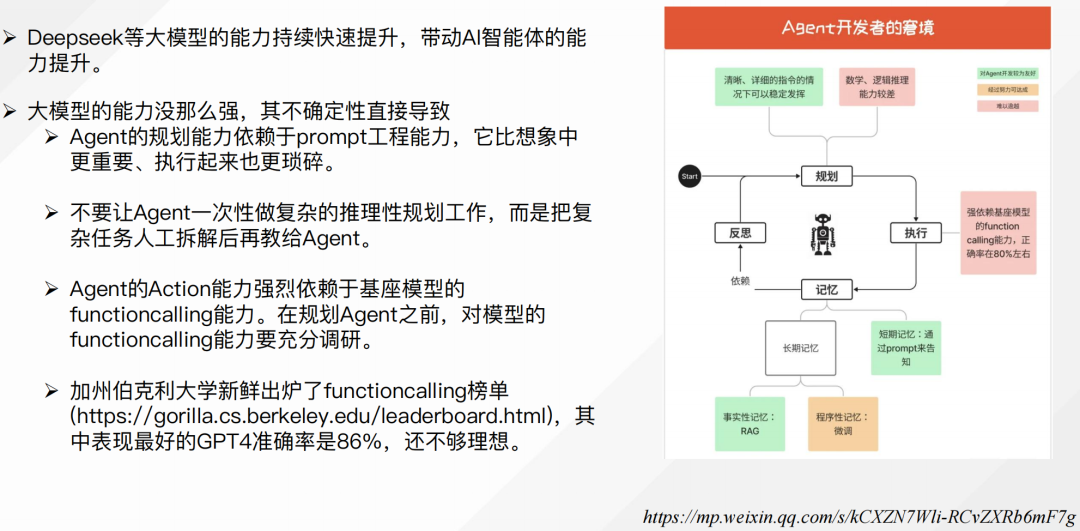
大模型的能力没那么强,其不确定性直接导致;Agent的规划能力依赖于prompt工程能力,它比想象中更重要、执行起来也更琐碎;不要让Agent一次性做复杂的推理性规划工作,而是把复杂任务人工拆解后再教给Agent;
Agent的Action能力强烈依赖于基座模型的 functioncalling能力。在规划Agent之前,对模型的functioncalling能力要充分调研;
3、Agent开发的最稳妥路线-低代码平台Agent?
既然大模型能力不行,那么就直接把大模型当啥子好了,不让它做规划,只让他做一个单点的执行,但这种做法做出来的,与Agent的初衷背道而驰。
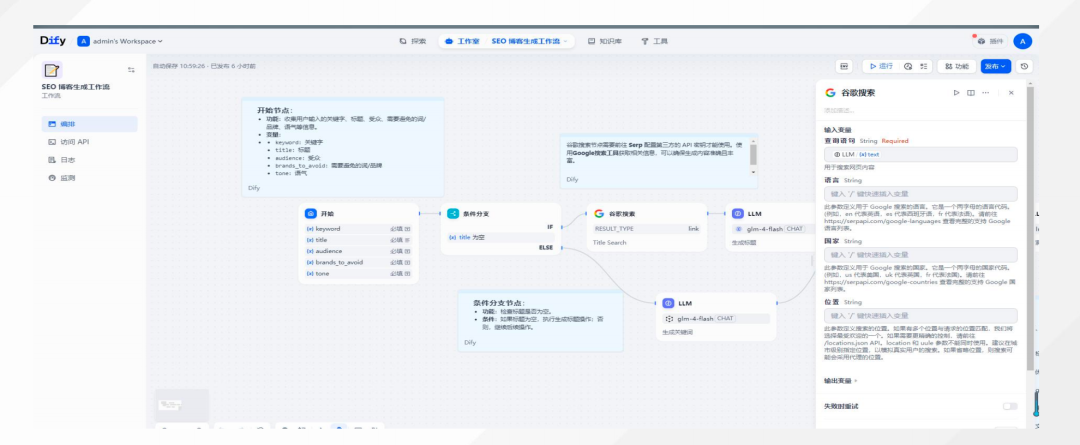
最稳妥的Agent开发范式,就是人工定义好实现流程,低代码平台开发,例如,Dify应用开发平台,多模型支持、可视化工作流设计、检索增强生成(RAG)、API 接口与 SDK、数据与监控等核心功能,适用于企业知识管理、智能客服与问答系统、代码助手、自动化办公等场景。
4、Agent开发的次稳妥路线-交互型平台Agent?
最稳妥的Agent开发范式,就是人工定义好实现流程,低代码平台开发。但这个太慢,是否可以做个折中?
其实是可以的,这个也是一个趋势,
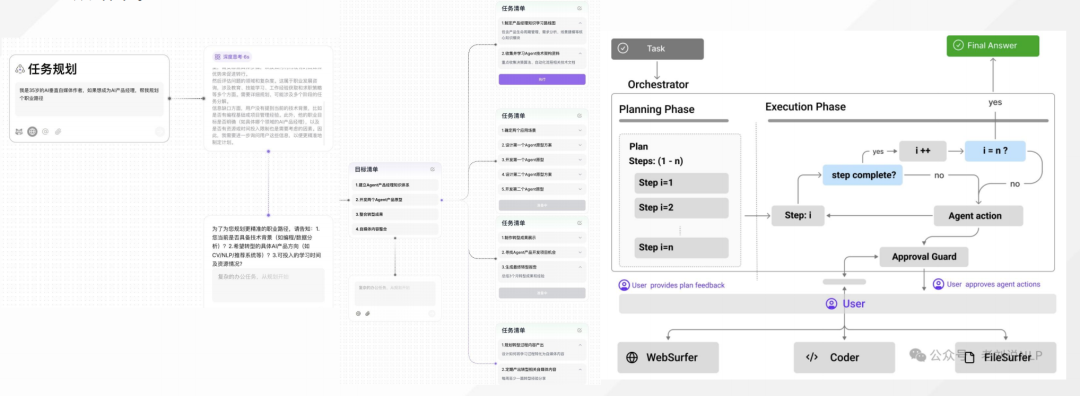
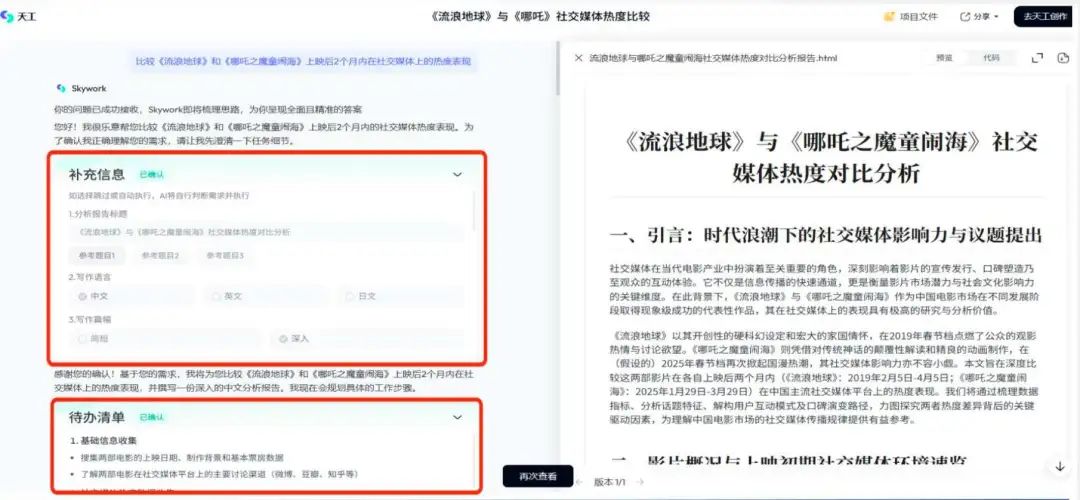
实现方式:每一步出llm结果,人工编辑确认执行。对于用户不清楚的问题,llm以多轮追问的方式进行引导->用户确认,迭代至意图信息完整,然后再最终生成结果,例如如下天工智能体的人工接入补充信息的中间过程:
5、Agent开发的激进路线-纯自动平台Agent?
激进路线,就是全放开让大模型去做Agent,但这块容易受到通用性的挑战,也需要做大量的prompt工程或者流程设计,例如manus等为代表。

这个不是很可控,并且很容易陷入死循环,或者耗费大量token。
二、视觉大模型的图片分辨率策略有哪些?
现在视觉多模态模型,尤其是在处理文档图像时,图像的分辨率的处理逻辑直接影响模型效果,这连同数据成为两个重要工程性工作。
很自然的想法,就是分辨率越高越好,但是其中的Transformer的注意力机制导致Token数量增加时计算量激增(如Qwen2-VL处理4K图像需16K Token),分块策略易丢失全局结构,无损缩放则计算成本高。
所以,目前也有一些新趋势。比如,渐进式分辨率思路,InternVL2从低分辨率开始训练,逐步过渡到高分辨率,或者采用多阶段微调方案,如LLaVA-UHD冻结视觉编码器,仅微调重采样器和LLM,缩短训练周期。
所以,当我们看现有的主流模型时候,可以挖掘出其中的一些典型处理措施。
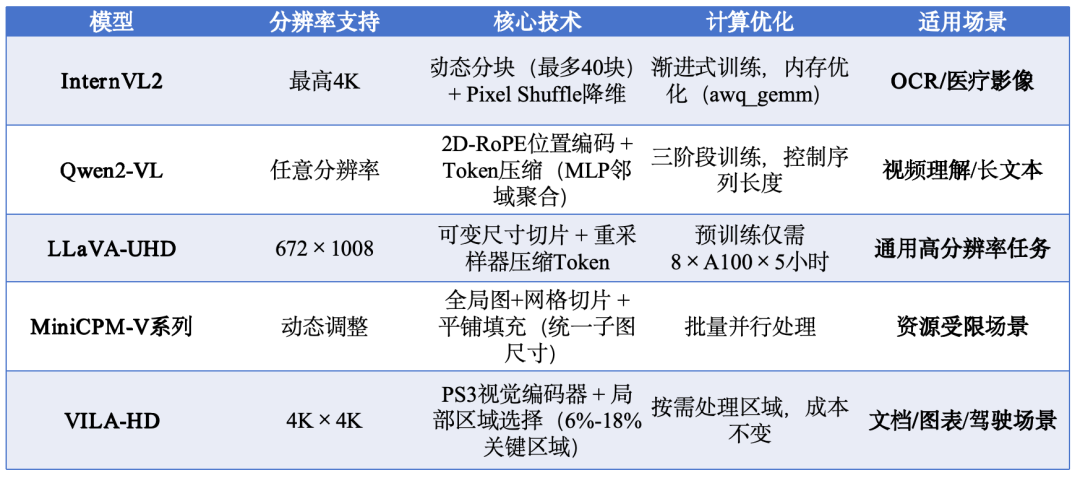
具体的:
1)InternVL2采用动态切块策略,将图像分割为多个448×448像素块,同时配合Pixel Shuffle技术降低计算量。
2)Qwen-VL通过Naive Dynamic Resolution机制,移除绝对位置嵌入改用2D-RoPE,实现任意分辨率处理。
3)LLaVA-UHD采用图像模块化策略,将高分辨率图像分割为可变大小的切片,并通过视觉Token压缩技术减少计算负担。这种方法能保持任意宽高比,避免信息丢失。
4)LLaVA-Next采用双分支处理(切图和缩放),同时保留全局语义和局部细节,实现动态高分辨率。
5)MiniCPM-V系列采用”全局缩略图+局部网格切片”方案,通过复杂的分块算法处理高分辨率图像;
6)Qwen2-VL则通过自适应缩放和维度重排直接处理原始图像,避免切割导致的信息断裂。
那么,是否可以再总结下,形成一些可用的策略?大致就是如下几种:
1)动态分块与切片(Patch Partition)策略
其思想在于将高分辨率图像分割为多个子图,分别编码后融合特征,避免整图缩放导致的细节丢失。
在具体实现上,主要包括自适应网格划分、全局缩略图补偿以及Token压缩几个实现步骤,例如:
自适应网格划分方面,根据图像宽高比动态计算最优分块数量(如m×n网格),确保子图宽高比接近预训练标准(如14的倍数)。
全局缩略图补偿方面,在分块基础上添加低分辨率全局图(如MiniCPM-V系列),保留整体结构信息,解决分块导致的语义割裂问题。
Token压缩方面,使用重采样器(如LLaVA-UHD的Q-Former)压缩子图Token,将可变长度视觉特征统一为固定长度,降低计算开销,这个主要冲着降低计算量去的。
2、无损自适应缩放(Resolution-aware Scaling)策略
无损自适应缩放的核心思想在于,直接处理原始分辨率图像,通过维度重排和缩放减少像素损失。
在具体实现上,主要包括如下几点:
一个是分辨率微调,例如Qwen2-VL将图像调整至28的倍数分辨率(如1365×2048 → 1372×2044),确保与视觉编码器的Patch机制兼容。
一个是动态Token生成,移除ViT的绝对位置嵌入,引入2D旋转位置编码(2D-RoPE),支持任意分辨率生成可变数量视觉Token(低至4个)。
3、 局部-全局特征融合(Hybrid Resolution Encoding)策略
局部-全局特征融合策略也是一种常用方式,其核心思想为,并行处理低分辨率全局特征和高分辨率局部特征,选择性融合关键信息。
而既然要用到全局信息和局部信息,因此,可以采用双分支编码器,如Mini-Gemini,一路编码低分辨率全局语义,另一路提取高分辨率局部特征,通过交叉注意力检索关键细节。
也可以采用多尺度特征池化,如S2-Wrapper,将不同尺度子图特征池化至统一空间尺寸并拼接,增强细节感知。
(文:老刘说NLP)