

强化学习与捷径思维
扮演着关键角色,它意味着越往后的决策步骤,所获得的奖励将会逐渐减少。因此,强化学习的目标通常是尽量以最短的时间和最少的步骤获得最大化的奖励。这种策略的核心,是强调「捷径」,即尽可能快速地得到回报。
为什么是 Reasoning?



为何 OpenAI 选择突破传统捷径?
o1 的突破:从探索到优化
-
OpenAI 花重金聘请在读博士生来标注 Long CoT 数据; -
没钱咋办?那就搞点人机协作标注数据(人工蒸馏 o1),降低对标注者的要求; -
连找标注者的钱都没有?那就只能去蒸馏 R1 / QwQ、或者想其他的办法(Critique、PRM 等)。
插一句题外话,虽然大家都在骂 o1 隐藏了真正的思维链,只展示 Summary 的捷径版本。殊不知这个 Summary 才是优化策略的关键数据!但 OpenAI 并不害怕其他人蒸馏这些 Summary,因为蒸馏这些数据还有一个前提——基础模型的能力足够强大,不然步子迈太大还容易闪了腰。
并且 OpenAI 还将探索的成本转嫁给了用户。虽然在初期花很多钱来标注探索型数据,但现在有了 o1 后,用户使用的过程中又无形地为他标注了更多数据。OpenAI 再次实现了伟大的数据飞轮!
o1 到 o3 的快速进化
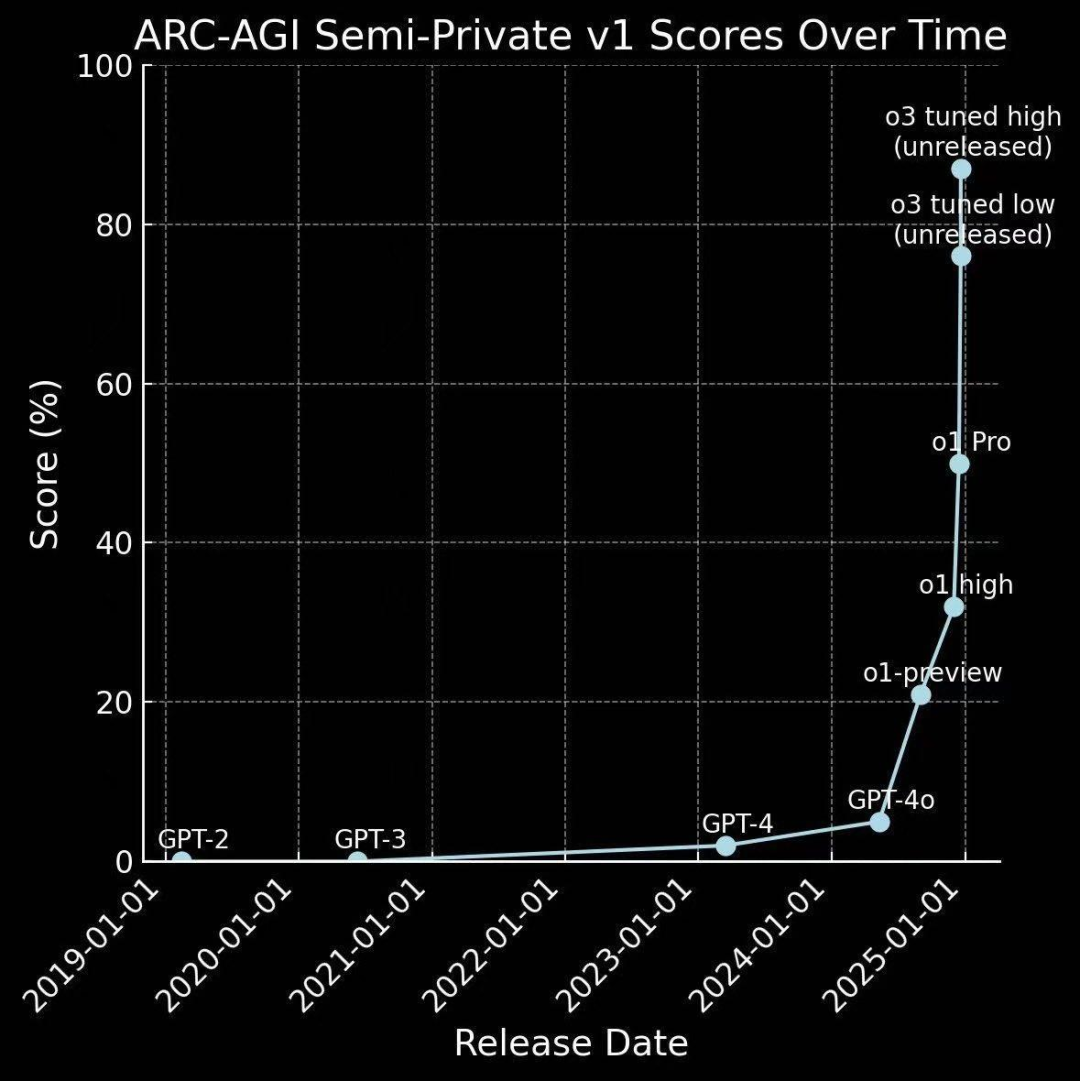
(文:机器学习算法与自然语言处理)