
“ 学习一门技术,先找一套工具和理论研究下去;千万不要反复横跳,什么都想学 ”
大模型作为未来重要的发展方向,很多人想学习大模型技术,但又苦于无从下手;而本公众号前前后后也写过一些怎么学习大模型技术的方法论;但大部分都是从应用的角度作为切入点。
但是,有一个问题就是,如果你是一个技术从业者,想学习和设计一款属于自己的大模型,应该怎么做?
设计一个自己的大模型
大模型作为一门快速发展的新型技术,其理论与实现也是日新月异;因此,对我们大部分人来说很难紧跟大模型的发展趋势,因此我们需要做的是先从一个技术点作为切入。
而最好的方向就是选择一个合适的工具,框架或者理论;比如说PyTorch和Transformer架构。
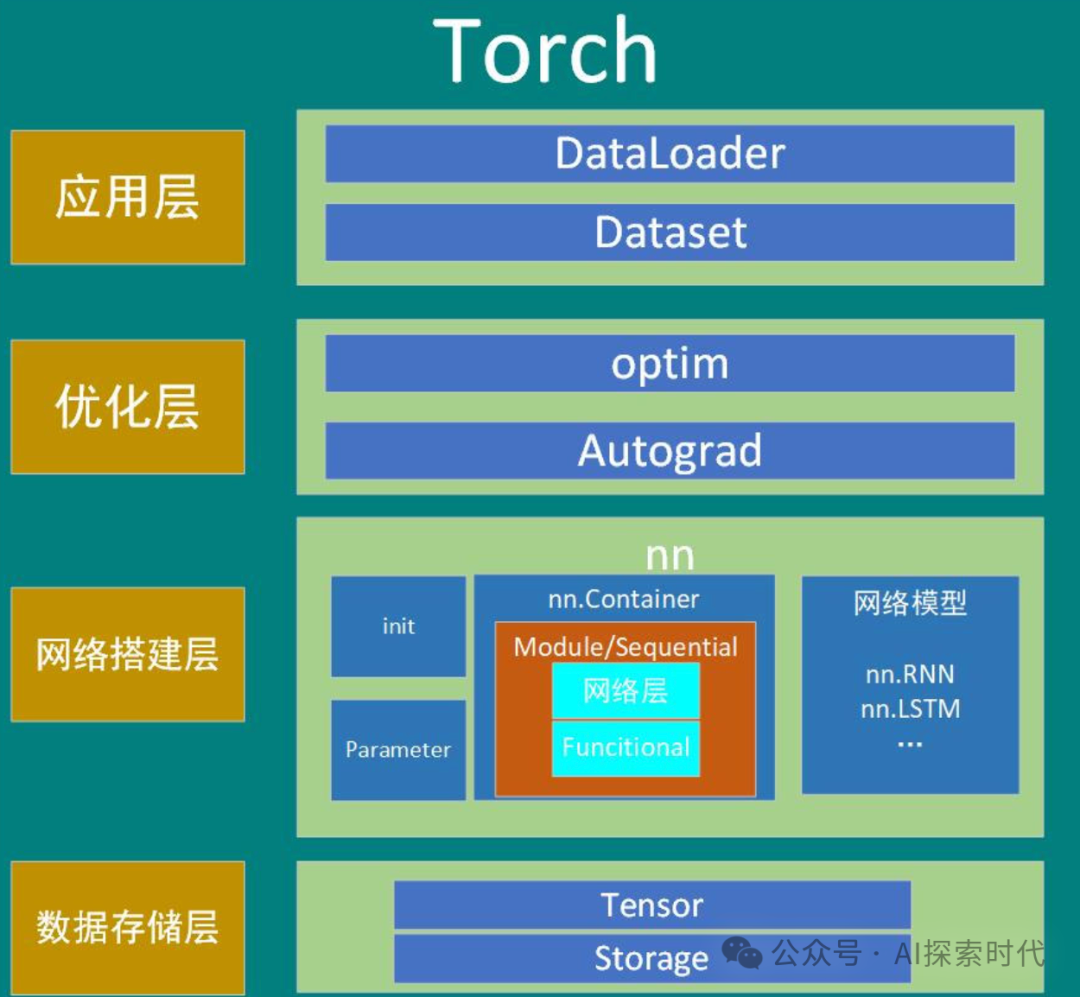
PyTorch是一种可以实现神经网络的开发框架,而Transformer是实现一种NLP自然语言处理的神经网络模型的理论;虽然业内还有其它多种理论和框架,但对我们这些初学者来说,我们需要的是先学习和研究其中的一种理论框架。而不是贪多嚼不烂,这个也想学,那个也想会。
所以,从个人的角度来说,后续学习大模型技术主要就以PyTorch开发框架和Transformer理论架构为主。毕竟虽然框架和理论不尽相同,但其核心思想还是相似的,因此在理解一种理论和框架的基础之上,就可以做到一法通到万法通。
PyTorch作为一个神经网络开发框架,其实现了目前常见的大部分神经网络模型算法,如嵌入,损失计算,反向传播,优化函数,矩阵运算等等。其不但包含了自然语言处理,同时还包含了图像处理,视频处理等功能。
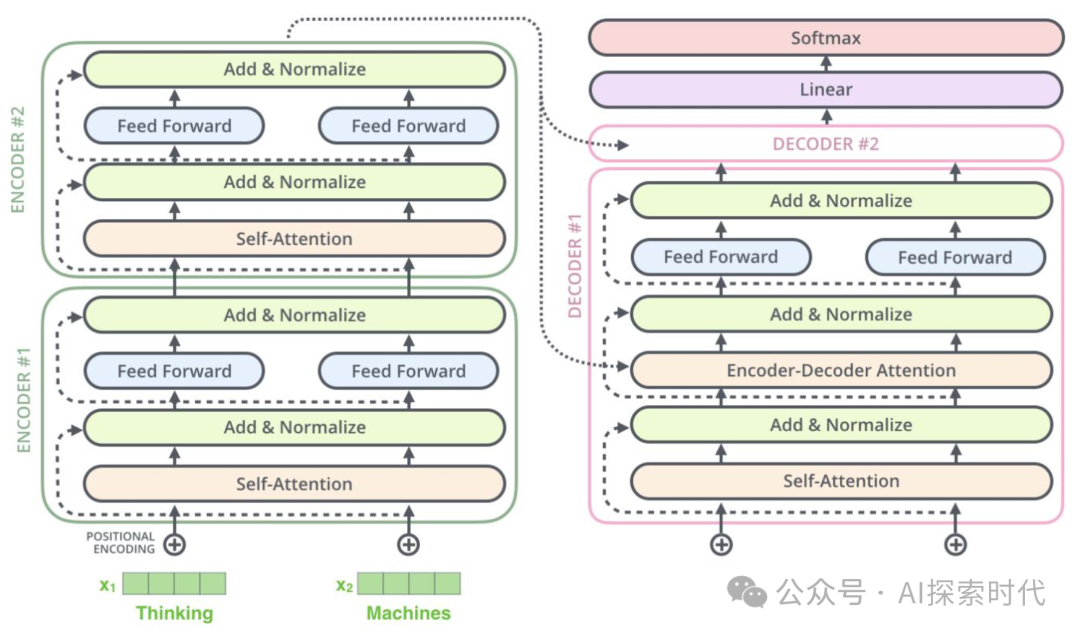
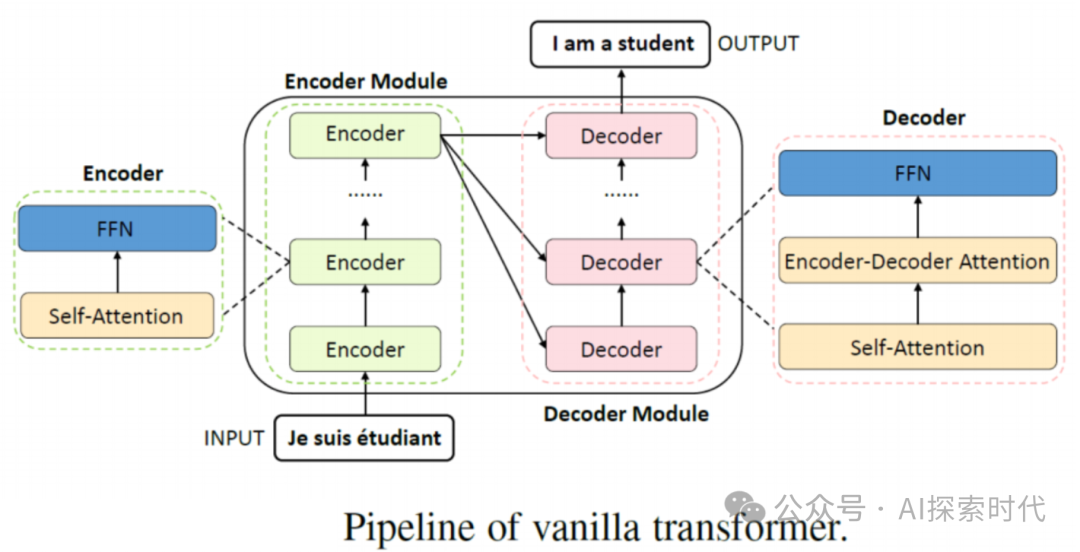
而Transformer理论,也可以被可以被称为算法;则详细解释了为什么文本数据经过一系列的编码器和解码器处理,就可以得到提取数据的基本特征,并且可以生成新的我们需要的数据——也就是特征重建的过程。
在编码器和解码器中,通过实现(自)注意力机制,前馈神经网络等一系列的网络层;本质上就是一系列的矩阵运算,来实现上面的特征提取功能;而这些都可以使用PyTorch科学计算框架来实现。
所以总之就是,PyTorch解决的是怎么计算的问题,而Transformer解决的是为什么这么计算的问题。
当然,除了PyTorch开发框架和Transformer架构之外;同时还有谷歌公司开发的Tensorflow框架,以及CNN——卷积神经网络和RNN——循环神经网络,以及LSTM——长短期记忆网络等变种神经网络架构模型。
因此,每个对神经网络技术感兴趣的爱好者,都可以选择其中的一种或多种框架和网络模型来学习神经网络的实现原理以及搭建一个自己的神经网络模型。
不过还是那个建议,对新学者来说,还是先不要好高骛远;先选择一个简单易学的框架来学习神经网络的实现,而不是什么都想学,什么都想会。等你能自己搭建一个神经网络的时候,你自然就知道神经网络到底解决了哪些问题,以及是怎么解决这些问题的;以及不同神经网络之间的区别和优缺点是什么。
(文:AI探索时代)