



论文链接:
项目主页:
代码仓库:
数据集链接:
作者单位:
复旦大学、苏州大学、上海人工智能实验室、石溪大学、香港中文大学
甚至完全错误等多种状态,简单的“正确/错误”标签难以捕捉其复杂性。
为了解决这一问题,复旦大学,苏州大学,上海人工智能实验室,石溪大学,香港中文大学等联合提出了 PRMBench,一个专门为评估 PRMs 的精细化且极具挑战性的基准。这项研究深入剖析了现有 PRMs 的“软肋”,为未来研究指明了方向。
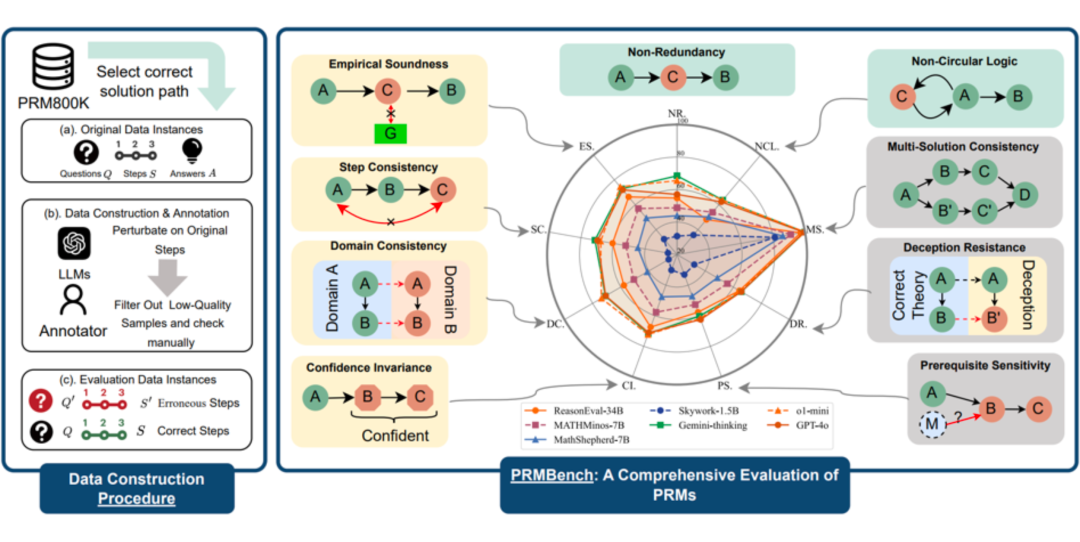
PRMBench:一次针对 PRMs 的“全方位体检”
PRMBench 并非简单的“升级版”评估数据集,而是一套经过精心设计的“体检方案”,旨在全面考察 PRMs 在不同维度上的能力。
PRMBench 的特点
-
海量且精细的标注数据:PRMBench 包含 6,216 个精心设计的问题,并包含 83,456 个步骤级别的标签,确保评估的深度和广度。
-
多维度、多层次的评估体系:PRMBench 从 简洁性(Simplicity)、合理性(Soundness)和 敏感性(Sensitivity)三个主要维度出发,
-
进一步细分为 九个子类别,例如非冗余性、非循环逻辑、评价合理性、步骤一致性、领域一致性、置信度不变性、前提条件敏感性、
-
欺骗抵抗和一题多解一致性,力求全面覆盖 PRM 可能遇到的挑战。
-
揭示现有 PRMs 的“盲区”:研究团队对 15 个代表性模型进行了广泛的实验,包括开源 PRMs 以及将 强力通用语言模型提示作为 Critic Model 的模型。实验结果令人惊讶,也引人深思。
-
整体表现堪忧:即使是表现最佳的模型 Gemini-2-Thinking,其 PRMScore 也仅为 68.8,勉强高于随机猜测的 50.0。这表明,即使是最先进的 PRMs,在多步过程评估中仍然有巨大的提升空间。
-
开源 PRMs 表现更弱:开源 PRMs 的平均 PRMScore 更低至 50.1,部分模型甚至不如随机猜测,揭示了其可靠性和潜在训练偏差的问题。
-
“简洁性”成最大挑战:在 “简洁性” 维度上,即使是表现相对较好的 ReasonEval-34B,其 PRMScore 也骤降至 51.5,表明 PRMs 在识别推理过程中的冗余步骤方面能力不足。
-
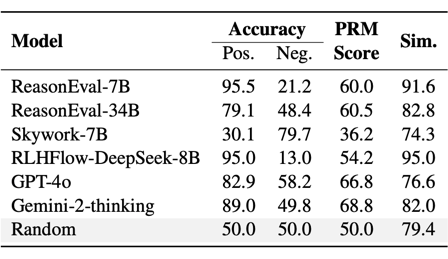
“阳性偏好”现象显著:部分模型,例如 ReasonEval-7B 和 RLHFlow-DeepSeek-8B,在评估中表现出显著的“阳性偏好”,难以区分正确和错误的步骤。
-
数据驱动的洞察:研究发现,错误步骤出现的位置也会影响 PRMs 的判断准确率。总的来说,随着错误步骤位置的后移,PRMs 的表现会逐渐提升。

提出主要问题
在一项需要举出反例的证明题实践中,我们观察到一个有趣的现象:即使大语言模型(`o1`)自身意识到当前推理过程存在一些问题,仍然会产生错误的推理步骤。更令人担忧的是,当我们调用现有的过程级奖励模型(PRMs)去检测刚刚 o1 生成的推理过程时,结果却发现多数 PRMs 无法检测出这种细粒度的错误。
这一发现引出了一个关键问题:当前的 PRM 是否具备检测推理过程中细粒度错误的能力?
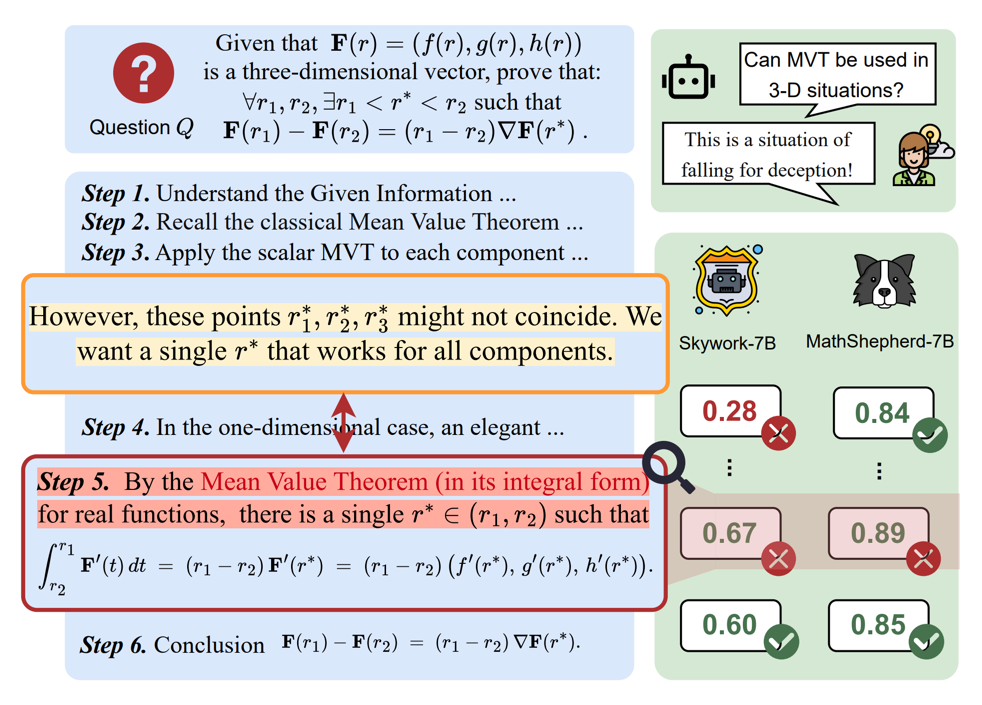
而这,正是我们推出 PRMBench 这一精细化基准的根本原因。我们希望通过 PRMBench,打破现有评估的局限,真正遴选出能够有效识别细粒度错误的“优秀” PRM。
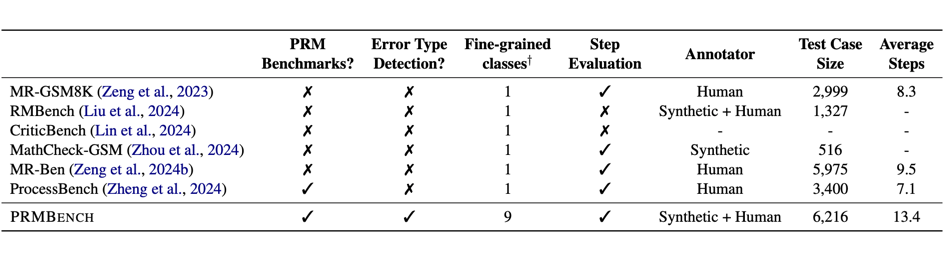

PRMBench 构建
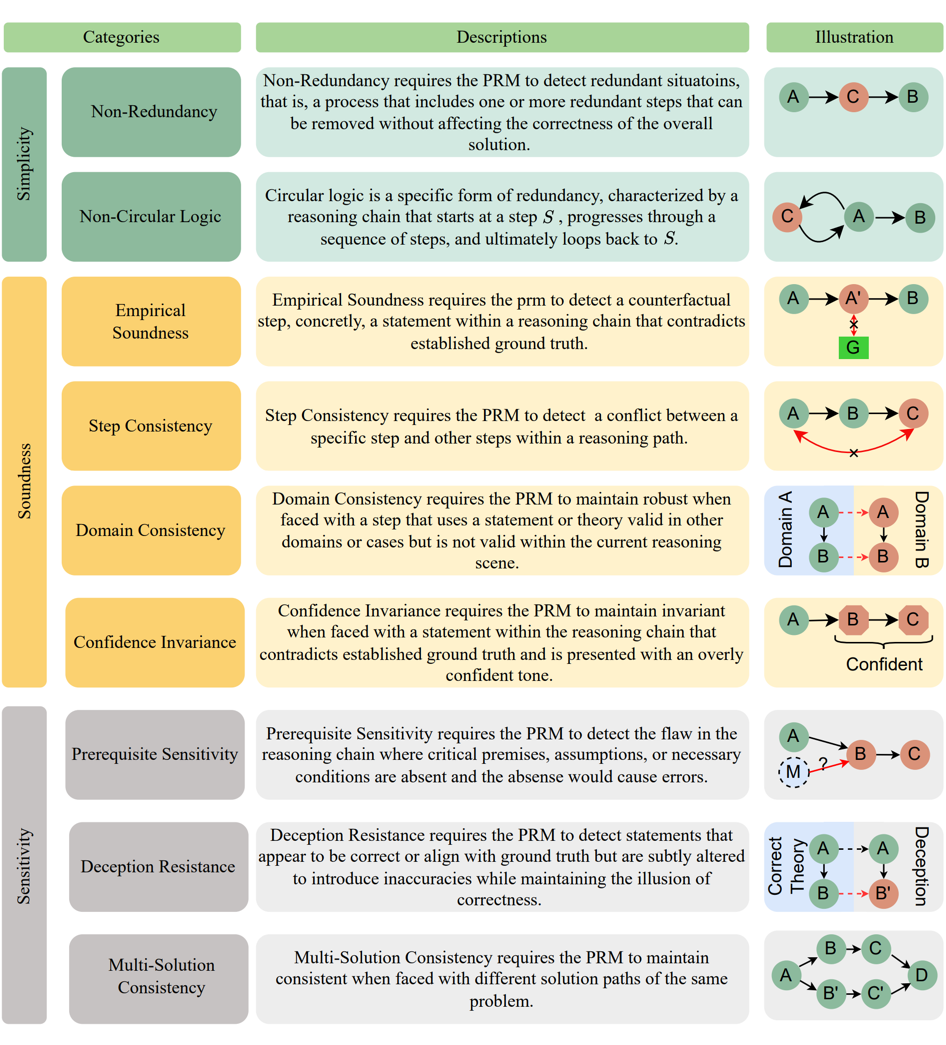
评估对象:分为三个主要领域
-
简洁性(Simplicity):评估冗余检测能力(非冗余性、非循环逻辑)。 -
合理性(Soundness):评估 PRM 产生奖励的准确性和正确性(评价合理性、步骤一致性、领域一致性、置信度不变性)。 -
敏感性(Sensitivity):评估对变化和误导性信息的鲁棒性(前提条件敏感性、欺骗抵抗、多解一致性)。

实验与结果
评估模型:测试了 15 个模型,包括开源 PRMs(Skywork-PRM,Llemma-PRM,MATHMinos-Mistral,MathShepherd-Mistral,RLHFlow-PRM)和提示为 Critic Models 的优秀闭源语言模型(GPT-4o,o1-mini,Gemini-2)。
评估指标:
-
负 F1 分数(Negative F1 Score):评估错误检测性能的主要指标。
-
PRMScore:将 F1 和负 F1 相结合的统一、标准化的分数,以反映整体能力。
-
PRMs 表现不佳:总的来说,PRMs 在多步过程评估中表现出有限的能力,其得分通常仅略高于随机猜测。
-
开源模型落后:开源 PRM 的表现通常不如将强力通用语言模型(如o1, Gemini-thinking 等)提示为 Critic Model 的表现更好。
-
简洁性或成最大挑战:相较于其他评测主题,检测冗余(简洁性)被证明对 PRMs 来说尤其困难。
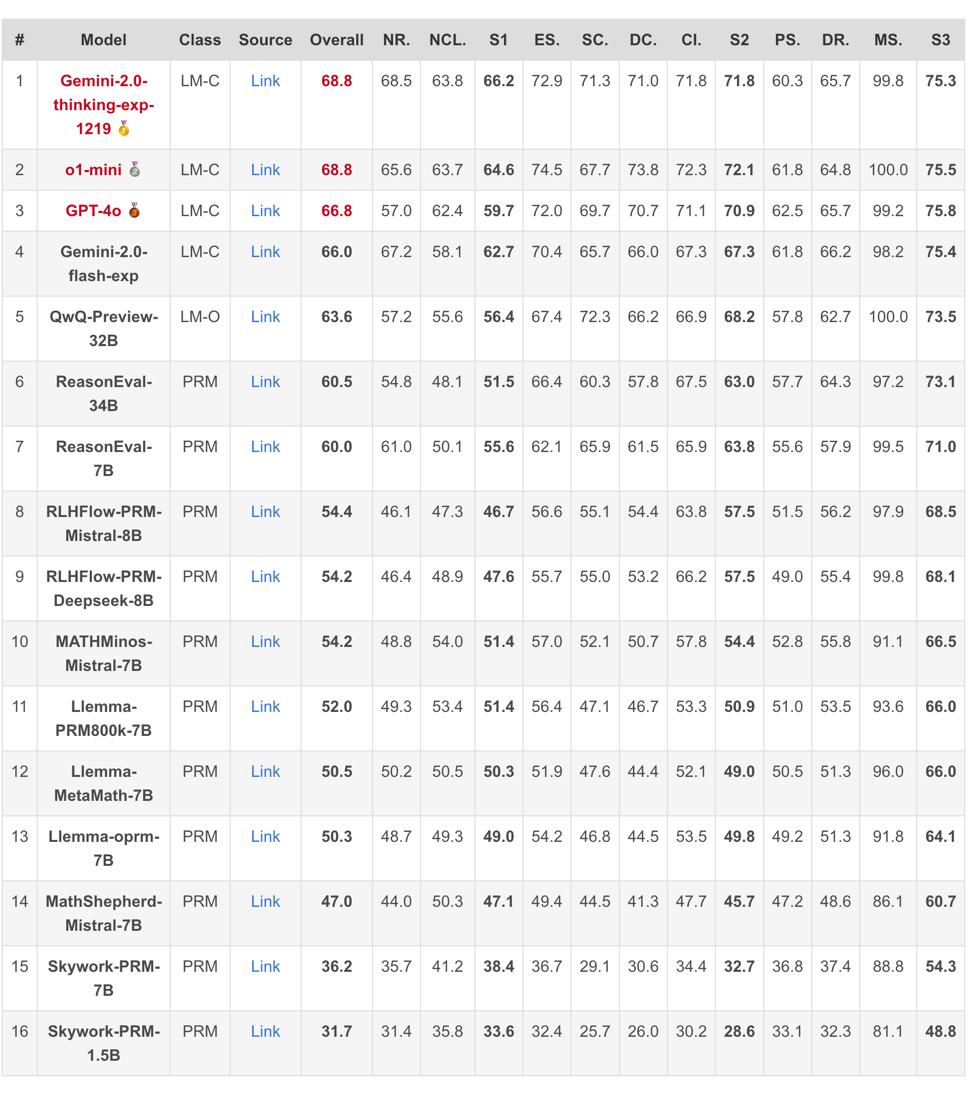
▲ 表2. PRMBench 的主要结果

其他分析
“正确标签偏好”:许多 PRMs 表现出对正确标签的偏好,难以正确识别错误标签测试样例(阴性数据)。
错误位置的影响:PRM 的性能往往会随着推理步骤位于推理链中的位置逐渐靠后而提高。
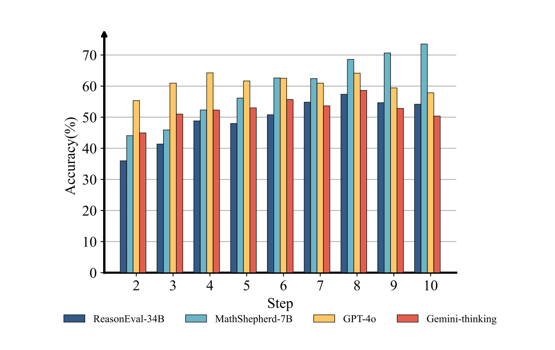
▲ 图4. 推理步骤位于推理链中不同位置对模型 PRMScore 的影响
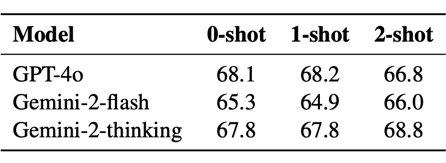
少样本 ICL 的影响有限:在 reward 过程中使用不同数量示例的 In-Context Learning 对闭源模型的性能影响不大。

结语
-
推动 PRM 评估研究的进步:PRMBench 提供了一个更全面、更精细化的评估工具,可以更有效地识别 PRMs 的潜在缺陷,促进相关算法的改进。
-
指导未来 PRM 的开发方向:通过揭示现有 PRMs 在不同维度上的优缺点,PRMBench 为未来 PRM 的设计和训练提供了重要的参考。
-
助力构建更可靠的 AI 系统:更可靠的 PRMs 将有助于提升 LLMs 在复杂推理任务中的表现,最终构建更加值得信赖的人工智能系统。
论文链接:
https://arxiv.org/abs/2501.03124
https://PRMBench.github.io/
奖励模型,过程级奖励模型,大语言模型,基准测试,人工智能,深度学习,模型评估,错误检测
(文:PaperWeekly)