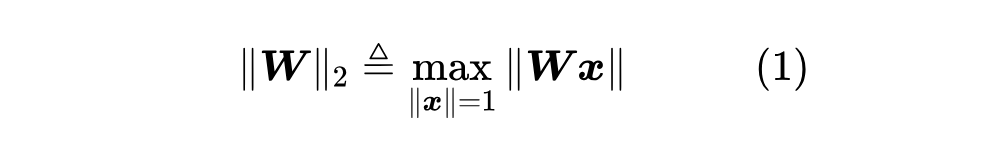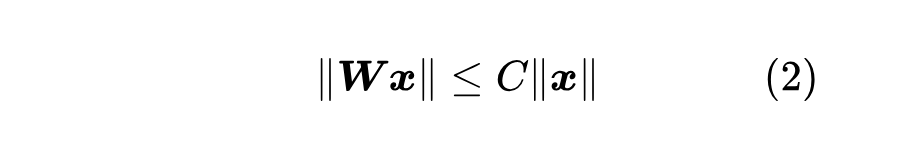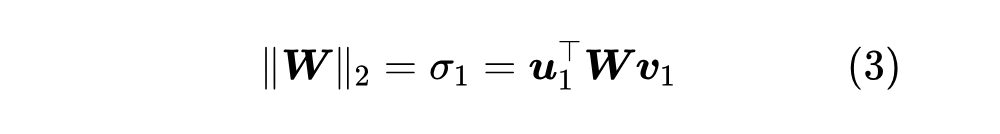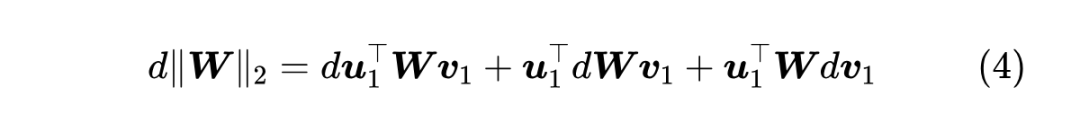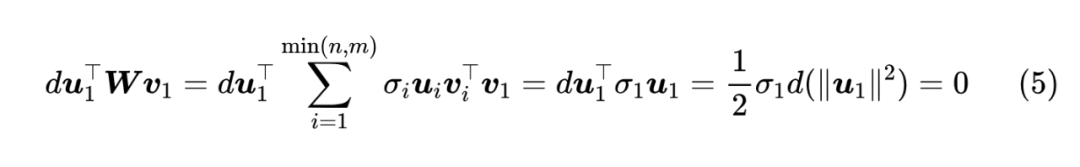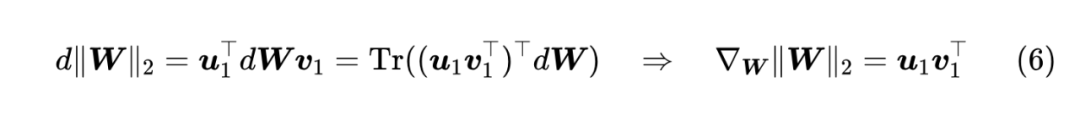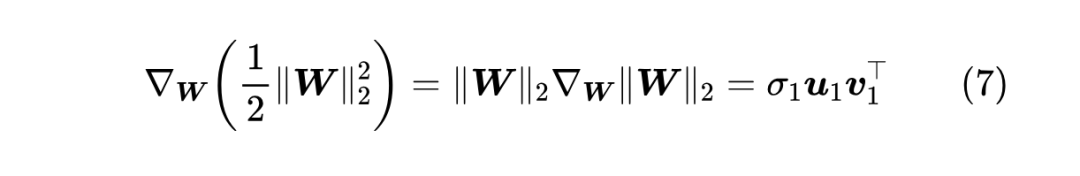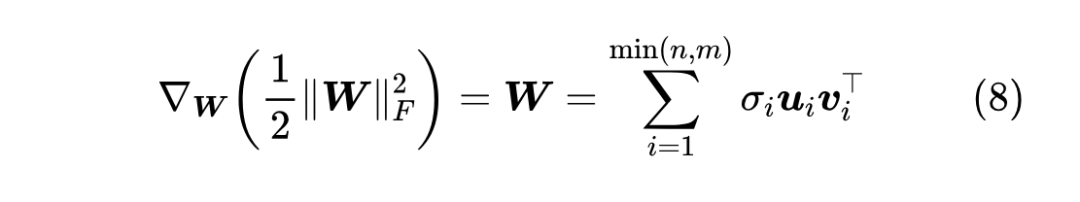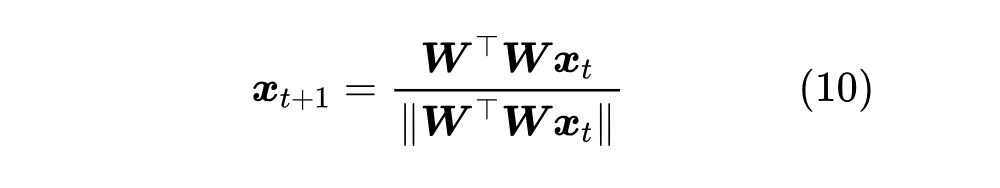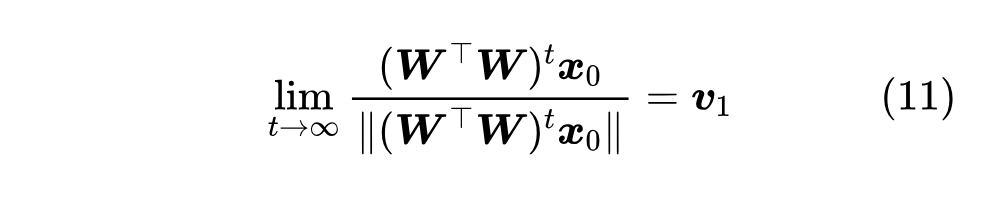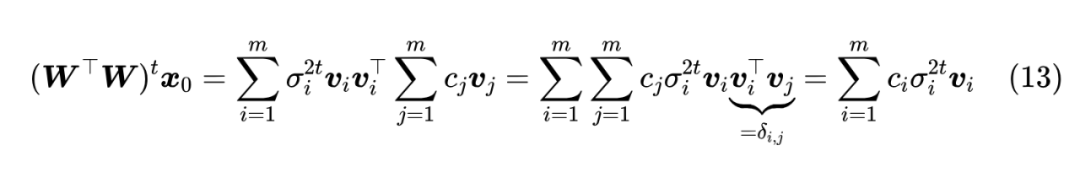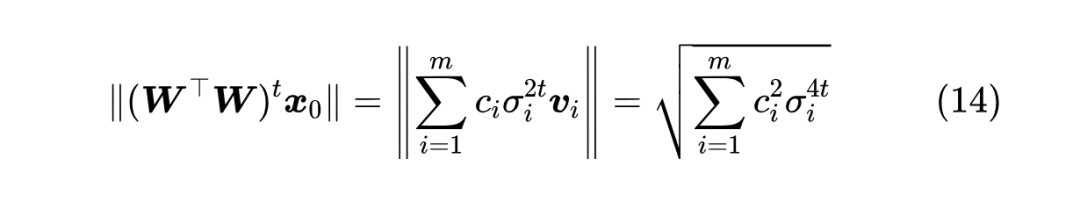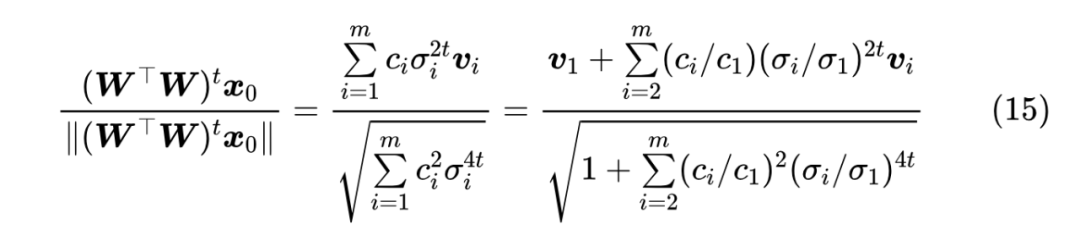©PaperWeekly 原创 · 作者 | 苏剑林 在文章《Muon优化器赏析:从向量到矩阵的本质跨越》中,我们介绍了一个名为 “Muon” 的新优化器,其中一个理解视角是作为谱范数正则下的最速梯度下降,这似乎揭示了矩阵参数的更本质的优化方向。 众所周知,对于矩阵参数我们经常也会加权重衰减(Weight Decay),它可以理解为 那么问题来了,谱范数的梯度或者说导数长啥样呢?用它来设计的新权重衰减又是什么样的?接下来我们围绕这些问题展开。
基础回顾
谱范数(Spectral Norm),又称 “2 范数”,是最常用的矩阵范数之一,相比更简单的 这里 不难证明,当 早在 6 年前的《深度学习中的Lipschitz约束:泛化与生成模型》中,我们就讨论过谱范数,当时的应用场景有两个:一是 WGAN 对判别器明确提出了 Lipschitz 约束,而实现方式之一就是基于谱范数的归一化;二是有一些工作表明,谱范数作为正则项,相比
梯度推导
现在让我们进入正题,尝试推导谱范数的梯度 为 , 那么
注意,这个证明过程有一个关键条件是 注:这里的证明过程参考了 Stack Exchange 上的回答 [1] ,但该回答里面没有证明
这样对比着看就很清晰了: 根据 “Eckart-Young-Mirsky 定理”,式 (7) 最右侧的结果还有一个含义,就是
对于实践来说,最关键的问题来了:怎么计算 由此可见计算 如果还觉得慢,那么我们就需要请出很多特征值分解算法背后的原理——“幂迭代(Power Iteration) [2] ”:
幂迭代每步只需要算两次“矩阵-向量”乘法,复杂度是
这一节我们来完成幂迭代的证明。不难看出,幂迭代可以等价地写成
由于 成 , 于是我们有 由于随机初始化的缘故, 当
最早提出谱范数正则的论文,应该是 2017 年的《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》 [3] ,里边对比了权重衰减、对抗训练、谱范数正则等方法,发现谱范数正则在泛化性能方面表现最好。
论文当时的做法,并不是像本文一样求 出 , 而是直接通过幂迭代来估计 当然,从今天 LLM 的视角来看,当初的这些实验最大问题就是规模都太小了,很难有足够的说服力,不过鉴于谱范数的 Muon 优化器“珠玉在前”,笔者认为还是值得重新思考和尝试一下谱范数权重衰减。当然,不管是 个人在语言模型的初步实验结果显示,Loss 层面可能会有微弱的提升(希望不是幻觉,当然再不济也没有出现变差的现象)。实验过程就是用幂迭代求出
本文推导了谱范数的梯度,由此导出了一种新的权重衰减,并分享了笔者对它的思考。
(文:PaperWeekly)