


在当今人工智能飞速发展的时代,多模态推理成为了研究的热点和前沿领域。阿里云通义千问团队一直致力于推动AI技术的创新和发展,在2024年12月25日,正式发布了业界首个开源多模态推理模型QVQ-72B-Preview,为AI领域带来了新的活力和可能性。本文将对QVQ模型进行详细的介绍和分析,帮助读者深入了解这一具有开创性的模型。
一、项目概述
QVQ模型是阿里云通义千问团队在多年技术积累的基础上,结合最新的多模态学习和推理技术精心打造的一款开源模型。它基于Qwen2-VL-72B构建,旨在通过结合语言和视觉信息,提升AI的推理能力。QVQ模型的发布,不仅展示了阿里云在AI视觉理解和推理领域的深厚积累,也为全球开发者提供了一个全新的、强大的工具,以推动AI技术的进一步发展和应用。

二、主要功能
1、强大的视觉理解能力:QVQ模型能够准确感知视觉内容,无论是真实照片、梗图还是复杂的图形,都可以从中提取出关键信息,并进行细致的分析。例如,它可以轻松识别“梗图”内涵,看真实照片可合理推断出物体个数及高度等信息。
2、深度推理能力:QVQ模型会质疑自身假设,仔细审视其推理过程的每一步,经过深思熟虑后给出最后结论。在面对数学、物理、化学等各科学领域难题时,能像人甚至科学家一样,给出思考过程和准确答案,展现出了超预期的视觉理解和推理能力。
3、多模态融合能力:QVQ模型将视觉和语言模态深度融合,能够理解和处理包含图像和文本的多模态输入,并进行跨模态的推理和生成,为用户提供更全面、更准确的答案和解决方案。
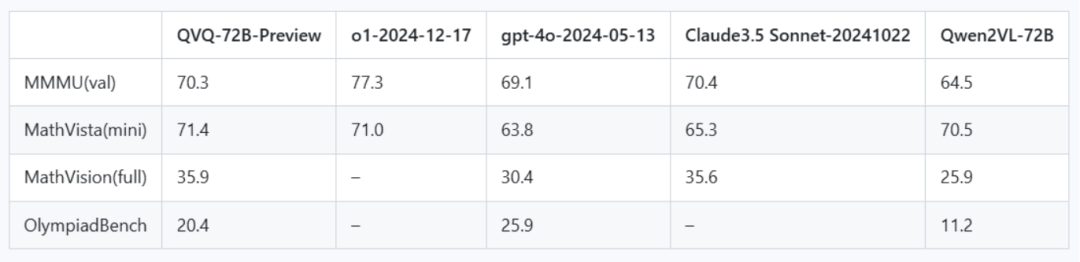
三、性能评测
QVQ模型在多个评测任务中展现出了卓越的性能:
1、在MMMU评测中:QVQ取得了70.3分的成绩,水平已达大学级别,大大超过了其前身Qwen2-VL-72B-Instruct,这表明QVQ在视觉理解和综合推理方面具有很强的能力。
2、在MathVista测试中:QVQ得分超过OpenAI o1,印证了其强大的图形推理能力,在解决数学领域的复杂推理问题上表现出色。
3、在MathVision评测中:QVQ表现超越Claude3.5及GPT4o,说明QVQ更擅长解决真实数学问题,在多模态数学推理方面具有一定的优势。
4、在OlympiadBench基准测试中:QVQ也展现了出色的视觉推理能力,能够应对奥赛级别的科学问题,进一步证明了其在复杂推理任务中的实力。
四、局限性
QVQ-72B-Preview 是由 Qwen 团队开发的实验性研究模型,专注于增强视觉推理能力。尽管它的表现超出了预期,但仍有几个限制需要注意:
-
语言混合与切换:模型可能会意外地混合语言或在语言之间切换,从而影响响应的清晰度。
-
递归推理:模型可能会陷入循环逻辑模式,产生冗长的响应而无法得出结论。
-
安全和伦理考虑:模型需要增强安全措施,以确保可靠和安全的性能,用户在部署时应保持谨慎。
-
性能和基准限制:尽管模型在视觉推理方面有所改善,但它无法完全替代 Qwen2-VL-72B 的能力。此外,在多步骤视觉推理过程中,模型可能会逐渐失去对图像内容的关注,导致幻觉。
五、应用场景
-
教育领域:QVQ模型可以帮助学生更好地理解和解决数学、物理、化学等学科中的难题,通过提供详细的解题思路和推理过程,辅助学生进行学习和思考,提高学习效率和效果。
-
科研领域:在科学研究中,QVQ模型可以协助科研人员进行数据分析、实验结果解读、文献综述等工作,为科研工作提供新的思路和方法,加速科研进程。
-
智能客服领域:QVQ模型可以结合用户的问题和相关的图像、视频等信息,提供更准确、更全面的解答,提高客户满意度,提升智能客服的服务质量和效率。
-
内容创作领域:QVQ模型可以根据用户提供的主题和相关图片,生成高质量的文章、故事、诗歌等内容,为内容创作者提供灵感和帮助,提高创作效率和质量。
六、快速使用
QVQ模型为开发者提供了便捷的使用方式,以下是快速开始使用QVQ模型的详细步骤:
1、环境准备
确保你的系统安装了Python(推荐3.7及以上版本)以及相关依赖库,如`torch`、`transformers`等。你可以使用`pip`命令安装所需依赖库,例如:
pip install torch transformerQVQ模型提供了两种使用方式:基于`transformers`库的推理和使用魔搭API-Inference直接调用。
2、基于`transformers`库的推理
1)安装`modelscope`库
使用`pip`命令安装`modelscope`库,这是使用QVQ模型的基础库:
`pip install modelscope`。
2)加载模型和处理器
以下是加载QVQ模型和处理器的代码示例:
from modelscope import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessorfrom qwen_vl_utils import process_vision_info# 加载模型,默认会在可用设备上加载(如GPU,如果可用)model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/QVQ-72B-Preview", torch_dtype="auto", device_map="auto")# 加载默认处理器processor = AutoProcessor.from_pretrained("Qwen/QVQ-72B-Preview")
3)设置图像参数(可选)
你可以根据需要设置图像的像素范围,以平衡速度和内存使用。例如,以下代码设置了图像的像素范围为256 – 1280(以28×28像素为单位):
# min_pixels = 256*28*28# max_pixels = 1280*28*28
4)准备输入数据
构造包含图像和文本的输入消息,例如:
messages = [{"role": "system","content": [{"type": "text", "text": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. Answer in the language of the question. You should think step-by-step."}]},{"role": "user","content": [{"type": "image","image": "https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/QVQ/demo.png"},{"type": "text", "text": "What value should be filled in the blank space?"}]}]
5)数据预处理
对输入数据进行预处理,包括应用聊天模板、处理视觉信息等:
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt")inputs = inputs.to("cuda") # 如果有GPU,将数据移到GPU上
6)推理生成
使用模型进行推理生成,例如:
generated_ids = model.generate(**inputs, max_new_tokens=8192)generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(output_text)
3、使用魔搭API-Inference直接调用
1)安装`openai`库(如果未安装)
使用`pip`命令安装`openai`库:`pip install openai`。
2)设置API密钥和基础URL
在使用魔搭API-Inference之前,需要设置API密钥和基础URL。假设你已经获取了`MODELSCOPE_ACCESS_TOKEN`环境变量,以下是设置代码示例:
import osfrom openai import OpenAIclient = OpenAI(api_key=os.getenv("MODELSCOPE_ACCESS_TOKEN"),base_url="https://api-inference.modelscope.cn/v1")
3)构造请求数据
构造包含图像和文本的请求消息,例如:
response = client.chat.completions.create(model="Qwen/QVQ-72B-Preview",messages=[{"role": "system","content": [{"type": "text", "text": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step."}]},{"role": "user","content": [{"type": "image_url","image_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/QVQ/demo.png"}},{"type": "text", "text": "What value should be filled in the blank space?"}]}],stream=True)
4)处理响应结果
逐块处理响应结果,例如:
for chunk in response:print(chunk.choices[0].delta.content, end='', flush=True)
4、模型微调
如果你需要对QVQ模型进行微调以适应特定任务,可以按照以下步骤进行:
1)安装`ms-swift`框架
首先,克隆`ms-swift`仓库并安装:
git clone https://github.com/modelscope/ms-swift.gitcd ms-swiftpip install -e.[llm]
2)准备数据集
确保你的数据集符合自定义数据集格式,例如:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
3)图像OCR微调(示例)
以下是一个图像OCR微调的脚本示例,假设你在实验环境中有2个80GiB A100 GPU:
# 实验环境:2*80GiB A100MAX_PIXELS=1003520 \CUDA_VISIBLE_DEVICES=0,1 \swift sft \--model Qwen/QVQ-72B-Preview \--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \--train_type lora \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--freeze_vit true \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 50 \--save_total_limit 5 \--logging_steps 5 \--max_length 2048 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4
4)视频微调(示例)
以下是一个视频微调的脚本示例,假设你在实验环境中有4个80GiB A100 GPU:
# 实验环境:4*80GiB A100# You can refer to `https://github.com/QwenLM/Qwen2-VL` for the meaning of the `VIDEO_MAX_PIXELS` parameter.nproc_per_node=4CUDA_VISIBLE_DEVICES=0,1,2,3 \NPROC_PER_NODE=$nproc_per_node \VIDEO_MAX_PIXELS=50176 \FPS_MAX_FRAMES=12 \swift sft \--model Qwen/QVQ-72B-Preview \--dataset swift/VideoChatGPT:all \--train_type lora \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--freeze_vit true \--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \--eval_steps 50 \--save_steps 50 \--save_total_limit 5 \--logging_steps 5 \--max_length 2048 \--output_dir output \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--deepspeed zero3
5)推理微调后的模型(示例)
训练完成后,使用以下命令对训练时的验证集进行推理。注意,需要将`–adapters`替换成训练生成的last checkpoint文件夹:
# 若是对视频数据进行推理,通常需要4卡CUDA_VISIBLE_DEVICES=0,1 \swift infer \--adapters output/vx-xxx/checkpoint-xxx \--stream false \--max_batch_size 1 \--load_data_args true \--max_new_tokens 2048
结语
阿里云通义千问发布的QVQ-72B-Preview模型是多模态推理领域的一项重要突破,具有强大的视觉理解和推理能力,在多个评测任务中表现出色,并且在多个应用场景中具有广阔的应用前景。然而,QVQ模型目前仍处于实验阶段,存在一些局限性,如语言混合、递归推理等问题,有待进一步优化。但相信随着技术的不断进步和发展,QVQ模型将会不断完善和提升,为AI技术的发展和应用带来更多的惊喜和贡献。
项目地址
-
模型链接:https://modelscope.cn/models/qwen/qvq-72b-preview
-
体验链接:https://modelscope.cn/studios/qwen/qvq-72b-preview
-
中文博客:https://qwenlm.github.io/zh/blog/qvq-72b-preview
(文:小兵的AI视界)
这模型属实强了!不仅能看懂图片还能解数学题,真是人工智能界的-condi-gen
QVQ-72B Preview开源的多模态AI模型了解一下!视觉和语言处理都很强,开源才是未来的潮流!