
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
AI模型领域的这一股“推理模型”的热潮依然还在继续。
光国内,就有5个。而今天要说的阶跃星辰Step R-mini,是第6个。
我先来给不熟悉的小伙伴捋一捋国内推理模型的发展史,虽然只有短短几个月,但却足够“波澜壮阔”。
去年11月20日,DeepSeek发布了国内真正意义上首个推理模型DeepSeek-R1-Lite。其实Kimi的k0-math在几天前就官宣了,但k0-math是官宣早,发布晚,按真正能使用的时间算的话,DeepSeek-R1-Lite是当之无愧的“首个”。附链接:国内首个对标o1的推理模型发布:DeepSeek-R1-Lite初体验!
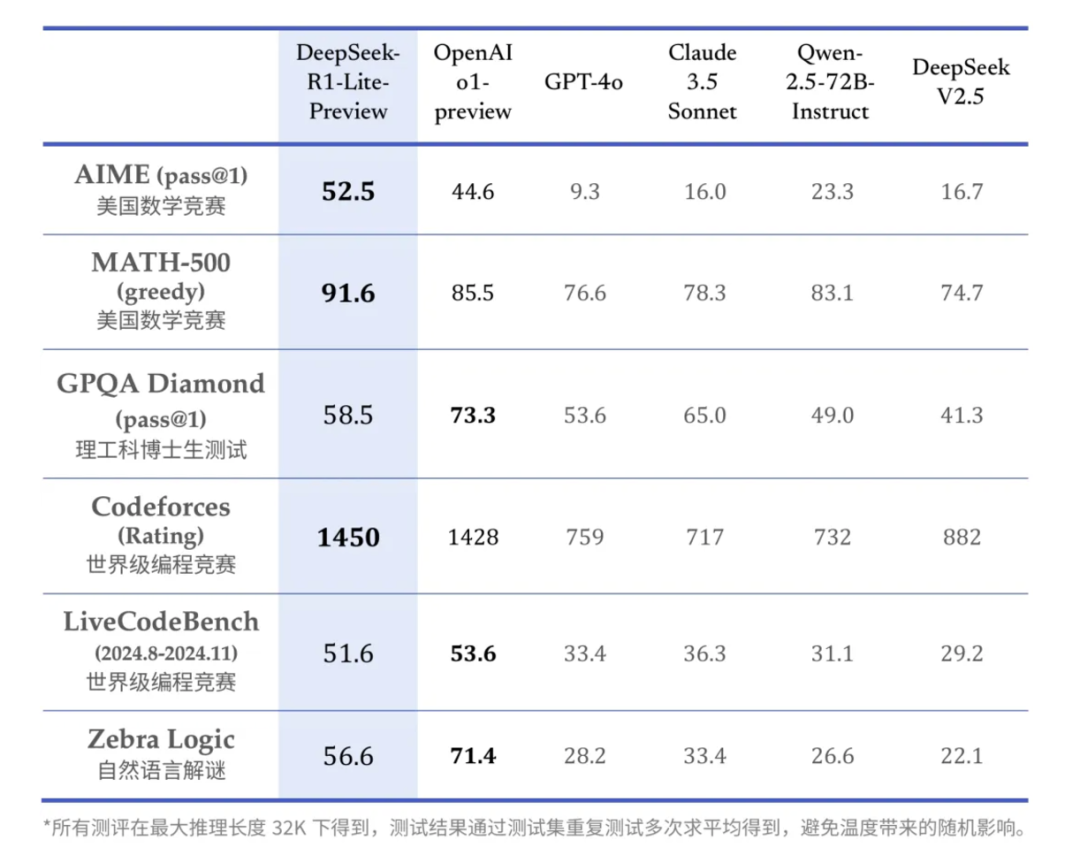
几天后的11月26日,Kimi正式发布k0-math。虽然Kimi官方称它为“数学模型”,而宣传方面也都是在强调k0-math的数学能力,但也掩盖不了它是一个推理模型的本质。上链接:Kimi数学模型正式上线,这是新鲜出炉的测评结果!
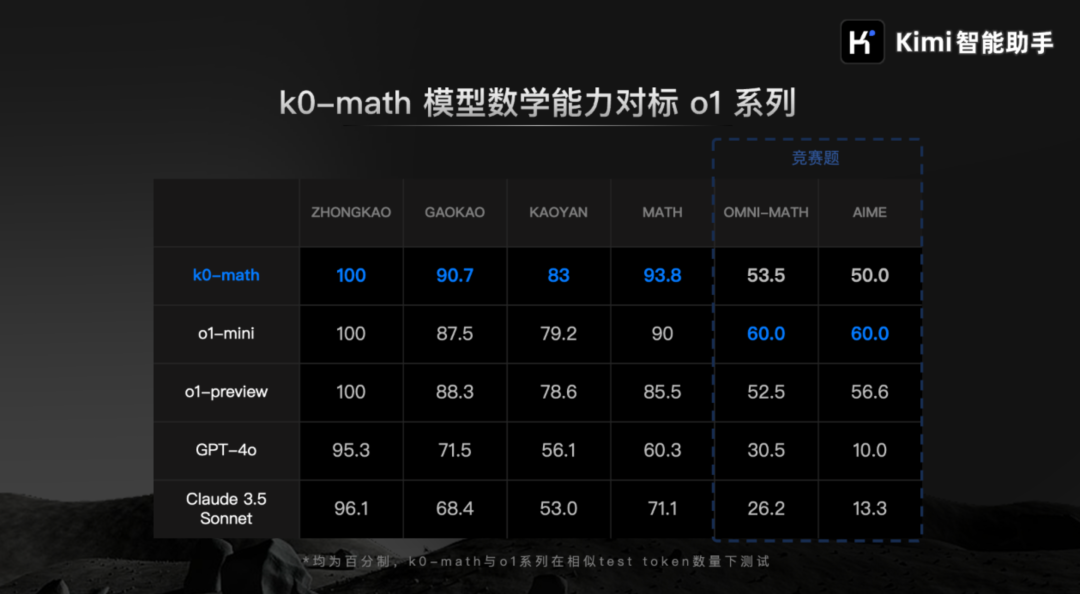
又过了几天,11月28日,阿里通义发布了开源的推理模型QwQ-32B-preview。是的,名字就是这么任性,QwQ。参数量仅32B的QwQ-32B-preview推理能力竟然还不赖:阿里Qwen团队发布首个开源推理模型QwQ-32B-preview!
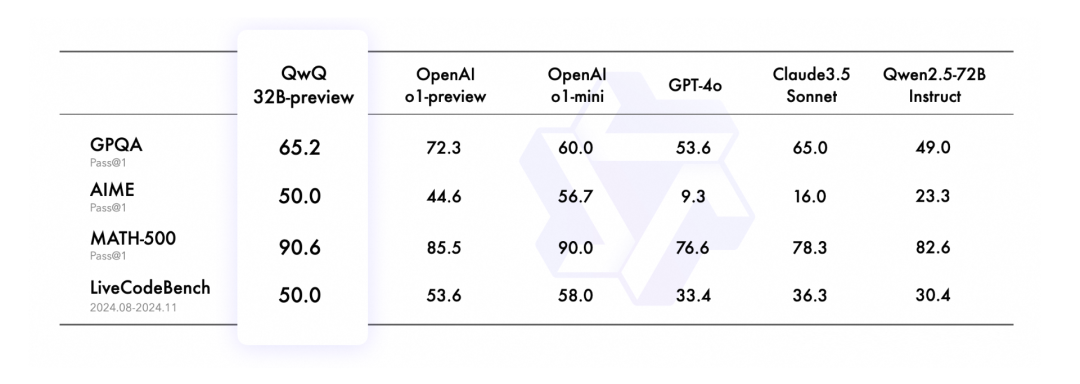
卷大模型,少不了智谱GLM。12月31日,智谱正式推出推理模型GLM-Zero-Preview。
1月6日,昆仑万维终于正式上线了天工大模型4.0 o1版,这么露骨的名字你也应该猜到,它是一个推理模型了吧。在此之前,天工4.0 o1版一直处于邀请测试状态(自11月27日起)。
短短两个月的时间,国内推理模型“百花争艳”,是不是有2023年“卷”通用大模型那味儿了。
整理一波表格。
| 日期 | 模型 | 发布机构 | 关键特点 |
|---|---|---|---|
| 2023-11-20 | DeepSeek-R1-Lite |
DeepSeek | 🚀 国内真正意义上的首个推理模型 |
| 2023-11-26 | k0-math |
Kimi | 🔢 强调数学能力,本质是推理模型 |
| 2023-11-28 | QwQ-32B-preview |
阿里通义 | 😎 参数量32B,开源推理模型 |
| 2023-12-31 | GLM-Zero-Preview |
智谱 | 🎉 智谱推出的推理模型 |
| 2024-01-06 | 天工4.0 o1版 |
昆仑万维 | 🌟 从邀请测试到正式上线的天工大模型 |
而今天,这个表格上就要新增一位选手了:阶跃星辰的推理模型Step R-mini。
1月15日,阶跃星辰正式上线了自研的推理模型Step R-mini,其全称为Step Reasoner mini。阶跃星辰这家公司,和之前介绍过的DeepSeek、MiniMax很像,如果你不关心国内AI领域,甚至可能没听说过。
作为一家AI初创公司的阶跃星辰成立于2023年4月,总部位于上海。阶跃星辰和MiniMax一样,走的是“模型+应用”这条路,自研模型,然后开发应用。阶跃星辰的模型代表作是Step系列,目前已经迭代到Step-2;而Step-2也曾有过辉煌的战绩:跻身进入LMSYS大模型排行榜前10名。核心产品有2个:AI聊天平台跃问,以及AI角色扮演类产品冒泡鸭。
阶跃星辰的官方首页,有马斯克xAI的“探索宇宙”那感觉了。

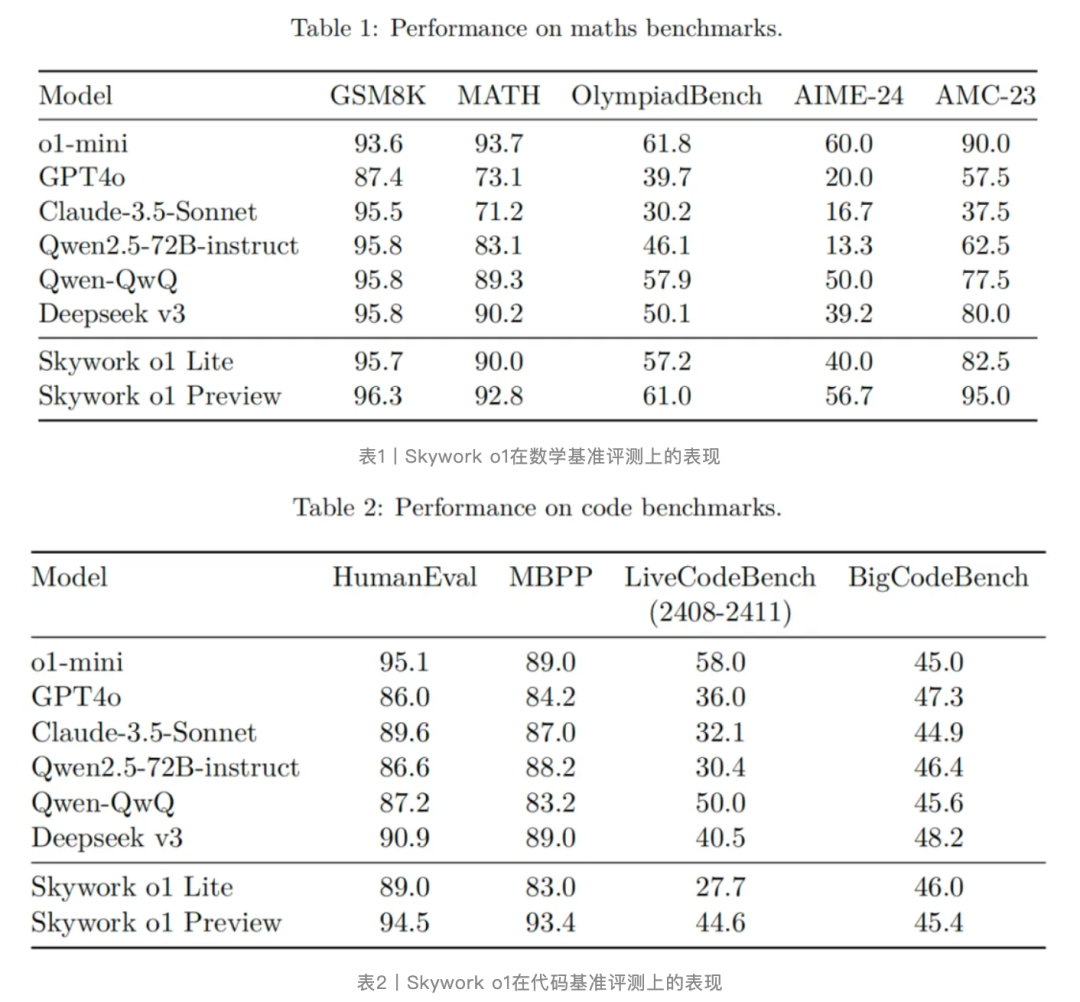
根据官方放出的基准测试对比数据,Step R-mini的性能表现应该是和OpenAI的o1-mini相当,甚至在数学能力方面更强。
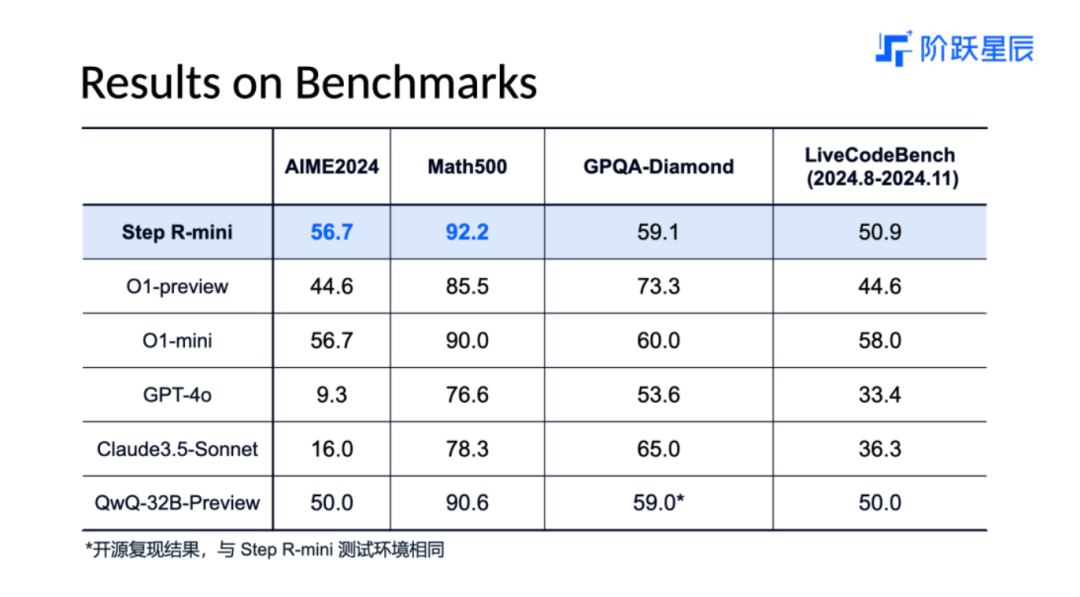
值得一提的是,国内的很多AI厂商喜欢把自家的推理模型和GPT-4o、Claude 3.5 Sonnet这样的一线通用基座模型做对比,今天的阶跃星辰和之前的5家皆是如此,这其实是有失公允的。通用模型走的训练路线和推理模型完全不一样,缺少了“内部思维链”的加持,没有任何的“思考”能力,这相当于一个大学生和一个小学生一起做小学数学奥赛题,还要把成绩放在一起“强行”对比,结果其实意义不大。如果一个推理模型的基准测试结果,很多方面还不如通用模型,那才有问题。
是骡子是马,让我们拉出来遛遛看。我在大约两周前测试了前面几个推理模型,详情看这里:元旦献礼:谁才是o1的最佳平替?!
今天,来看看阶跃星辰的Step R-mini。
Step R-mini直接在跃问平台上就能免费使用。
阶跃星辰跃问:https://yuewen.cn
先来一道开胃小菜,“帽子颜色问题”。Step R-mini的答案是正确的,推理过程大部分也正确,但这个推理论证其实是小有瑕疵的,因为并没有明确指出核心原因:10顶帽子至少有1黄。第10-2个人说“不知道”,那么说明他们前面的就不全是蓝帽(如果全蓝,自己必为黄帽)。直到第1个人,必定是黄帽。
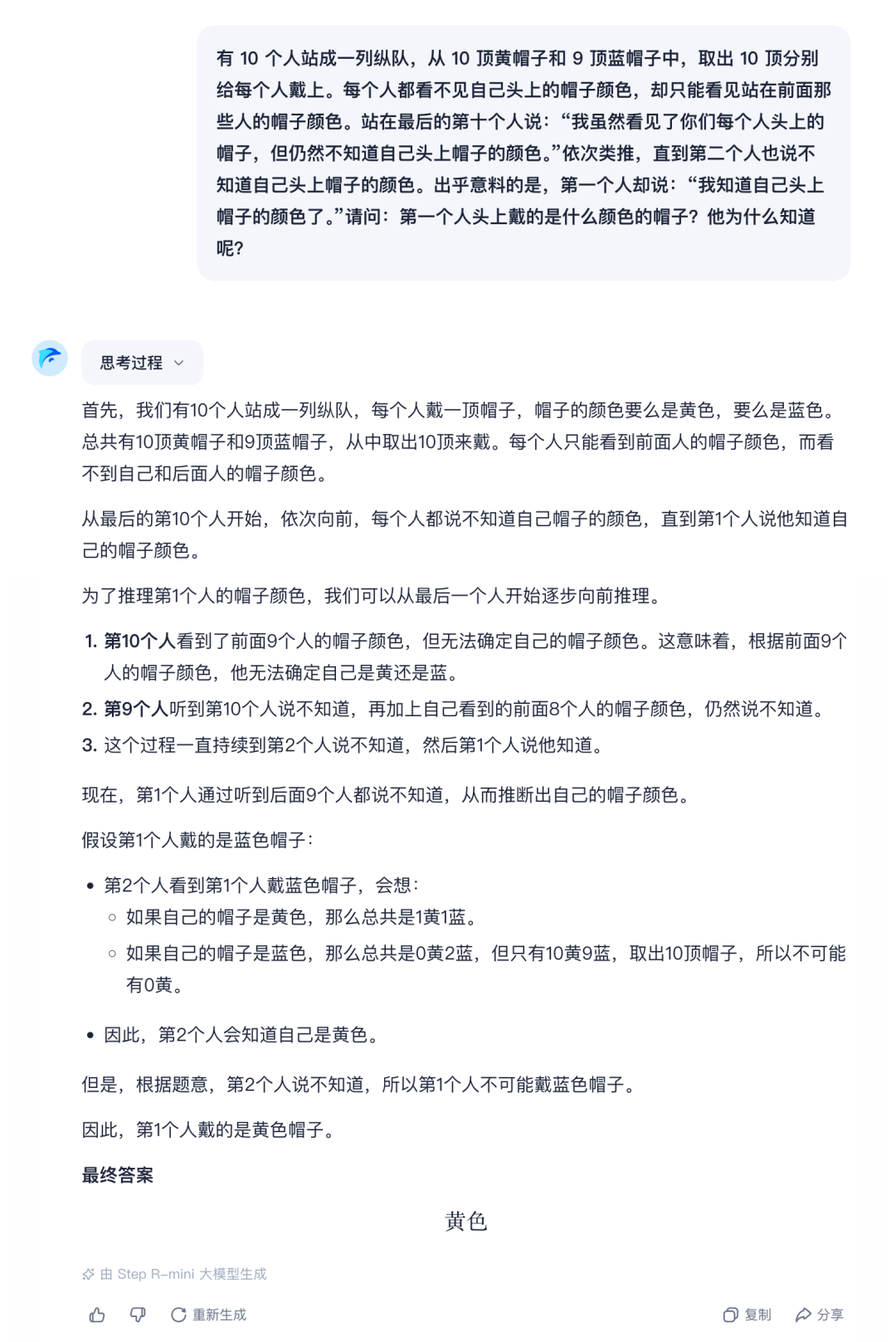
而从Step R-mini的思考过程来看,出现了大量的自我否定,并且整个推理过程中,Step R-mini并没有抓住核心问题。附上非常长的推理过程,并没有针对,仅供学习、讨论交流。

接下来是“蜗牛爬杆问题”。这个问题考察推理模型对题目的理解、以及后续的推理能力。很明显,这里Step R-mini题目理解错误了,因为题目并没有说杆的长度,这里需要分类讨论。
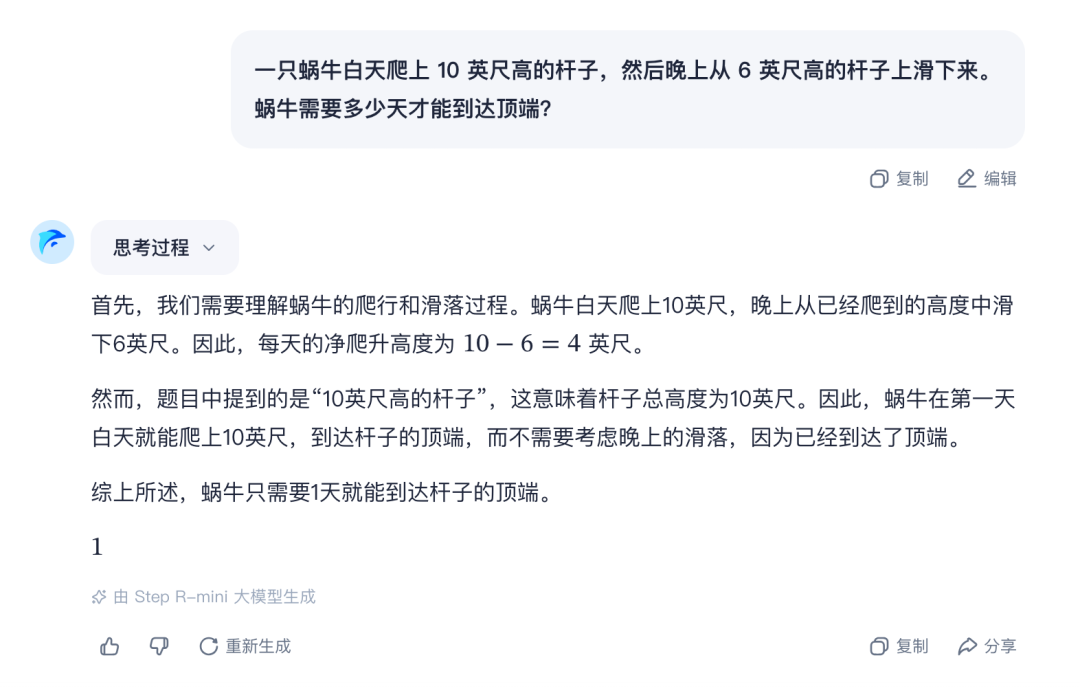
其实思考过程中,Step R-mini已经察觉到了这一点,但很可惜,它又立即把自己的想法否定了。

接下来测试的是“真假话推断问题”里的宝匣问题。Step R-mini的回答完全正确,推理过程也很清晰。

接着是“逻辑推理问题”。这道题目有一定难度,因为可行解不唯一。Step R-mini的回答完全错误,推理时也是把自己绕进去了,这一点让我很意外。因为在之前的测试中,o1回答完全正确,其余的推理模型至少都找到了1个解。

推理的最后,Step R-mini似乎是和自己和解了。

最后这个24点的推理问题,Step R-mini不出意外的没有答对。这个题目之难,只有o1能回答正确。

总结几个观察到的现象。测试下来,我发现Step R-mini很多时候会“过度思考”,当然这是国产推理模型的“通病”。在思考过程中出现了大量的自我怀疑、自我否定,有时甚至因此和正确答案失之交臂。
以“9.9和9.11哪个大”这个经典问题为例。整个推理过程充斥着大量的“但是,等一下,这好像不对”、“让我再想想,也许我弄错了”、“但是,我感觉哪里不对”、“但是,我仍然觉得有点困惑”等等自我否定的思考,直到最后自己把自己说服。

再来看国内推理模型都在对标的o1-mini回答“9.9和9.11哪个大”的表现。仅思考4秒钟,显然推理过程更高效。

结语
最后值得一提的是,Step R-mini的思考和回答过程全程使用中文,这一点提出表扬。
(文:AI信息Gap)