

如何将全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
如何将全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
align-anything开源代码地址:
align-anything数据集地址:
align-anything测评榜单地址:
Beaver-Vision-11B模型:
Chameleon-7b-base模型:
Chameleon-7b-plus模型:
https://huggingface.co/PKU-Alignment/AA-chameleon-7b-plus

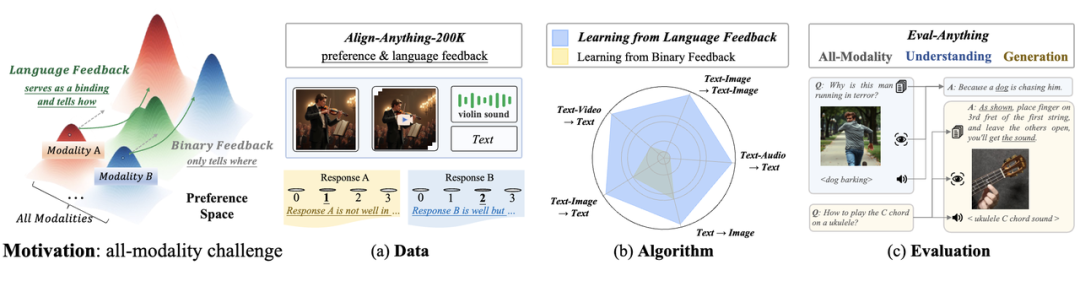
全模态大模型与全模态对齐:大模型性能的最后一块拼图
人类在日常生活中接收到的信息往往是全模态的,不同的感官渠道能够互相补充,帮助我们更全面地理解和表达复杂的概念。
这种全模态的信息流对大模型范式转向通用人工智能也同等重要,研究人员开始尝试将大语言模型进行模态扩展,得到不仅能够处理语言,还可以理解并生成图像、音频、视频等多种信息的全模态模型,如 GPT-4o、Chameleon 等。也包含目前最为流行的开源视觉语言模型,LLaMA-3.2-Vision。
以 Chameleon 为代表的大语言模型多模态化已是大势所趋,而支持任意的模态输入并生成任意模态的输出的全模态大模型将成为未来的里程碑。如何将全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
然而,随着模态的增加,输入输出空间的分布更加广泛,并增加了幻觉现象,使得全模态对齐变得更加复杂。

如上案例所示,当用户要求将图片中的披萨变得更有卖相时,Chameleon-7B 错误地将“披萨”识别成了“肘子”,从而提供了错误的步骤和图片。而由北大对齐小组开发的对齐后模型 Chameleon 7B Plus,则正确地完成了这一任务。
Chameleon 7B Plus 是北大对齐小组在全模态对齐系列工作上的应用示范。事实上,为进一步促进社区的多模态对齐研究,北大对齐小组在数据集、算法、评估以及代码库四大维度贡献了开源力量。
-
数据:200k包含人类语言反馈和二元偏好的数据集,包含图、文、视频、语音全模态。
-
算法:从语言反馈中学习的合成数据范式,大幅提升 RLHF 后训练方法的表现。
-
评估:面向全模态模型的模态联动与模态选择评估。
-
代码库:支持图、文、视频、语音全模态训练与评估的代码框架
通过该框架,研究人员不但可以利用该框架进行多模态模型的对齐实验,提高模型的训练和评估效率,还可以用该框架微调各种大模型,提升在特定任务上的表现。该框架的推出,对探索全模态大模型与人类的意图相对齐、研究如何通过不同对齐算法让模型输出更符合人类预期和价值观具有重要意义。
在 Meta 并未披露 LLaMA-3.2-11B-Vision-Instruct 对齐技术细节情况下,北大对齐小组愿以诚意满满的数据、训练、模型、评估的全流程开源,为全模态对齐研究贡献力量。

全模态代码库:align-anything
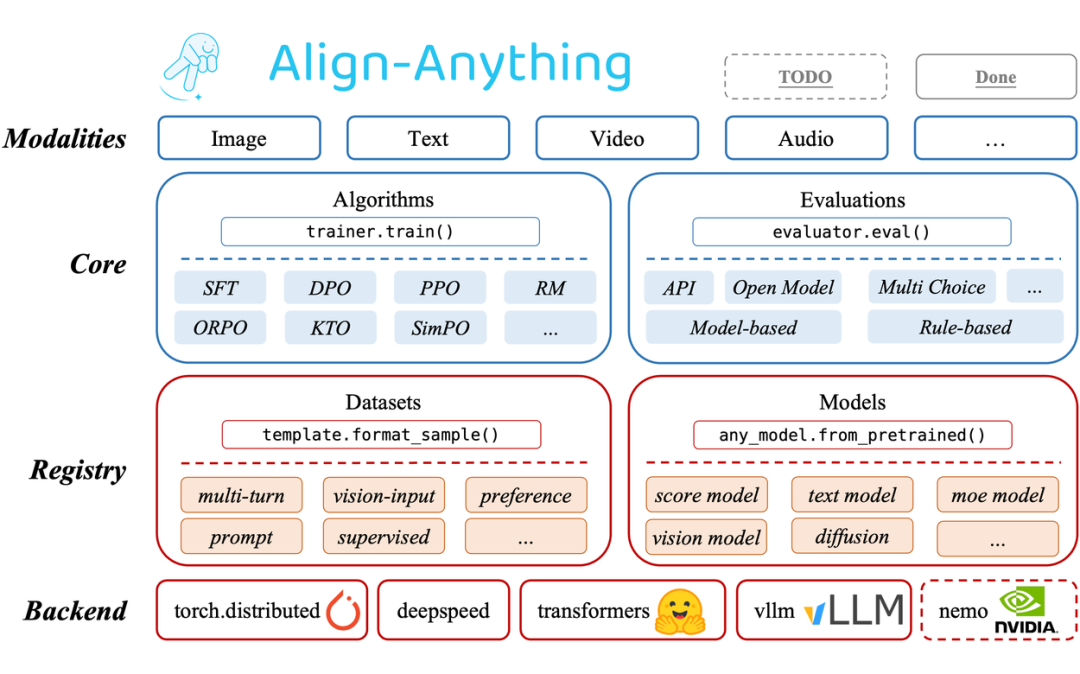
align-anything 框架致力于使全模态大模型与人类意图和价值观对齐,这里的全模态包括文生文、文生图、文图生文、文生视频等任意到任意的输入与输出模态,总体而言,该框架具有以下特点:
-
高度模块化:对不同算法类型的抽象化和精心设计的 API,用户能够为不同的任务修改和定制代码,以及定制化模型与数据集注册等高级扩展用法;
-
支持跨任意模态模型的微调:包含对如 LLaMA3.2、LLaVA、Chameleon、Qwen2-VL、Qwen2-Audio、Diffusion 等跨越多种模态生成与理解的大模型的微调能力;
-
支持不同的对齐方法:支持任意模态上的多种对齐算法,既包括 SFT、DPO、PPO 等经典算法,也包括 ORPO,SimPO 和 KTO 等新算法;
-
支持多种开、闭源对齐评估:支持了 30 多个多模态评测基准,包括如 MMBench、VideoMME 等多模态理解评测,以及如 FID、HPSv2 等多模态生成评测;
2.1 训练框架
北大对齐小组设计了具备高度的模块化、扩展性以及易用性的对齐训练框架,支持由文本、图片、视频、音频四大基本模态衍生出的任意模态模型对齐微调,并验证了框架对齐算法的实现正确性。
2.1.1 模块化
对齐代码实现高度可复用。align-anything 的设计思路是模态与算法的解耦合。例如,对于 DPO 算法,其损失函数的实现可被抽象为:提升 chosen 答案的概率,降低 rejected 答案的概率。
这一思想是模态无感的。align-anything 在模态扩展的过程中尽可能地复用了相同的框架,这样既能够突出不同模态间算法实现的差异性,也便于用户在新的模态上扩展算法。
2.1.2 正确性


2.1.3 扩展性
模型与数据集注册高度可定制。多模态大模型的迭代日新月异,新模型、新数据集层出不穷。这要求对齐框架具备高度的可扩展性,便于用户快速地将新模型或新数据集仅通过几行代码注册进框架中。
对于新数据集的注册,align-anything 提出了一个名为 “template” 的数据集键值转换规则。无论 prompt 对应的键名是 “prompt” 还是 “question”,无论 response 对应的键名是 “response” 还是“answer”,“template” 机制都支持用户通过简单构建映射规则的方式完成键值解析和转换,避免用户单独实现复杂的数据预处理代码。
2.1.4 易用性
用户指南与代码传参高度可复现。对齐算法的训练启动往往涉及复杂的路径与训练超参数传递,而随着模态数的增多,算法训练启动愈发复杂,新用户往往难以快速上手。为此,北大对齐小组为 align-anything 开发了详尽的使用说明文档。
这份细致的说明文档为已支持模态的每个对齐算法都提供了一份可以直接复制粘贴并运行的启动脚本。示例是最好的入门教程,通过运行这些示例,用户可以快速启动训练。
进一步,北大对齐团队提供了细致的训练超参数传递规则解析,告知用户有哪些训练超参数可传入,以及如何传入,这些设计将为用户调试多模态大模型对齐实验提供极大便利。
2.2 评测框架
北大对齐小组精心设计了高度解耦合的多模态对齐评测框架,提供多种模态评测,支持多种推理后端,具有高度可扩展性,以满足多样化的多模态模型评测需求。
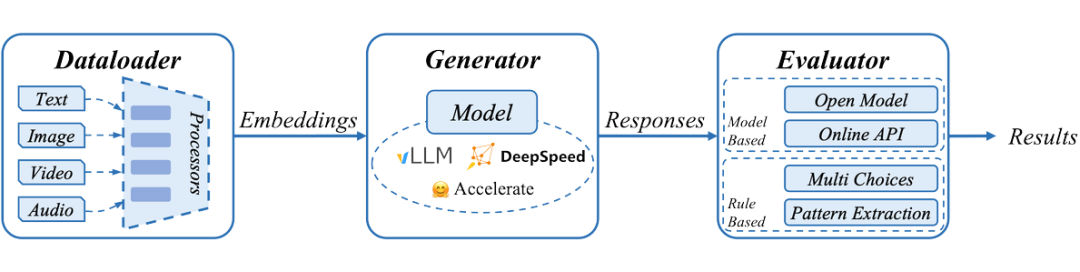
2.2.1 多种推理后端
考虑到 Transformers 框架和 Diffusers 框架对模型支持之间的差异,align-anything 的评测框架将推理和评估过程进行了解耦合,并支持使用不同的后端进行推理。
在多模态理解任务和多模态生成任务中,框架分别采用 Deepspeed 和 Accelerate 作为推理后端,以适配不同模型结构的推理需求。此外,align-anything 评测模块还提供了使用 vLLM 进行推理的接口,适配 vLLM 框架的模型能够在评测中实现推理加速。
2.2.2 多种模态评测

2.2.3 高度可扩展性
为了方便集成自定义评测集,align-anything 对评测框架进行了高度解耦。该框架主要由 DataLoader、Generator 和 Evaluator 三部分组成。
DataLoader 负责加载和预处理多种评测集,转化为适合推理的数据格式;Generator 负责使用不同的推理框架生成结果;Evaluator 则对生成的结果进行评估并输出评分。如果开发者仅需更换评测集,而无需更改推理框架和评估方式,只需将新的评测集适配到 DataLoader 中即可完成集成。

全模态数据集: align-anything
北大对齐小组同时发布首个全模态人类偏好数据集 align-anything。与专注于单个模态且质量参差不齐的现有偏好数据集不同,align-anything 提供了高质量的数据,包括了输入和输出中的任何模态,旨在提供详细的人类偏好注释以及用于批评和改进的精细语言反馈,从而实现跨模态的全面评估和改进。

align-anything 涵盖图、文、视频、音频 4 种模态,并根据输入与输出的多样性延伸至 8 种任务。
3.1 数据集的呈现
为了能够应对上述提到的挑战,在数据集的构建阶段,北大对齐小组开创性地将数据集的呈现分为三个模块,通过语言反馈标注作为弥合模态之间鸿沟的桥梁,承载任意模态上的人类细粒度偏好反馈:
-
Any-to-Any 表示任意类型的输入输出模态的双向转换。
-
Any-to-Text 表示从非文字模态的输入向文字模态输出的转换。
-
Text-to-Any 则代表从文字模态向其他任意模态进行的转换。
同时,他们还演示了基于多模态特性优化数据集质量的多步骤流程:

从流程图可以看到,首先设计针对各种模态量身定制的特征,根据特定的模态任务及其相应的特征,以优化部分较低质量的原始提示,以得到最终版本的问题,同时从多个来源收集回答(包括根据特性构造偏序问答对、调用开源和闭源模型以及使用人工生成答案)。
接着对收集到的问答对使用目前 SOTA 闭源模型和专业标注人员进行细粒度的偏好标注。标注过程涵盖各种维度,每个维度都有相应的偏好回答选项和评分标准。
最后,针对各个模态任务特性,提供有关回答的语言反馈(包括批评和优化)。这里的语言反馈流程分为三步:确定批评的范围、对相应需要批评的范围进行反馈,以及对整个反馈过程提供优化建议。这样的语言反馈流程范式捕获了跨模态的直接偏好和基于语言的反馈,确保对响应进行全面评估和优化。

如上述例子所示, align-anything 的数据涵盖了多种模态的输入,在多个维度上标注了二元偏好,且使用 Critique 和 Refinement 作为语言反馈,标识回答的错误指出,并提供改进意见。
3.2 现有数据集的对比
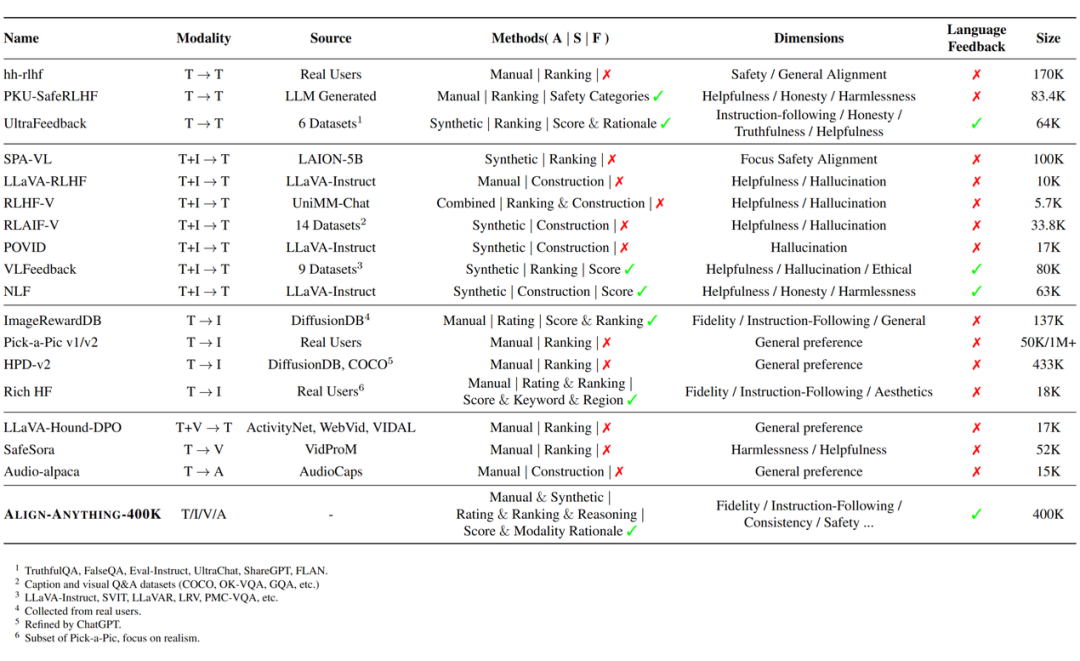
-
A 是指标注来源,它指示如何在数据集中确定偏好项。主要是人工注释或手动构建、由 GPT-4V 或其他系统等模型生成或注释,或是从多个来源聚合。
-
S 表示偏好信号的组成,其中可能包括评分、排名和推理。在某些情况下,首选项是通过优化、更正或破坏响应来构建,以形成所需的首选项对。
-
F 则表示数据集是否在这些首选项维度中提供更详细的细粒度反馈。
通过和目前现有偏好数据集的对比,北大对齐小组发现虽然随着大模型的能力逐渐向越来越多模态迁移,目前偏好数据集却缺乏细粒度的反馈维度且涵盖模态较少,同时缺乏一个合理的结构和纽带,将跨模态偏好数据集组织起来。

全模态算法:从全模态语言反馈中学习
4.1 算法动机
1. 丰富的全模态反馈数据:传统对齐方法依赖单一模态数据,无法满足全模态模型对齐的复杂需求。需要引入更丰富和复杂的反馈模态,如结合图像、音频、视频等多种模态的信息,使反馈内容更加立体和多元化。这种全模态反馈能呈现更多维度的信息,帮助模型更好地理解和捕捉不同模态之间的相互关系,提高对齐的精准度;
4.2 算法流程
如何利用好语言反馈的丰富信息赋能全模态对齐,是北大对齐团队重点关注的关键科学问题。为此,他们提出了从语言反馈中学习的范式(Learning from Language Feedback,LLF)。
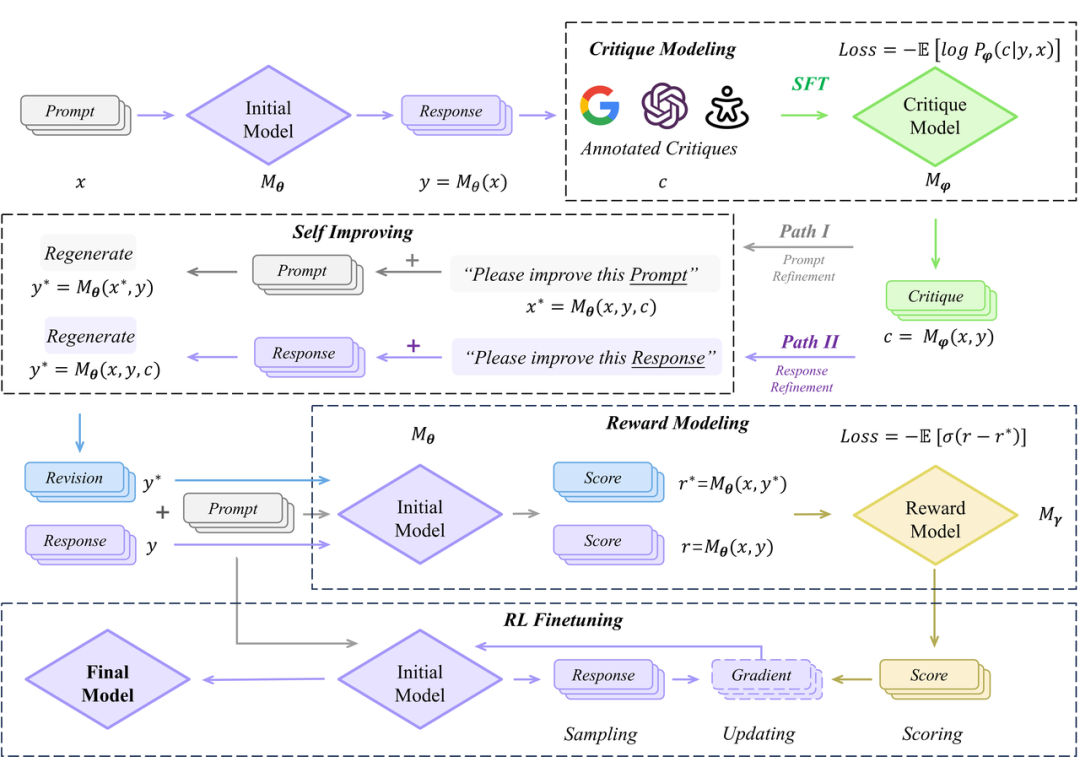
4.3 四大环节
-
评论模型建模:使用交叉熵损失函数,令多模态大模型拟合数据集中的语言反馈,作为评论模型。训练完成的评论模型将对输入的问答对提供评论。
-
模型自提升:令初始模型在给定好 prompt 的数据集上生成一系列 response,再利用评论模型对此生成的评论,令初始模型针对自身的 response 进行修正。
-
奖励建模:将修正后的 response 与原先的 response 拼接,组成偏序对,进行奖励建模,或是 DPO 微调。
-
强化学习微调:基于训练好的奖励模型,完成完整的强化学习微调流程。
4.4 实验结果
北大对齐小组希望LLF能够通过语言反馈提取出更加丰富的偏好信息,从而提升多模态大模型的指令跟随能力。他们已在多种模态上验证了 LLF 的有效性:

LLF 合成的偏好对反映了更加统一的人类偏好,增强了所有模态的对齐性能。我们观察到,当使用二元对时,DPO 和 PPO 在某些模态上存在负提升。然而,采用 LLF 后,它们在所有模态上都表现出积极的改进。
有趣的是,北大对齐小组发现 LLF 对 LLaVA-13B 的改进要大于对 LLaVA-7B 的改进。这表明 LLF 在更强大的模型上的表现更好。

更惊喜的是,北大对齐小组通过更进一步的实验观察到,少量 LLF 数据对于对齐算法的提升大于大量的二元偏好数据,两者的差异最大可以是 1:4。
如上图所示,北大对齐小组使用相较于二元偏好数据集的 25%、50%、75% 的语言反馈数据集训练评论模型,随后令其合成与二元偏好数据集等量的偏好数据,并进行对齐微调。
结果表明,即便是 25% 的语言反馈,仍能令评论模型合成出效果更好的二元偏好数据集。这更加充分地表明:LLF 能够通过语言反馈提取出更加丰富的偏好信息,从而提升多模态大模型的指令跟随能力。

全模态评估:模态联动与模态选择
全模态模型旨在理解各个模态,并结合它们的信息以生成高质量的响应。为了评估它们的综合多模态处理能力,我们创建了 164 个测试条目,每个条目都包含文本、视觉(图像或视频)和听觉(音频或语音)组件。
这些相互关联的模态要求模型准确整合所有输入,因为任何一个模态的失败都会导致错误的答案。例如,如果一个模型未能处理视觉输入,它可能会错过图片中的人感到害怕这一点。同样,如果没有听觉处理,它可能无法理解这个人的恐惧是由于狗在吠叫。
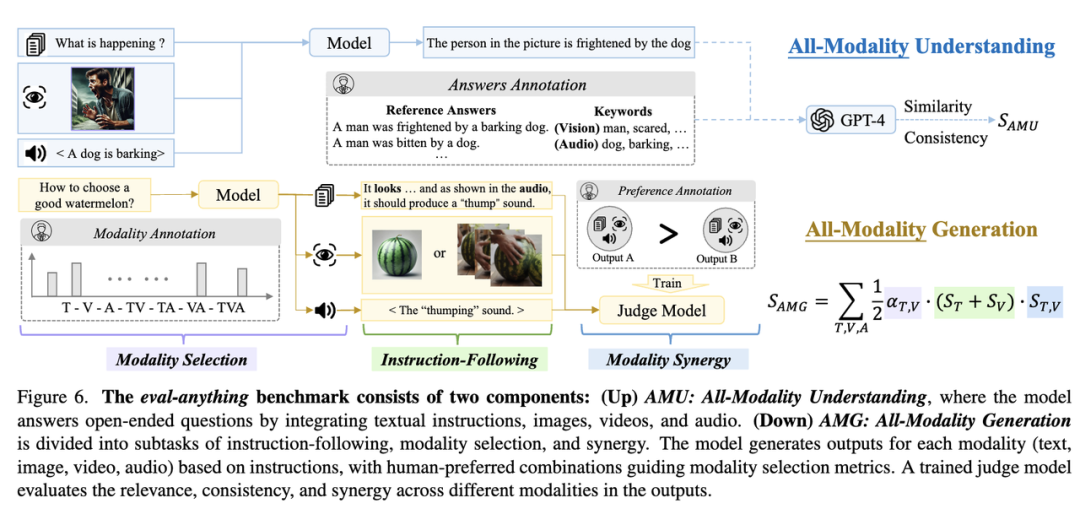
5.1 模态联动
-
不同模态输出之间具有相关性和一致性,不能毫不相干或者自相矛盾。
-
相关性:不同模态信息具有明显关联。
-
一致性:不同模态信息表达的对象或者观点一致。
-
不同模态输出之间能够相辅相成,互相进行信息的补充,例如:
-
文字中提到到图片(视频)或音频,图片(视频)或音频信息能够作为文字信息的补充。
-
图片(视频)和音频信息分别对同一个对象进行了描述,视觉信息和音频信息相互结合,营造丰富的场景信息。

AMG 任务的示例如上所示,北大对齐小组创建了两个不同的指令测试集,用于评估 AMG 任务的三个指标,将指令遵循部分根据模态划分为四个子集。这样做的理由是,在多模态场景中,评估指令遵循能力需要特定的指令来考察模型生成与指令一致的内容的能力。
5.2 模态选择
-
对于给定问题,选择适当的模态进行回答,从而能更好地回答该问题。
-
选择模态时应当考虑必要性和简洁性,对回答问题帮助不大的模态是不必要的。
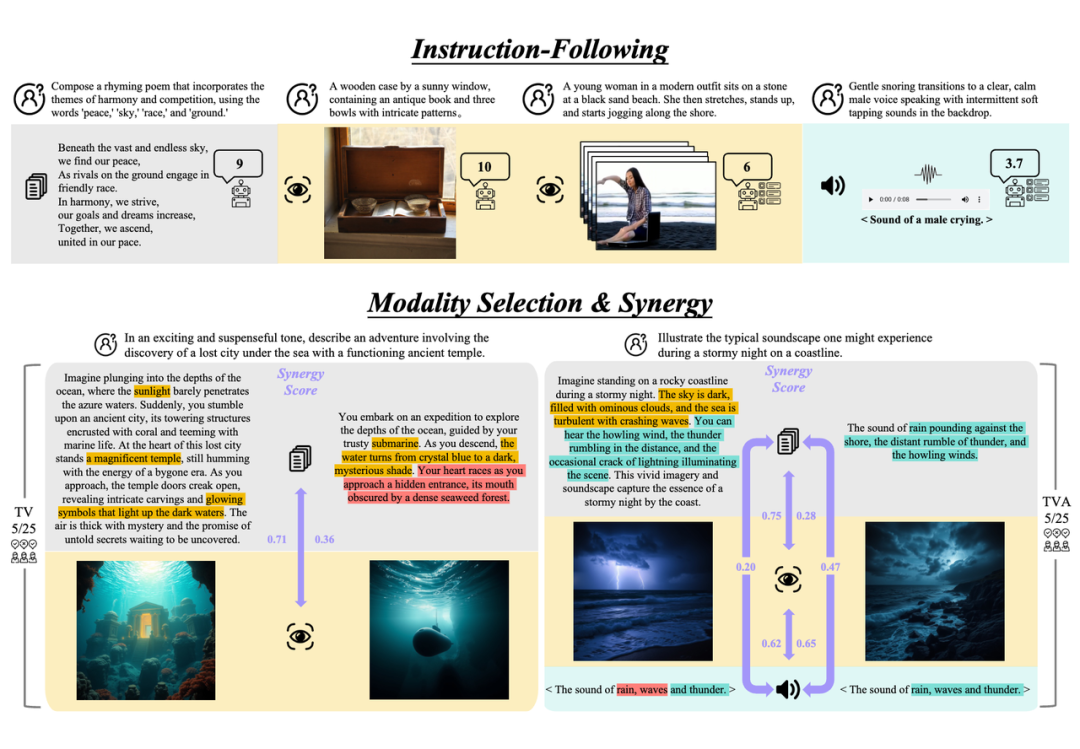
AMU 任务的一个例子如上所示:在左上角展示了测试数据的样本,这些数据包括一段视觉信息、一段听觉信息以及一个问题。右侧则给出了标注人员提供的标注示例。对于开放性问题,每位标注员的回答可能会有所不同。
但是,只要答案正确地回应了多模态的信息,就会被接受为参考答案。在左下角显示了不同模型对同一测试数据的回答。模型能够识别的模态越多,它的回复就能包含越多的细节,从而产生更高质量的回答,并因此获得更高的评分。
简单来说,这个任务是关于如何结合图片(看得到的信息)和声音(听得见的信息)来回答问题。不同的专家给出的答案可以不一样,只要合理解释了给定的信息就算对。多模态大模型尝试做同样的事情,它们理解的信息越全面,给出的答案就越细致和准确,得分也就越高。
5.3 测评结果
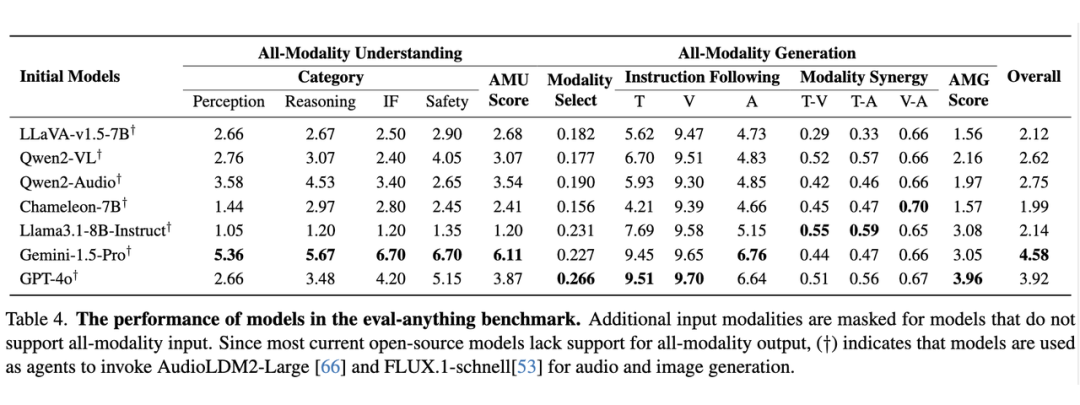
当前的模型仍然远远落后于全模态模型。在全模态理解方面,仅使用单一模态的模型得分不到最高分的一半。即使是处理视觉和听觉输入的 Gemini-1.5-Pro,也未能获得满分。与人类不同,这些模型无法以完全整合的方式感知不同的模态,尽管它们在单个模态内的表现几乎达到了人类水平。
此外,在选择输出模态时,模型与人类的选择不太一致。人类可以根据指令自适应地选择最佳的模态组合,而模型往往只输出文本信息,导致信息丢失,或者输出所有可用模态,导致冗余。有限的多模态能力,尤其是在主要基于文本训练的模型中,阻碍了它们有效综合信息的能力,使得在细节和简洁之间取得平衡变得困难。

基于 align-anything 框架,对 LLaMA-3.2-11B-Vision 进行指令跟随对齐
LLaMA-3.2-11B-Vision 是最新 LLaMA-3.2 系列中以图文问答见长的模型,北大对齐小组使用他们提出的 align-anything-Instruct 数据集对该模型进行了细致的指令微调,得到了 Beaver-Vision-11B。
该模型在多个开源评测榜上超越了 Meta 官方发布的指令微调版本 LLaMA-3.2-11B-Vision-Instruct,表现出了更强的指令跟随能力与图像识别能力。



基于 align-anything 框架,实现 Chameleon 全模态激活与对齐
北大对齐小组基于 Meta的Chameleon-7B,使用了 laion-art 数据集激活了 Chameleon 模型的图像生成能力,并开源了以这个方式训练得到的 AA-Chameleon-7B-Base 模型。
他们随后使用 align-anything 数据集的图文联合数据对该模型进行对齐,开源了 AA-Chameleon-7B-Plus 模型。同时北大对齐小组也开源了首个对 Chameleon 进行图文模态输入/输出的 DPO 与 PPO 两大经典对齐算法的实现。
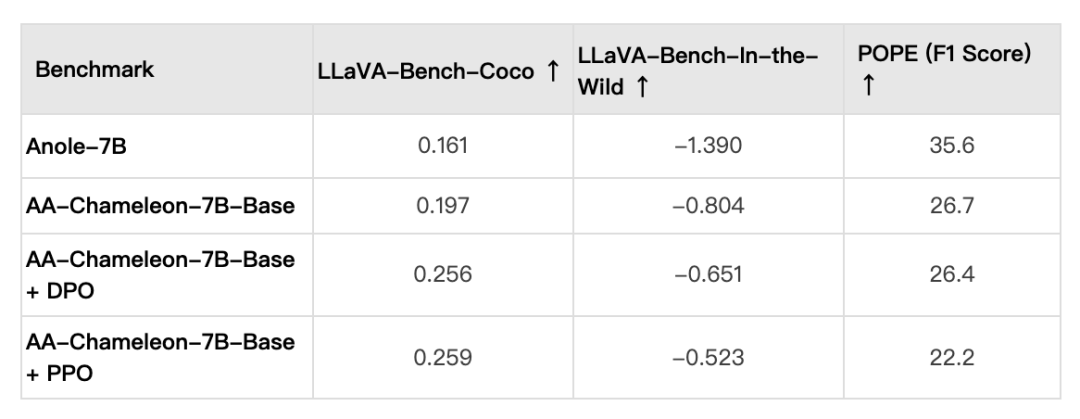
在图文联合输入/输出评测中,对齐后模型和对齐前模型比较,GPT-4o 评测胜率超过 80%。以下为对齐前后的一些实例比较:

本开源项目由北京大学对齐小组开发并进行长期维护,团队专注于人工智能系统的安全交互与价值对齐,指导老师为北京大学人工智能研究院杨耀东助理教授。核心成员包括吉嘉铭、周嘉懿、邱天异、陈博远、王恺乐、洪东海、楼翰涛、王旭尧、张钊为、汪明志、钟伊凡等。
团队就强化学习方法及大模型的后训练对齐技术开展了一系列重要工作,包括 Aligner(NeurIPS 2024 Oral)、ProgressGym(NeurIPS 2024 Spotlight)以及 Safe-RLHF(ICLR 2024 Spotlight)等系列成果。近期,团队针对 OpenAI o1 技术的深入分析累计点击量已超过 15 万。
(文:PaperWeekly)
全模态对齐真的太难了!开源项目大多功能有限,不如自己动手研发才是王道啊~