

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
-
论文标题:WebWalker: Benchmarking LLMs in Web Traversal
-
论文地址:https://arxiv.org/pdf/2501.07572
-
Homepage 地址:
https://alibaba-nlp.github.io/WebWalker/
-
Modelscope Demo 地址:
https://www.modelscope.cn/studios/jialongwu/WebWalker
-
Huggingface Demo 地址:
https://huggingface.co/spaces/callanwu/WebWalker
-
Dataset 地址:
https://huggingface.co/datasets/callanwu/WebWalkerQA
-
Leaderboard 地址: https://huggingface.co/spaces/callanwu/WebWalkerQALeadeboard
-
Github 地址:
https://github.com/Alibaba-NLP/WebWalker
-
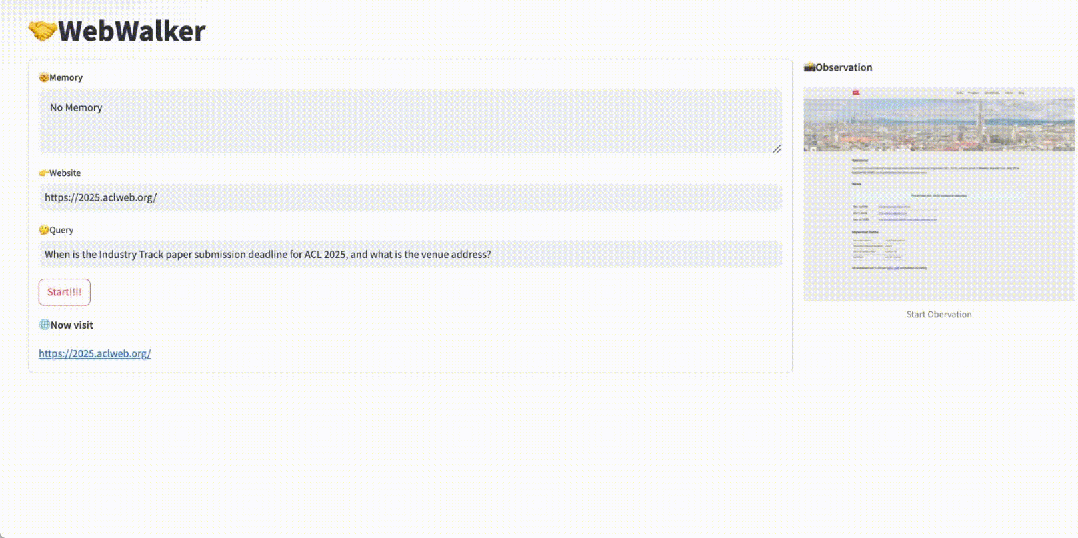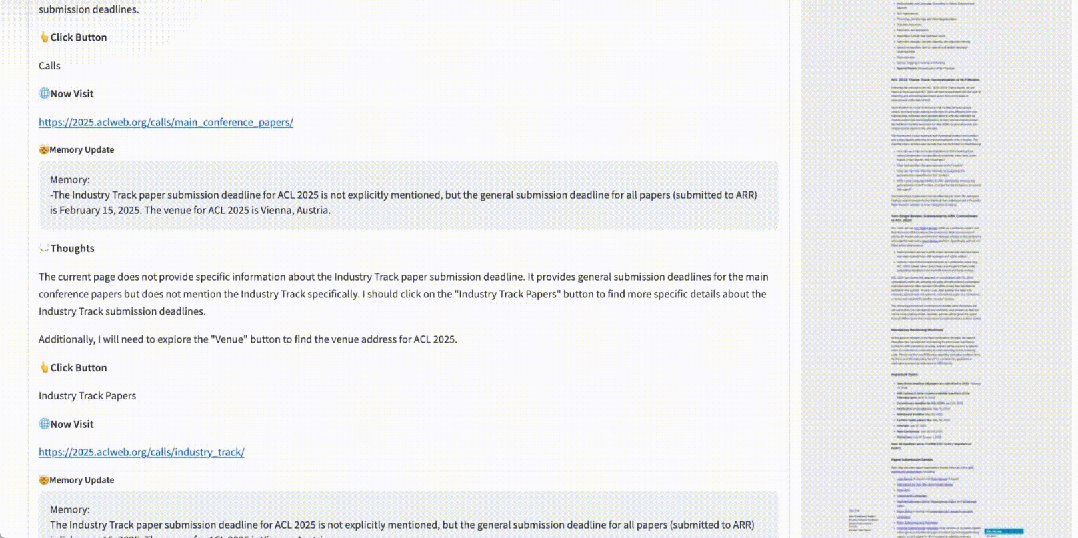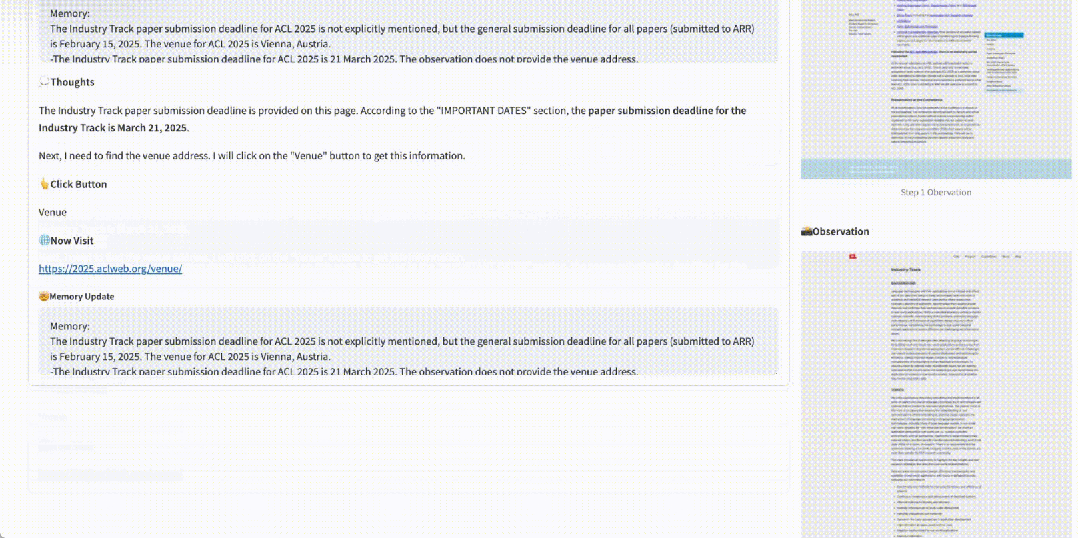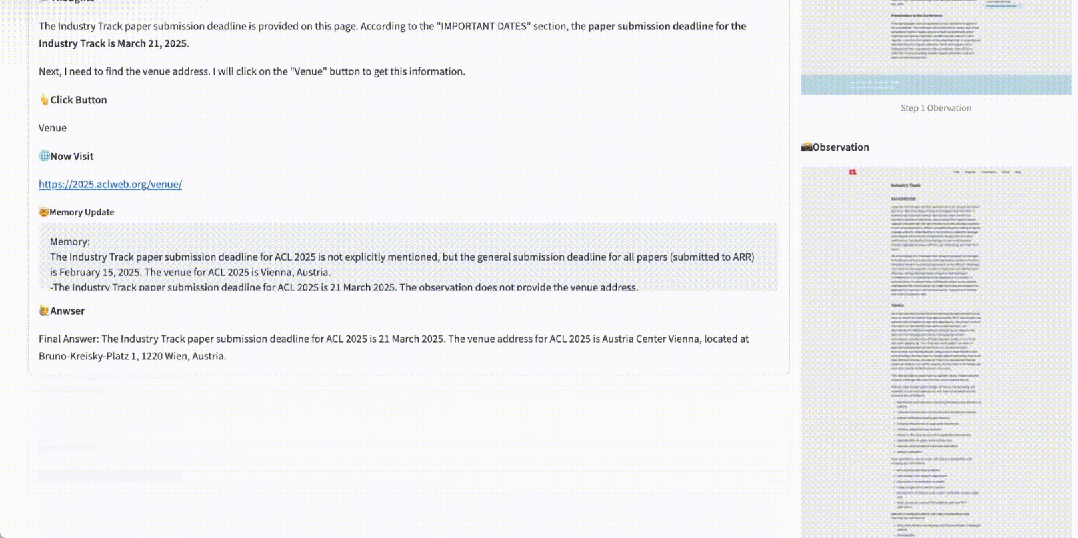
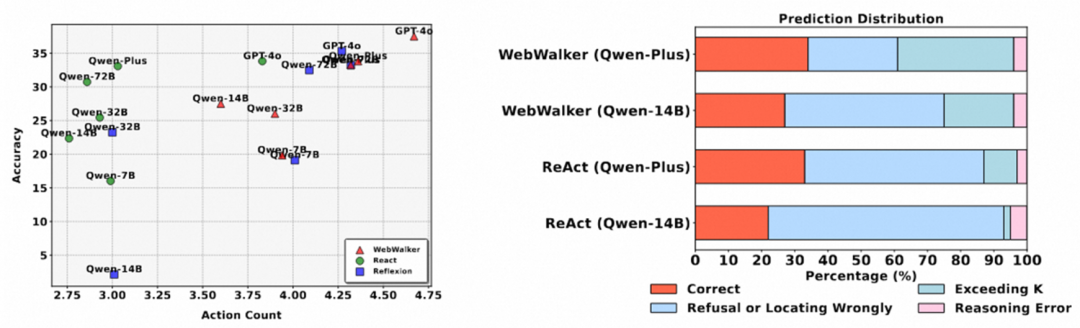
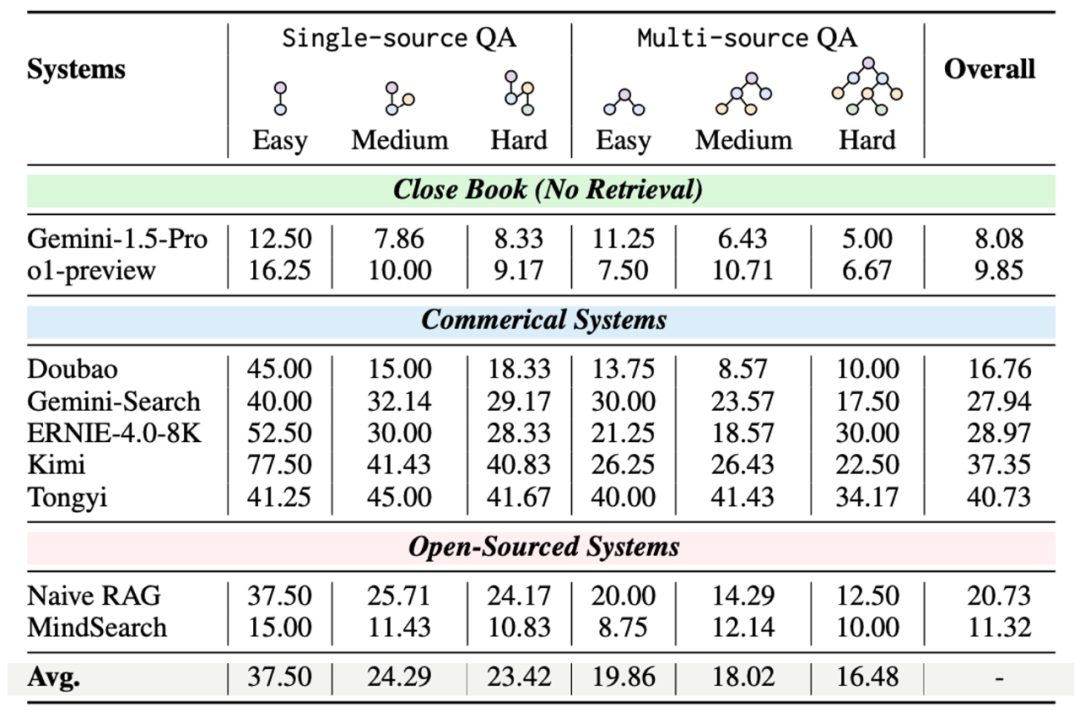
网页导航寻找信息仍比较困难:在需要规划和推理的任务中,网页导航任务仍需进行进一步的研究和探索。
-
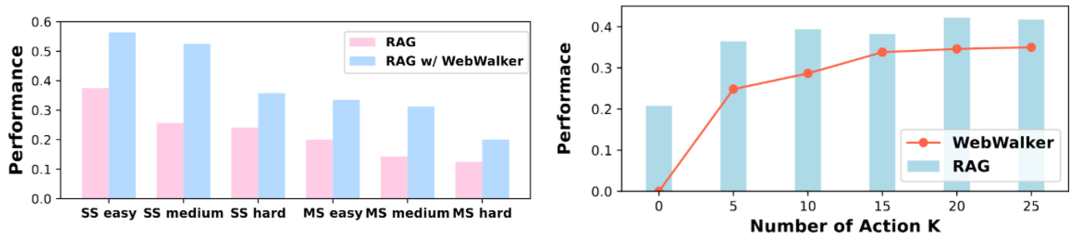
结合 RAG 有效:RAG 与 WebWalker 的结合,在信息检索问答任务中展现出强大效果。这种协同作用不仅提升了信息检索的效率,还为处理复杂任务提供了强大的支持。Agentic 的二维 RAG 会很有帮助。
-
垂直探索有潜力:页面的垂直探索为 RAG 系统 test-time 的扩展提供了新思路。突破迭代搜索的范式,对页面进行垂直探索。
-
数据规模:目前 WebWalkerQA 仅包含 680 个高质量问答对,规模有限,还有拓展空间。
-
多模态拓展:目前仅基于 HTML-DOM 解析,未来可结合视觉模态如截图,提供更直观的交互体验。
-
Agent 微调:WebWalker 目前仅靠提示驱动,后续可通过精细调优,让大模型更好地掌握网页浏览技巧。
-
Momory 与 rag 结合:目前是给定了 webwalker 页面进行了挖掘,如果想与 rag 链路进行更好的结合,可以对 query 进行改写到官网定位,再进行挖掘,把 memory 和正常检索到的知识一起作为检索增强的知识,这样结合更自然。
(文:机器之心)