


划重点:
❶ 中国AI团队强势崛起!Qwen2.5系列实现多模态理解、百万字长文本处理、超大规模模型三大突破
❷ 新一代视觉语言模型Qwen2.5-VL可直接操控电脑手机,视频理解能力达小时级,发票表格秒变结构化数据,3B小模型性能超越前代7B
❸ 全球首个开源百万token上下文模型Qwen2.5-1M,推理速度提升7倍,DCA技术实现长文本无损记忆,性能碾压GPT-4o-mini
❹ 200万亿token训练的MoE巨兽Qwen2.5-Max问世,多项基准测试超越DeepSeek V3和Llama3.1,API已开放
(全文约3900字,阅读需9分钟)
一、AI春晚的中国时刻:从Sora独舞到双雄争霸
当全球还在回味OpenAI用Sora上演的”AI魔术秀”时,来自中国的两支团队已悄然完成技术集结。DeepSeek接连推出V3、R1、Junas三款明星模型,而Qwen则以“三连发”震撼业界——视觉理解的Qwen2.5-VL、百万上下文的Qwen2.5-1M、MoE巨兽Qwen2.5-Max组成技术矩阵,在硅谷巨头垄断的AI战场撕开突破口。
这场同城竞技绝非偶然:在杭州这片创新沃土上,两家公司的研发团队如同隐世高手,西湖论剑,共听钱塘潮,工程师们在同一片天空下,激荡着transformer架构的优化灵感,这种“硅巷式”的创新生态,正孕育出改变AI格局的中国力量。

二、Qwen2.5-VL:让AI真正看懂世界
▶ 多模态认知革命
当主流模型还在比拼图像识别准确率时,Qwen2.5-VL已进化出“视觉思维”:不仅能识别兵马俑的铠甲纹路,还能解析纪录片中的历史脉络;看到骑摩托未戴头盔者,会自动标注坐标并触发预警系统。这种“认知-决策”闭环,让AI从工具升级为智能体。它不仅能理解静态图像,还能深入分析动态视频,真正实现了“看懂世界”。例如,在教育领域,Qwen2.5-VL可以帮助学生更深入地理解抽象的概念,在安防领域,它能自动识别潜在的危险行为,为安全防护提供更强的技术保障。
▶ 五大杀手锏解析
| 技术突破 | 商业价值 | 实测案例 |
| 时空感知编码 | 1小时视频摘要提取效率提升40% | 教学视频秒变知识图谱、体育赛事精彩瞬间回放 |
| 动态分辨率ViT | 图像处理能耗降低60% | 4K医学影像实时分析、无人驾驶环境感知 |
| 结构化数据输出 | 财务单据处理人力节省75% | 复杂报表自动生成JSON、智能财税分析 |
| 跨设备操控 | RPA流程自动化成本降低30% | 自动订票+日程规划、智能家居联动 |
| 小模型逆袭 | 端侧部署成本下降80% | 3B模型超越前代7B性能、边缘AI计算 |
▶ 开发者实测:
“用Qwen2.5-VL处理建筑图纸,不仅能识别管道走向,还能自动标注不符合消防规范的区域,这相当于雇佣了一个专业监理团队。”——某智慧城市项目负责人
▶ 细节强化:
-
• 全球图像识别: Qwen2.5-VL 的图像识别能力覆盖范围广,不仅包括植物、动物、地标建筑,还包括影视IP和各种商品,能够精准识别并给出中英文名称。
-
• 精确物体定位: Qwen2.5-VL 使用边界框和点精确定位图像中的物体,并输出标准化的JSON格式坐标和属性,实现精细化感知。
-
• 增强文本识别: Qwen2.5-VL 升级了OCR识别能力,能够进行多场景、多语言和多方向的文本识别和定位,信息提取能力也得到了显著提升,满足数字化和智能化需求。
-
• 强大文档解析: Qwen2.5-VL 设计了独特的QwenVL HTML格式,能够解析杂志、研究论文、网页,甚至移动截图等各种文档,并提取布局信息。
-
• 卓越视频理解: Qwen2.5-VL 采用了动态帧率训练和绝对时间编码技术,不仅支持小时级的超长视频理解,还能够精确定位视频中的事件,提取关键信息。
-
• 卓越的计算机和移动代理能力: Qwen2.5-VL能够执行计算机和移动端的任务,例如在预定App中预定机票,具备了强大的智能代理能力。
-
• 模型更新: Qwen2.5-VL 增强了时间尺度和空间尺度的感知,并简化了网络结构,提高了模型效率。
-
• 视觉编码器创新: Qwen2.5-VL 训练了动态分辨率ViT,并引入窗口注意力机制,有效降低了计算负载,使得模型更加高效。
 (Qwen2.5-VL准确识别世界各地的著名景点,展现其强大的图像识别能力)
(Qwen2.5-VL准确识别世界各地的著名景点,展现其强大的图像识别能力)
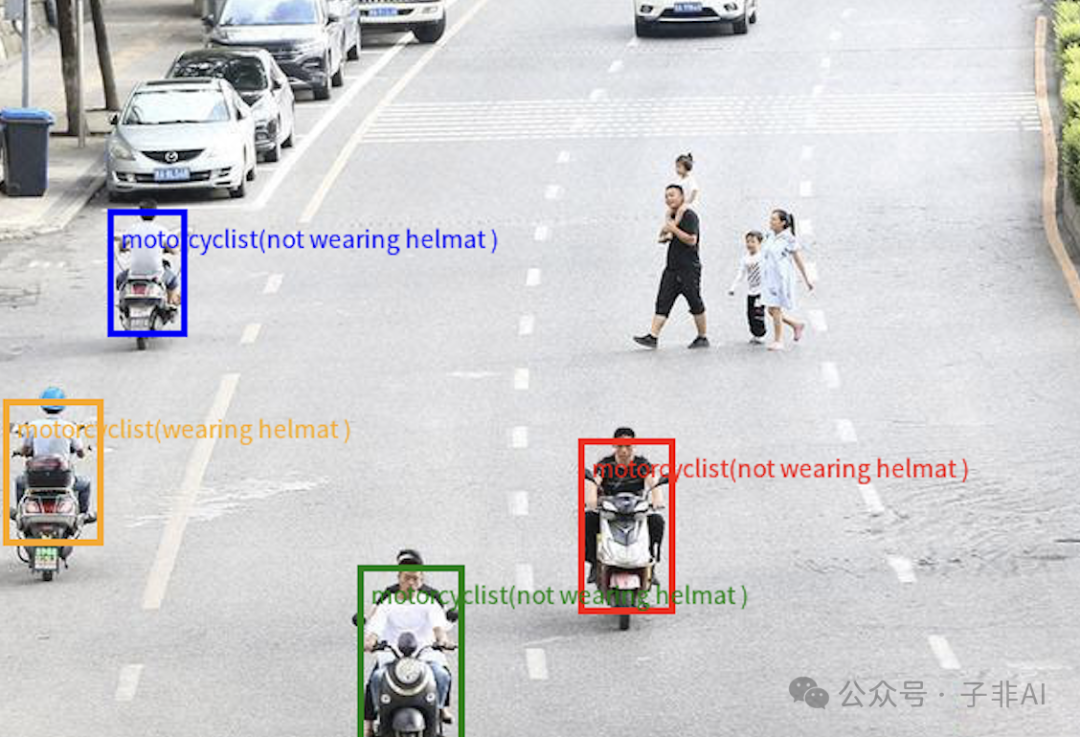

三、Qwen2.5-1M:突破语言模型的”记忆诅咒”
百万token上下文不只是数字游戏
当同行还在为32K上下文挣扎时,Qwen2.5-1M直接将竞技场拉升到百万量级。这个数字意味着:
-
• 完整处理《三体》三部曲(约90万字),并理解其复杂的人物关系和科幻设定
-
• 实时分析上市公司十年财报,快速提取关键的财务指标和趋势
-
• 构建跨文档知识图谱,将不同来源的信息进行整合和关联,为知识管理提供强大工具
技术揭秘双引擎
-
1. DCA注意力机制
通过位置编码重映射,解决长程依赖衰减问题,就像给AI装上”记忆索引卡”,在百万字长文中精准锁定关键信息,让AI具备了真正的“长时记忆”能力。DCA技术的核心在于将相对位置映射到更小的数值,避免了训练过程中未见过的大距离,从而有效解决了RoPE在长文本处理中的性能瓶颈,无需进行额外的训练。 -
2. 动态推理加速
基于vLLM框架和稀疏注意力机制,使100万token处理速度提升7倍。实测中,处理整本《经济学原理》仅需17秒,且准确率保持在98%以上,这为长文本分析和处理提供了强大的算力支持。
MInference框架: Qwen2.5-1M 引入了基于MInference 的稀疏注意力机制,显著加速了预填充阶段,并进行了优化,包括与Chunked Prefill的集成,与长度外推技术的结合,以及对长序列进行稀疏优化。
开源生态建设
同步开源的7B/14B模型,让中小团队也能享受长文本红利。某法律科技公司反馈:”用14B模型分析裁判文书,争议焦点归纳准确率从78%提升至93%,极大地提高了工作效率和准确性。” 这不仅降低了技术门槛,也促进了AI技术的普及和应用。
▶ 细节强化:
-
• 长文本训练: Qwen2.5-1M 采用了多阶段训练方法,逐步扩大上下文长度,并使用调整后的基础频率,保证长文本处理能力。
-
• 监督微调: Qwen2.5-1M 将监督微调分为两个阶段,在短指令和长短混合指令上进行微调,保证长文本性能的同时不损失短文本性能。
-
• 稀疏注意力: 基于 MInference 的稀疏注意力机制,加速预填充阶段,并引入多种优化措施,提高了推理效率。
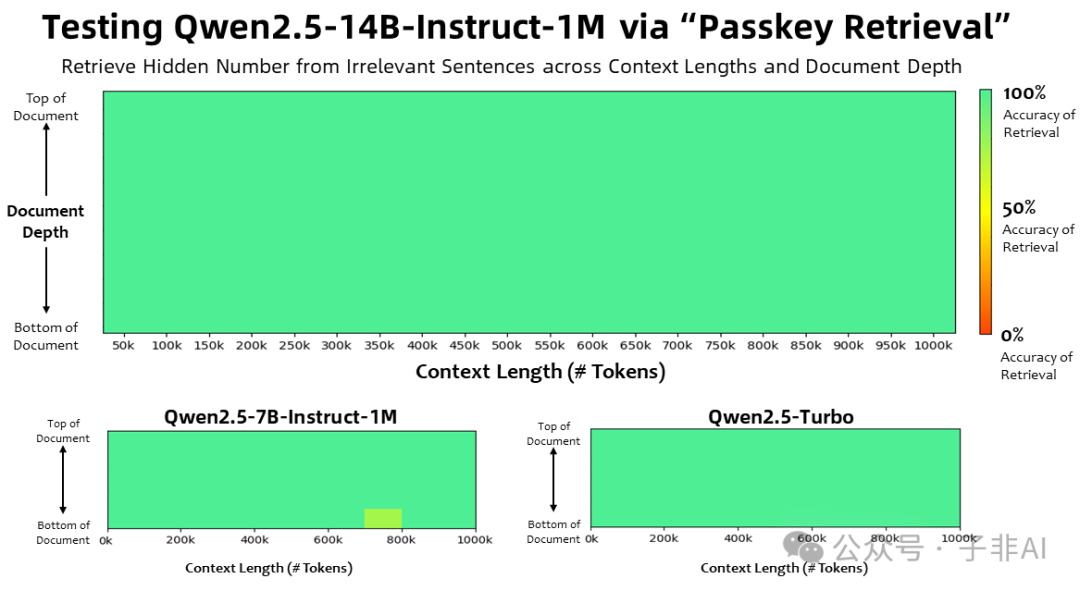
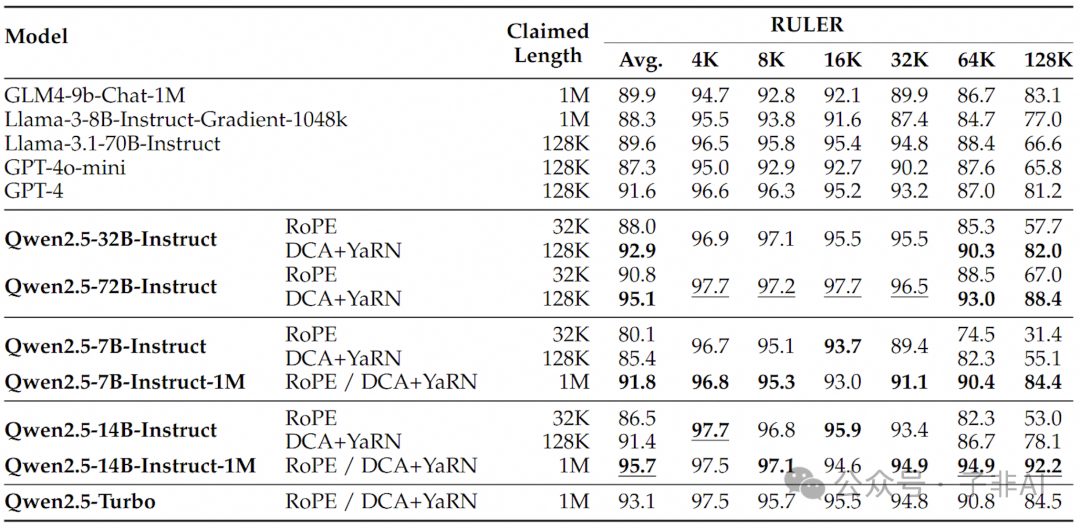 (Qwen2.5-1M在RULER基准测试中表现优异,展现其强大的长文本理解能力)
(Qwen2.5-1M在RULER基准测试中表现优异,展现其强大的长文本理解能力)
四、Qwen2.5-Max:中国版”超级大脑”诞生
200万亿token炼成的MoE巨兽
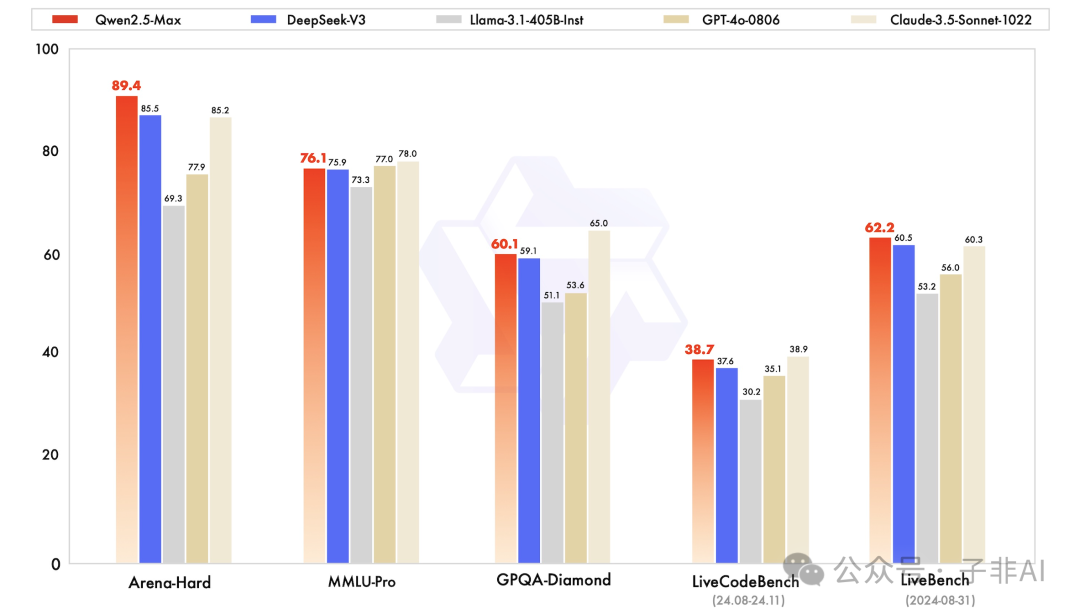
这个数字是GPT-4训练量的2.5倍,造就了当前最聪明的中文AI大脑。其在GPQA钻石级难题测试中展现的推理能力,已接近人类专家水平,这不仅是简单的知识记忆,更是对复杂问题的深入理解和推理。
性能碾压现场
-
• 代码生成:LiveCodeBench得分超越DeepSeek V3 15%,这意味着Qwen2.5-Max在代码生成方面具备了更高的效率和准确性。
-
• 专业问答:MMLU-Pro法律子项准确率达91.2%,体现了其在专业领域知识的深入理解。
-
• 多步推理:在“鸡兔同笼”变种题中,模型展现出强大的数学归纳能力,能够理解不同变体的题目并给出准确答案。不仅能计算简单的鸡兔数量,还能处理更复杂的变体,例如:给出总头数和腿数,然后给出新的条件(例如,每只鸡多一条腿,每只兔子少一条腿),并询问变化后的鸡兔数量,甚至能够进行更复杂的推导,展现出超越人类水平的推理能力。
企业级应用场景
已接入某头部券商智能投研系统,能同时处理20份年报、50篇研报、实时新闻流,自动生成投资风险评估,响应速度较传统方案提升6倍,这意味着,Qwen2.5-Max可以帮助投资机构更快速、更准确地做出决策。
▶ 细节强化:
-
• 大规模MoE模型: Qwen2.5-Max 基于MoE架构,经过超过20万亿token的预训练,并在SFT和RLHF方法上进行了后训练。
-
• 指令模型: Qwen2.5-Max 在Arena-Hard、LiveBench、LiveCodeBench和GPQA-Diamond等基准测试中超越了DeepSeek V3,并在MMLU-Pro等其他评估中表现出竞争优势。
-
• 基础模型: Qwen2.5-Max 的基础模型在大多数基准测试中表现出显著的优势,领先于DeepSeek V3、Llama-3.1-405B和Qwen2.5-72B等开源模型。
-
• API开放: Qwen2.5-Max 的API已开放,用户可以通过Alibaba Cloud Model Studio 获取API Key,并使用兼容 OpenAI API 的方式进行调用。
五、技术深水区的中国方案
▶ DCA架构
通过双区块注意力机制,将位置编码转化为可学习的相对距离矩阵,破解了困扰业界的”长文本失忆症”。该技术已在美国专利局公开,成为中国AI在长文本处理领域的一项重要突破。
▶ 轻量化视觉引擎
动态分辨率+窗口注意力的组合,使4K图像处理显存占用下降70%,让高端视觉能力可部署在千元级显卡上,这为AI技术在终端设备上的应用提供了可能。
▶ MoE训练革命
采用“预训练-领域微调-强化学习”三段式训练法,使模型在通用智能和垂直领域表现取得平衡,避免“通才变庸才”的陷阱,使其在具备强大通用能力的同时,还能在特定领域表现出卓越的性能。
六、AI 2.0时代的启示
Qwen2.5系列的突破,标志着中国AI正在完成从“跟跑”到“并跑”的关键转身。当视觉模型开始理解世界本质、语言模型突破记忆边界、大模型显现推理火花时,我们看到的不仅是技术参数的提升,更是通用人工智能(AGI)的曙光。
在杭州这片充满创新活力的土地上,西湖论剑,共听钱塘潮,工程师们正在用体系化的技术创新,重新定义智能时代的游戏规则。当美国团队还在执着于参数竞赛时,中国团队正在以更务实的态度和创新的方法,引领着AI技术的发展方向。
推荐阅读
-
2024 年度 AI 报告(一):Menlo 解读企业级 AI 趋势,掘金 AI 时代的行动指南 2024年度AI报告(二):来自Translink的前瞻性趋势解读 – 投资人与创业者必看 2024年度AI报告(三):ARK 木头姐对人形机器人的深度洞察 2024年度AI报告(四):洞察未来科技趋势 – a16z 2025 技术展望 2024年度AI报告(五):中国信通院《人工智能发展报告(2024)》深度解读 2025 AI 展望 (一):LLM 之上是 Agent AI,探索多模态交互的未来视界 2025 AI 展望 (二):红杉资本展望2025——人工智能的基础与未来 2025 AI 展望(三):Snowflake 洞察 – AI 驱动的未来,机遇、挑战与变革 -
2025 AI 展望(四):OpenAI 的 AGI 经济学 -
• Qwen2.5-VL 官方博客: https://qwenlm.github.io/blog/qwen2.5-vl/
-
• Qwen2.5-1M 官方博客: https://qwenlm.github.io/blog/qwen2.5-1m/
-
• Qwen2.5-Max 官方博客: https://qwenlm.github.io/blog/qwen2.5-max/
(文:子非AI)