

-
R1-Zero不依赖人类专家标注(SFT),而是通过强化学习(RL)进行训练; -
在某些领域,SFT并非必要,且R1-Zero能够通过RL优化创建自己的领域特定语言(DSL);
-
R1-Zero展示了无需人类标注即可实现准确推理的潜力,这对于扩大AI系统的应用范围具有重要意义。


通过强化学习(RL),3B大模型(Qwen2.5-3B)能够自主发展自我验证和搜索能力,且成本不到 30美元。
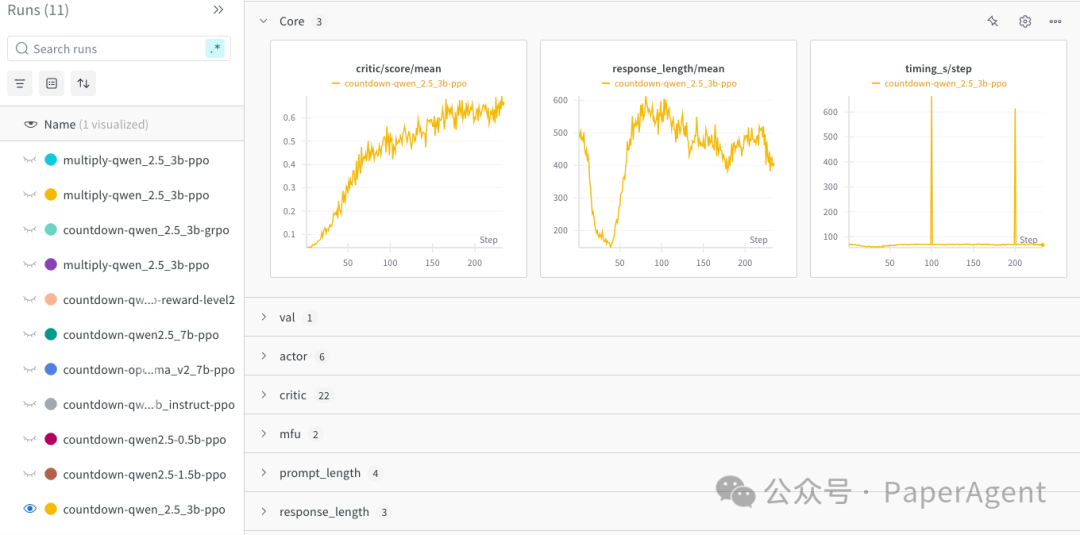
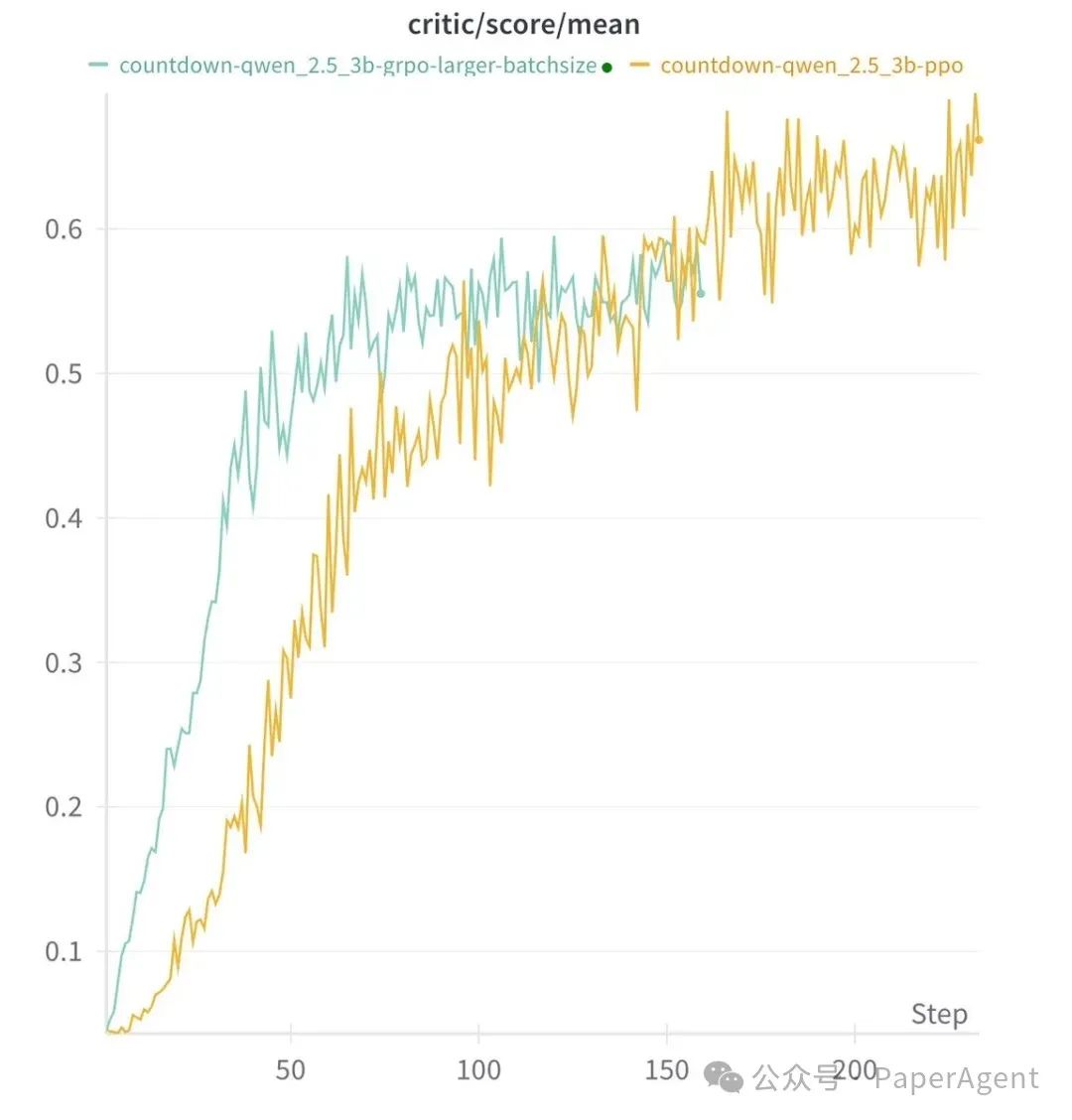
TinyZero尝试了不同RL方法:PPO、GRPO,它们似乎都运行良好,Long COT 也出现了。
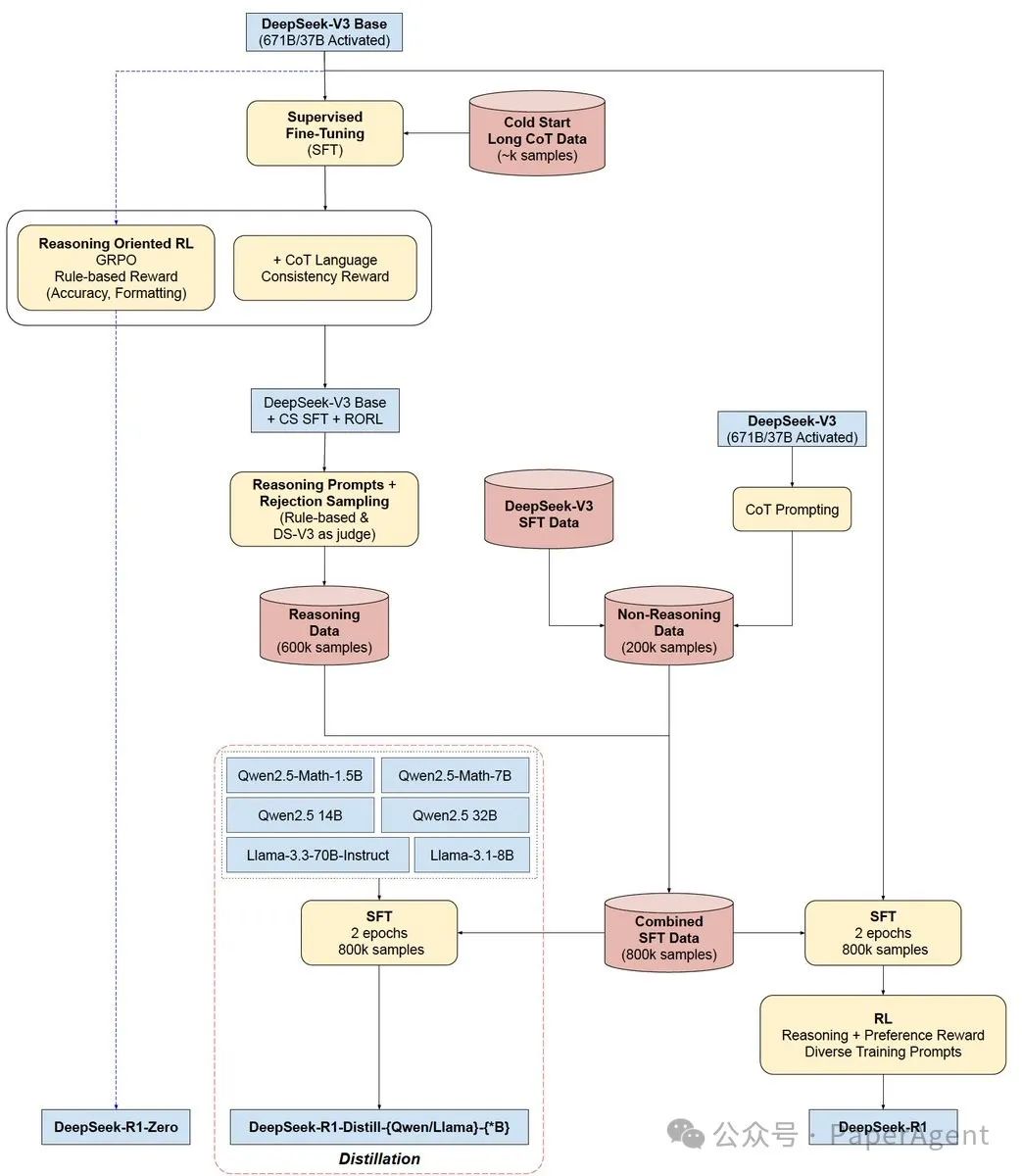
DeepSeek-R1/R1-Zero训练架构图回顾
R1-Zero和R1都是基于DeepSeek V3 Base模型的扩展,但它们在训练过程中采用了不同的方法和数据。R1-Zero更侧重于强化学习,而R1则结合了监督式微调和强化学习。
https://github.com/Jiayi-Pan/TinyZerohttps://arcprize.org/blog/r1-zero-r1-results-analysis
(文:PaperAgent)
R1-Zero确实很强!开源界又一里程碑!用强化学习自定义领域语言,3B模型不到30美元就能实现顶尖推理能力,直接干翻现有技术!
R1-Zero秒杀R1,强化学习才是硬道理!开源项目5.8k星,玩转强化学习界的骚操作