
中科院&中科大&腾讯微信AI部联合推出最新(2025.02)DeepRAG,让大型语言模型逐步推理检索:

DeepRAG框架将检索增强推理建模为马尔可夫决策过程(MDP),通过迭代分解查询,动态决定是否检索外部知识或依赖参数推理。
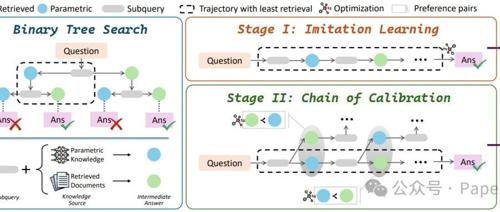
DeepRAG 框架的概述,包括三个步骤:(1)二叉树搜索,(2)模仿学习,以及(3)校准链。给定一个数据集,首先使用二叉树搜索来合成模仿学习的数据,使模型能够学习检索模式。随后,利用二叉树搜索构建偏好数据,以进一步校准 LLM 对其知识边界的认知。
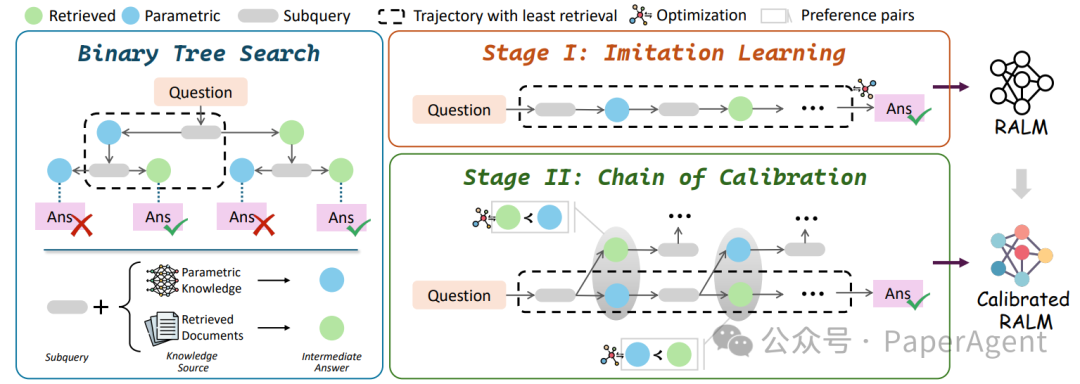
框架包含三个关键步骤:
-
二叉树搜索(Binary Tree Search):为每个子查询构建二叉树,探索基于参数知识或外部知识库的不同回答策略。通过这种方式,模型不仅分解问题,还彻底检查检索选择对最终答案的影响。
-
模仿学习(Imitation Learning):使用优先队列高效探索潜在推理轨迹,优先考虑检索成本较低的路径。通过二叉树搜索合成数据,让模型学习有效的检索模式,并通过模仿学习提取到达正确最终答案的推理过程。
-
校准链(Chain of Calibration):通过合成偏好数据确定何时需要检索,并使用这些数据微调LLMs,增强其基于内部知识边界的原子决策能力。
MDP建模
-
状态(States):表示对原始问题的部分解决方案。
-
动作(Actions):包括终止决策(是否继续生成子查询)和原子决策(是否检索外部知识)。
-
转移(Transitions):根据动作更新状态。
-
奖励(Rewards):基于答案正确性和检索成本评估状态。
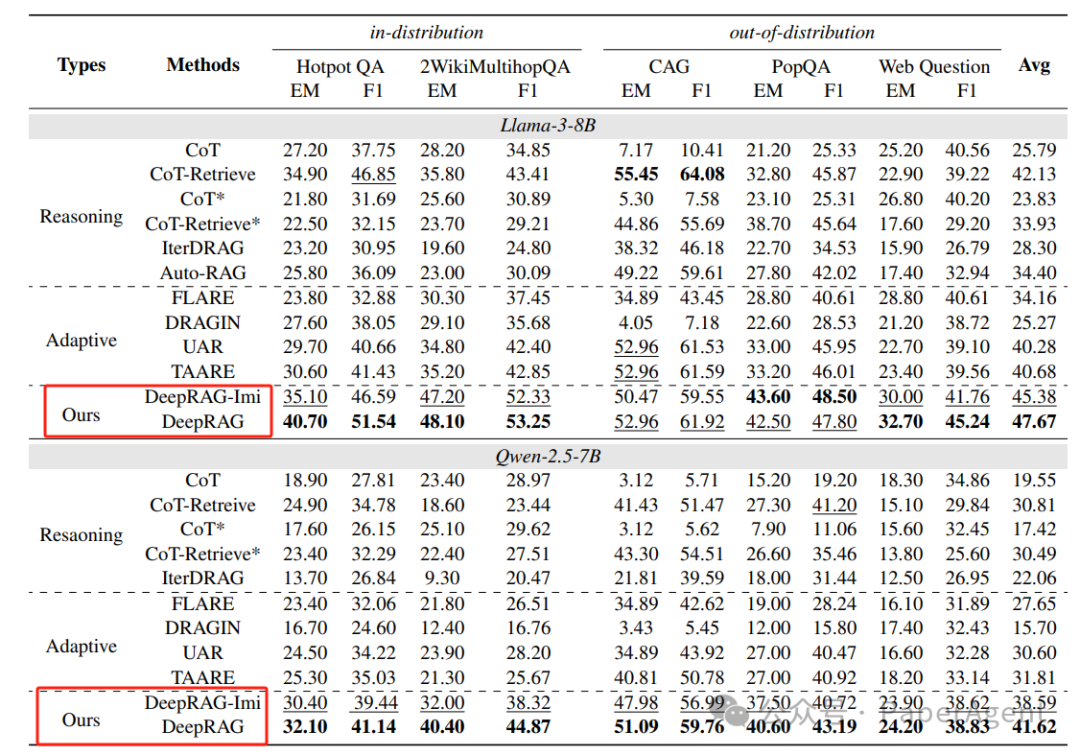
基线:与多种现有方法进行比较,包括CoT、CoT-Retrieve、IterDRAG、UAR、FLARE、DRAGIN、TAARE和AutoRAG。
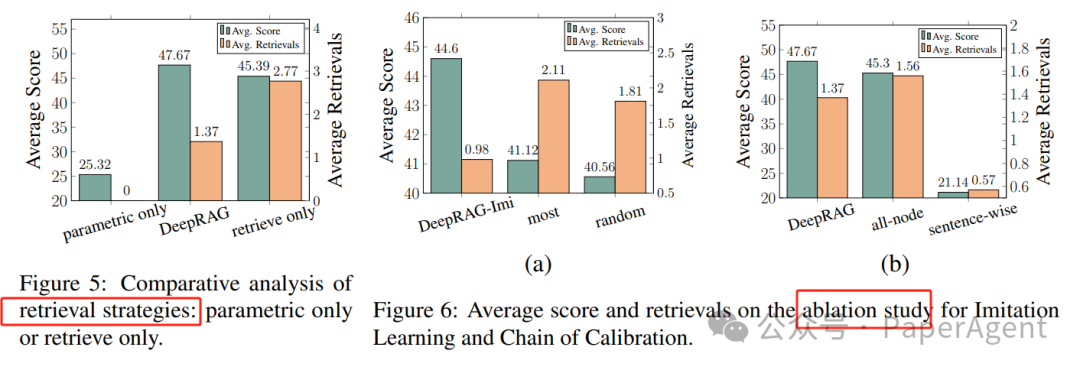
DeepRAG在所有数据集上均优于现有方法,平均答案准确率提高了21.99%,同时提高了检索效率。
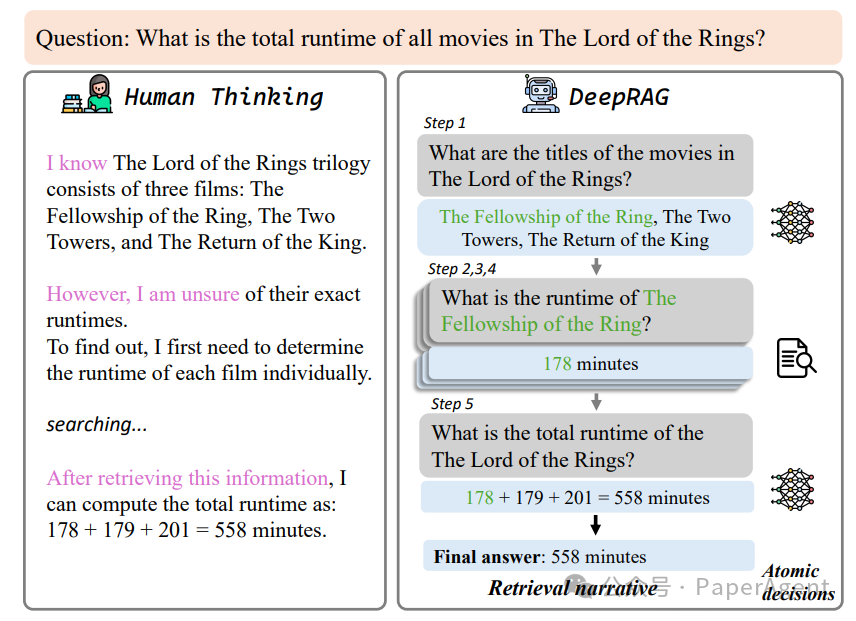
案例研究:Auto-RAG 与 DeepRAG 的对比。DeepRAG 通过原子级查询分解、可靠的中间答案以及自适应地使用内部知识实现了成功。

https://arxiv.org/abs/2502.01142DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
(文:PaperAgent)
现有方法连二叉树都还没学会优化,DeepRAG直接用MDP模型把检索过程变成动态决策树,这操作666!