
测试时扩展(Test-time Scaling)是一种语言建模方法,通过在测试时增加额外的计算来提升性能,OpenAI的o1模型展示了这一点。李飞飞等新作s1(s1-32B模型已开源)旨在寻找一种最简单的测试时扩展方法,以实现强大的推理性能。


s1精心构建了一个包含1000个问题的小型数据集s1K,这些问题都配有推理轨迹,依据三个标准:难度、多样性和质量。开发了预算强制技术,通过强制终止模型的思考过程或延长思考时间来控制测试时的计算量。
推理数据策划以创建s1K:
-
根据三个指导原则:质量、难度和多样性,从16个不同的来源收集了59,029个问题。
-
通过移除API错误问题和格式有问题的字符串模式,最终选择了1K样本。
-
移除了Qwen2.5-7B-Instruct或Qwen2.5-32B-Instruct能够正确解答的问题,样本数量减少到24,496个。
-
根据难度原则,按照倾向于更长推理轨迹的分布,从随机采样的领域中抽取一个问题。
-
重复这一过程,直到收集到总共1000个样本。
测试时扩展:将测试时扩展方法分为两类:
-
顺序扩展,后续计算依赖于早期计算(例如,长推理轨迹)。
-
并行扩展,计算独立运行(例如,多数投票)。ii) 专注于顺序扩展,因为作者直觉认为它应该扩展得更好,因为后续计算可以基于中间结果进行,从而实现更深入的推理和迭代优化。
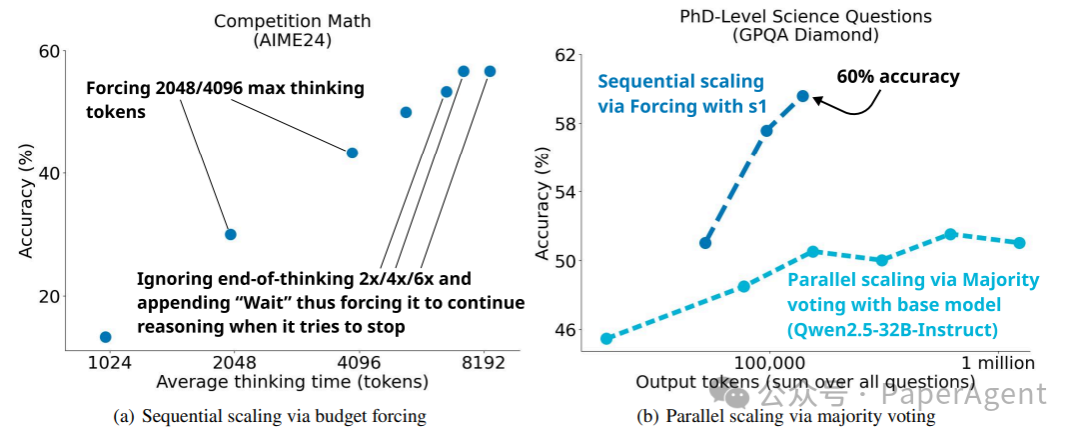
顺序和并行测试时扩展。 (a):预算强制显示出清晰的扩展趋势,并在一定程度上进行外推。对于最右边的三个点,阻止模型停止思考2/4/6次,每次在其当前推理过程后附加“Wait”。(b):对于Qwen2.5-32B-Instruct,对每个样本执行64次评估,温度为1,并在对2、4、8、16、32和64次评估结果进行多数投票时可视化性能。
预算强制:
-
提出了一种简单的解码时干预方法,通过在测试时强制设定最大和/或最小思考token数量。
-
通过简单地添加结束思考token分隔符和“最终答案:”来强制执行最大token数量,从而提前退出思考阶段,让模型提供其当前的最佳答案。
-
为了强制执行最小值,抑制结束思考token分隔符的生成,并可选地将字符串“Wait”附加到模型当前的推理轨迹中,让模型反思其当前的生成内容。

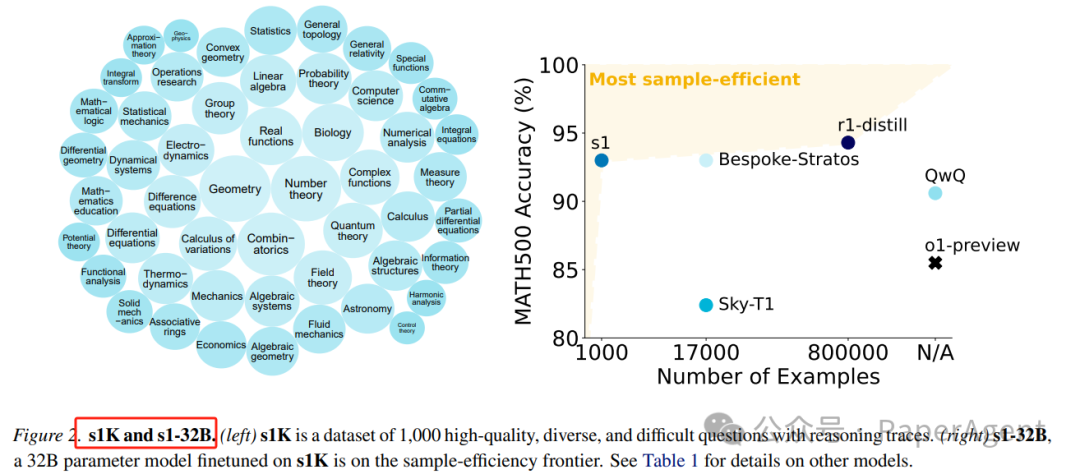
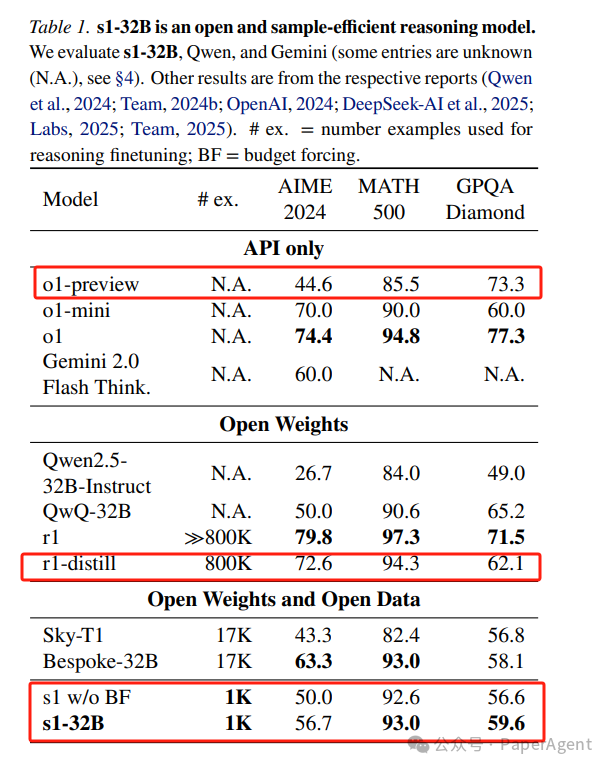
使用Qwen2.5-32B-Instruct语言模型在s1K上进行监督微调(SFT)得到了模型s1-32B,然后应用预算强制技术。
-
s1-32B在竞赛数学问题(如AIME24)上的表现超过了OpenAI的o1-preview模型,最高可达27%;
-
s1-32B整体效果媲美DeepSeek-R1-distill(800K样本);
-
通过预算强制技术扩展s1-32B的测试时计算量,可以从50%的性能提升到57%;
-
s1-32B是最高效的开放数据推理模型
示例模型输出。从AIME24(左侧)、MATH500(中间)和GPQA(右侧)中各选取一个问题,其中s1-32B模型生成了正确答案。黑色文本是提示,浅蓝色文本是推理过程,蓝色文本是s1-32B模型的答案。灰色省略号[…]表示文本已被截断以适应此页面,但实际生成的文本更长。

https://arxiv.org/pdf/2501.19393s1: Simple test-time scalinghttps://github.com/simplescaling/s1
(文:PaperAgent)
测试时扩展:最高可达27%性能提升!预算强制技术让模型反思其已有答案,简直了。