

除了大语言模型,DeepSeek在其他方面做得也不错。
今天给大家推荐一个DeepSeek开源的多模态理解和生成模型。
就是既能理解,还能生成。
这个模型发布有段时间了,但是近期又更新了Janus-Pro,效果大幅提升。
项目简介
Janus-Pro是由DeepSeek-AI团队开发的多模态模型,提升多模态理解与生成能力。它通过优化训练策略、扩展训练数据和扩大模型规模,实现了显著的性能提升。Janus-Pro采用视觉编码解耦架构,分别处理多模态理解与视觉生成任务,解决了传统模型中任务冲突的问题。
功能特点
· 强大的多模态理解
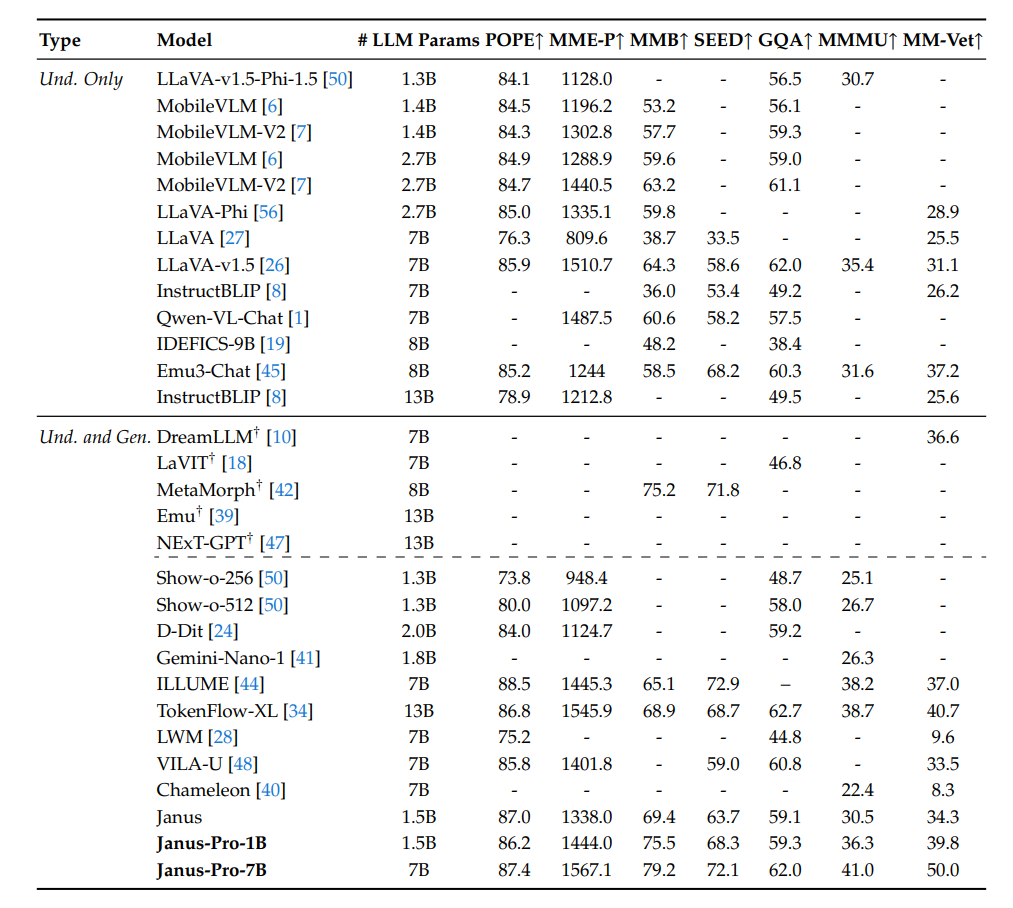
Janus-Pro在多个多模态理解基准测试中表现出色,能够准确地处理和理解图像与文本相结合的信息。例如在MMBench基准测试中,Janus-Pro-7B取得了79.2的高分,超越了众多现有的先进模型,在处理复杂视觉和语言任务时有非常强的能力。
(图片给大家翻译了,所以有的地方不太准确)
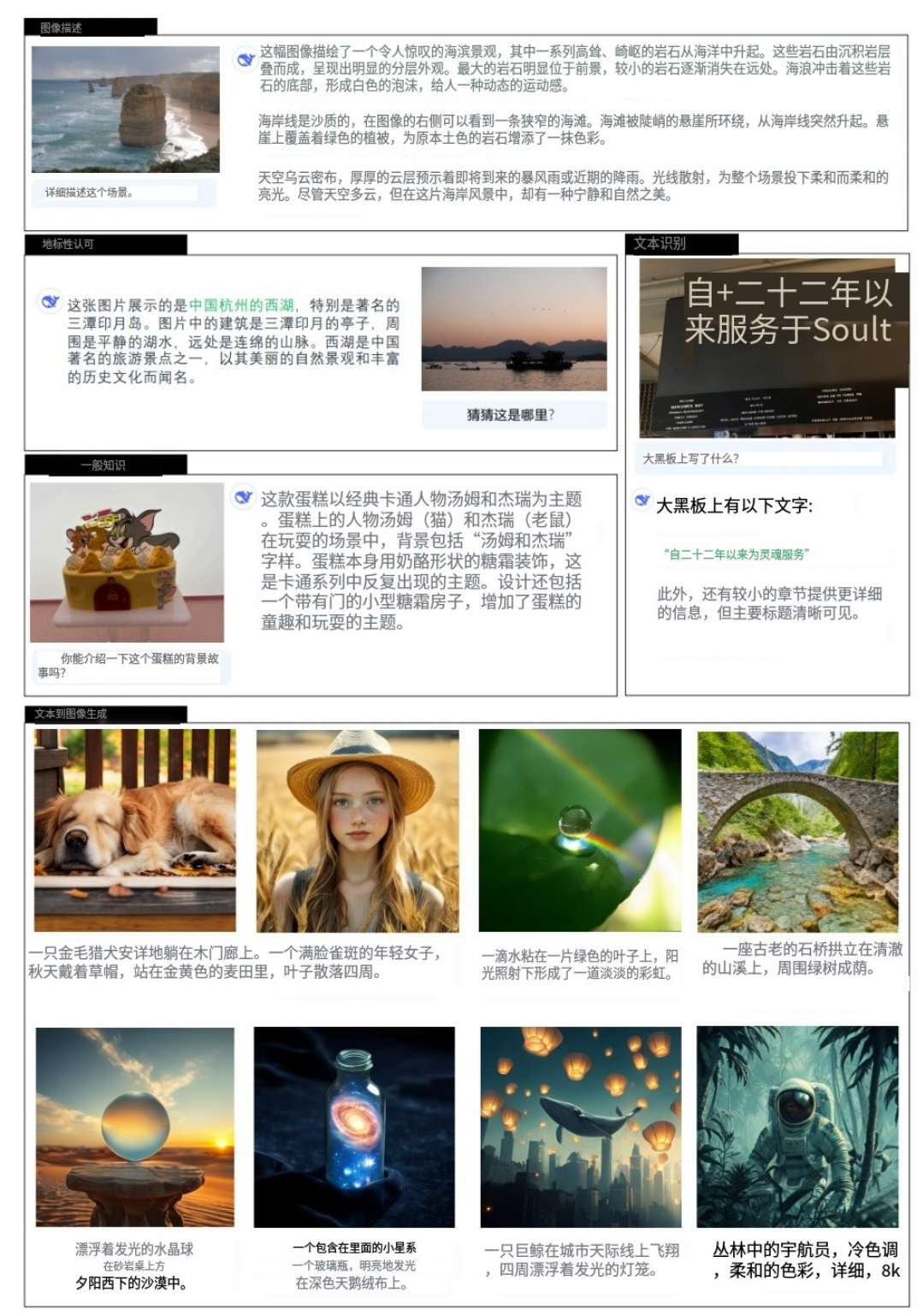
· 高质量的文本到图像生成
Janus-Pro具备出色的文本到图像生成能力,能够根据文本指令生成高质量、语义对齐的图像。在GenEval和DPG-Bench等基准测试中,Janus-Pro-7B分别取得了80%和84.19的高分,生成的图像不仅在语义上与文本高度一致,还具有较高的美学质量,细节丰富。
(Janus是先前版本,Janus-Pro是更新后的版本)

技术特点
1.视觉编码解耦技术

· 核心架构设计:Janus-Pro采用视觉编码解耦架构,将多模态理解任务和视觉生成任务的视觉编码器分开处理。这种设计解决了传统统一多模态模型中因共享视觉编码器而导致的性能冲突问题。
· 独立编码器:
- 多模态理解:使用SigLIP编码器提取图像的高维语义特征,这些特征被映射到语言模型的输入空间,用于理解图像内容。
- 视觉生成:使用VQ tokenizer将图像转换为离散ID,这些ID对应的嵌入被映射到语言模型的输入空间,用于生成图像。
· 优势:通过解耦,模型在多模态理解和视觉生成任务上都能达到更高的性能,同时避免了任务间的相互干扰。
2.自回归Transformer框架
· 统一处理:Janus-Pro基于自回归Transformer框架,能够将多模态特征序列统一处理,实现高效的多模态信息交互和协同处理。
· 随机初始化预测头:除了LLM内置的预测头外,还引入了一个随机初始化的预测头用于图像生成任务,进一步提升了生成图像的质量。
· 优势:自回归Transformer框架为模型提供了强大的基础支持,使其能够高效地处理复杂的多模态任务。
3.通过数据和模型缩放实现统一的多模态理解和生成
Janus-Pro是前作 Janus 的升级版。
Janus-Pro 结合了 (1) 优化的训练策略、(2) 扩展的训练数据和 (3) 扩展到更大的模型尺寸。
通过这些改进,Janus-Pro 在多模态理解和文本到图像的指令遵循能力方面都取得了显著的进步,同时也增强了文本到图像生成的稳定性。
项目链接
https://github.com/deepseek-ai/Janus
关注「开源AI项目落地」公众号
(文:开源AI项目落地)