
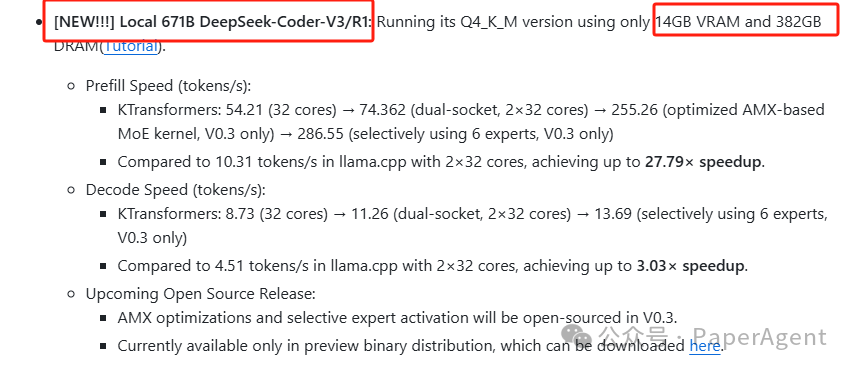
-
为什么使用CPU/GPU混合推理?DeepSeek的MLA操作符计算密集度很高。虽然完全在CPU上运行是可行的,但将繁重的计算任务卸载到GPU上可以带来巨大的性能提升。 -
性能提升来自哪里? -
专家卸载:与传统的基于层的或KVCache卸载(如llama.cpp中所见)不同,将专家计算卸载到CPU,而将MLA/KVCache卸载到GPU,这与DeepSeek的架构完美契合,实现了最佳效率。 -
英特尔AMX优化——AMX加速内核经过精心调优,运行速度比现有的llama.cpp实现快数倍。 -
为什么选择英特尔CPU?英特尔是目前唯一支持类似AMX指令的CPU厂商,与仅支持AVX的替代方案相比,它能提供显著更好的性能。

https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md
(文:PaperAgent)