

在一周前的《手把手教你本地部署DeepSeek-R1:3步搞定,有手就行!》一文里,我详细介绍了如何在本地部署 DeepSeek-R1 模型。
本地部署的优势在于灵活和数据隐私,但对硬件的要求实在太高,个人想要部署参数量为671B(6710亿)的满血版 DeepSeek-R1 模型几乎是不现实的。
附上7个不同参数量的 DeepSeek-R1 各自所需的配置。
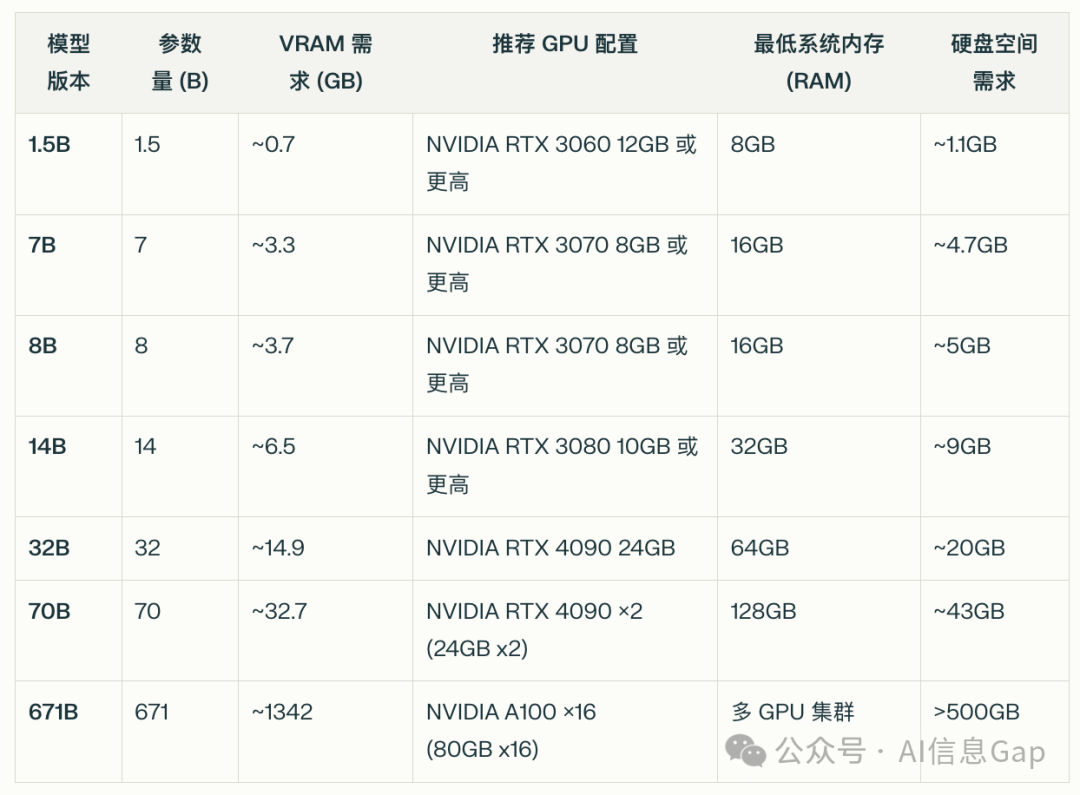
可以看到,现阶段最强的面向个人用户的消费级显卡 NVIDIA GeForce RTX 4090(不算刚刚发布的5090的话),只能跑得动参数量为32B的 DeepSeek-R1。实在有点不够看。
那么问题来了,能不能用最小的成本办最大的事?比如在 RTX 4090 上跑满血版 DeepSeek-R1?
还真可以。最近,清华大学MADSys团队联合 趋境科技(Approaching.AI) 给出了KTransformers这个全新的开源解决方案。不需要A100/H100多卡集群,单张RTX 4090也能跑满血版 DeepSeek-R1。
KTransformers 是什么
KTransformers是一个基于 Hugging Face Transformers 的高性能LLM推理优化框架,其核心技术是“注入(Injection)机制”。这一机制允许用户通过YAML配置文件,自动将PyTorch计算图中的标准算子替换为更高效的优化内核,如Llamafile、Marlin和即将开源的AMX,从而 降低显存占用、提升推理速度,即便在有限的本地环境下也能运行大规模LLM。
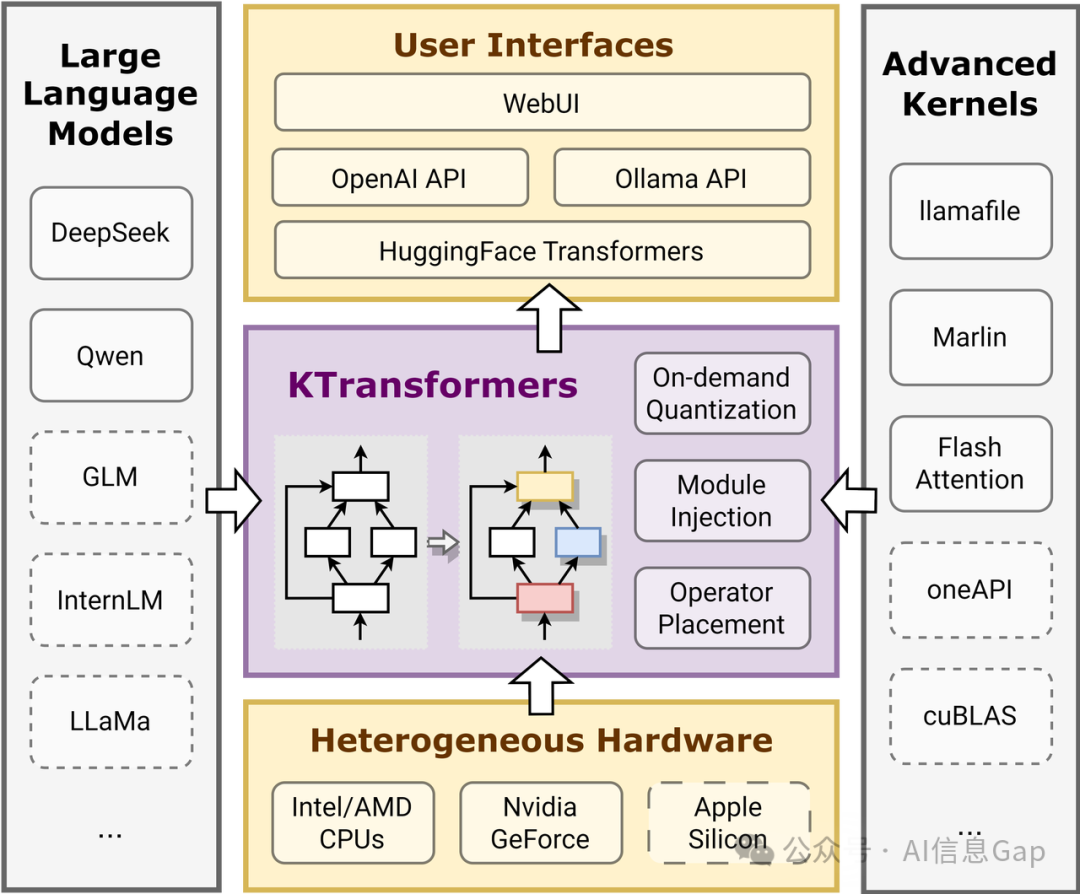
KTransformers的关键特点包括:
-
支持DeepSeek-R1、DeepSeek-V2/V3、Qwen2-57B、Mixtral 8x7B/22B等SOTA大模型 -
兼容OpenAI API,可作为VSCode Copilot、Tabby等AI助手的后端 -
支持自动量化(Q4_K_M)、MoE(专家模型)优化,极限压缩显存占用 -
Prefill+Decode双阶段优化,相比llama.cpp最高提升27.79×的推理速度 -
RESTful API & Web UI交互,支持本地部署和云端推理
根据该项目文档2月10日的更新,KTransformers团队成功在资源受限的本地环境(24GB VRAM,382GB DRAM)下运行了DeepSeek-R1/V3的Q4_K_M量化版本,并通过AMX优化和选择性专家激活策略,使推理速度相比llama.cpp,Prefill最高提升27.79倍,Decode提升3.03倍。

接下来附上详细的操作步骤。
KTransformers项目地址:https://github.com/kvcache-ai/ktransformers
本地部署满血版DeepSeek模型文档:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md
环境配置
硬件要求
-
GPU: NVIDIA RTX 4090(24GB VRAM) -
CPU: Intel Xeon Gold 6454S或同级别CPU -
内存: 推荐382GB DRAM
软件环境
| V0.3-Preview 版本 | V0.2/V0.2.1 版本 | |
|---|---|---|
| 操作系统 | Ubuntu 20.04/22.04 | Ubuntu 20.04/22.04 |
| CUDA 版本 | 12.6 | 12.x(建议参考官方文档) |
| Python 版本 | 3.11(推荐) | 3.10 及以上 |
| PyTorch 版本 | 2.6 | 2.1 及以上 |
| KTransformers | 0.3.0rc0 | 最新稳定版 |
安装 KTransformers
1. 安装系统依赖
sudo apt update && sudo apt install -y build-essential git wget curl
2. 安装 Python 及 Pip
V0.3版本推荐Python 3.11。
sudo apt install -y python3.11 python3.11-pip python3.11-venv
python3.11 -m venv venv
source venv/bin/activate
V0.2/V0.2.1版本支持Python 3.10及以上。
sudo apt install -y python3 python3-pip python3-venv
python3 -m venv venv
source venv/bin/activate
3. 安装 CUDA 及 PyTorch
V0.3-Preview(CUDA 12.6 + PyTorch 2.6)
pip install torch==2.6.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
V0.2/V0.2.1(根据CUDA版本安装PyTorch)
# 如果使用 CUDA 12.x
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12x
# 如果使用 CUDA 11.x(如 11.8)
pip install torch==2.1.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
4. 安装 KTransformers
最佳性能,V0.3-Preview推荐
wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.3/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
最新稳定版,V0.2/V0.2.1
pip install ktransformers
适合开发者,源码安装
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
sh ./install.sh # 或 make dev_install
5. 下载 DeepSeek-R1/V3
# 使用 --depth 1 参数,只克隆最新版本,减少下载量
git clone --depth 1 https://huggingface.co/deepseek-ai/DeepSeek-R1
git clone --depth 1 https://huggingface.co/deepseek-ai/DeepSeek-V3
或者,也可以从Hugging Face直接下载GGUF量化版本。
# 以DeepSeek-V3的Q4_K_M量化版本为例
wget https://huggingface.co/deepseek-ai/DeepSeek-V3-GGUF/resolve/main/deepseek-v3-q4_k_m.gguf
运行 DeepSeek-R1/V3
1. 4090单GPU运行
python -m ktransformers.local_chat \
--model_path <模型路径或 Hugging Face Hub ID> \
--gguf_path <GGUF 文件路径或 Hugging Face Hub 文件名> \
--prompt_file <提示文件路径(可选)> \
--cpu_infer 33 \
--max_new_tokens 1000
参数解析
-
--cpu_infer 33:使用33线程进行推理(可根据CPU调整) -
--max_new_tokens 1000:最大生成Token数
2. 多GPU运行
python -m ktransformers.local_chat \
--model_path <模型路径或 Hugging Face Hub ID> \
--gguf_path <GGUF 文件路径或 Hugging Face Hub 文件名> \
--prompt_file <提示文件路径(可选)> \
--cpu_infer 65 \
--multi_gpu true \
--max_new_tokens 1000
适用于多张4090或A100服务器环境。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)