

今天是2025年02月18日,星期二,北京,天气晴。
最近关于ktransformers的报道工作很多,也让人产生了许多误区,社区觉得有必要来谈谈这个话题,当然,跟大家强调一下,我们务必要去看一手消息,一手信息源,从官方的readme去看,细节总是在原文档。
我们来看看一些基本的认知,供大家一起参考。
专题化,体系化,会有更多深度思考。大家一起加油。
一、Ktransformer是什么、如何做的推理,以及风险误区
关于Ktransformer,正如其官方readme所说,特别关注异构计算的机会,例如量化模型的GPU/CPU卸载。,所有就是本地CPU/GPU混合推理,问了下专门做推理的同事,比较有专业,对于ktransformer的一些判断。核心就是将moe几十个专家里面的密集计算部分从gpu转移到cpu,从而降低显卡需求。
其一,为什么要使用CPU/GPU混合推理? DeepSeek的MLA运算符计算量非常大。虽然可以在CPU上运行所有内容,但将繁重的计算转移到GPU可以大幅提高性能。
其次,加速从何而来? 主要是两个两个部分,一个是专家卸载,与传统的基于层或KVCache卸载(如llama.cpp中所示)不同,将专家计算卸载到CPU,将MLA/KVCache卸载到GPU,与DeepSeek的架构完美契合,以实现最佳效率;一个是IntelAMX优化,AMX加速内核经过精心有哈,运行速度比现有llama.cpp实现快几倍,并计划在清理后开源此内核,并正在考虑向llama.cpp上游贡献。
其二,为什么选择英特尔CPU? 英特尔目前是唯一一家支持AMX类指令的CPU供应商,与仅支持AVX的替代方案相比,其性能明显更佳。
当然,有几个风险和误区,大家可以认识下。
1)目前和nivida相比,这个token速度还是太慢,3-5token/s或者再增加几倍,不具备优势,这种速度在用在对话类场景,基本不可用;
2)这样需要一个很大的内存卡机器专门存储,只是介质成本下去了。而不是单张gpu就够了,只是降低了GPU的使用而已。如果做不到多卡内存分开加载部署,这个事情也鸡肋,但导致其他卡空闲;
3)目前跑的是int4版本,其全精度版本有性能差异,当然,671B的量化,我们测试下来,虽然鱼72B、32B这些有10-20% 的损耗相比好一些,但还是需要更多场景做验证。
4)目前从体验上看,只能是说,可以在单张4090能跑,但也需要有很大的内存,顶多是玩一玩的小白用户,注意,这个不是个人用户,还得是企业用户,不是你买个游戏本就能跑,你得有大内存。能不能上生产,还得看。能用在离线场景做数据蒸馏用,比如,我现在就是想蒸馏R1的数据,就放在那让它自己慢慢蒸就行,对话场景基本很难用起来,客户会受不太了。
所以,还有很多事情需要解决,
其一,如何支持多卡推理?目前只能做单卡gpu推理。有多张显卡也在那干等着,有点浪费。
其二,其内部还是做了一些量化的工作,这部分的损失是否真的可忽略不计?
其三,性能提升有限的原因主要在于推理过程仍然受到CPU计算速度和内存带宽的制约。GPU处理的MLA部分占比较小。这块其实挺鸡肋的。项目也想过利用 Xeon Gold CPU上的两个 NUMA节点。为了避免节点间数据传输的成本,我们在两个节点上“复制”关键矩阵,这会消耗更多内存,但会加速预填充和解码过程。但这种方法占用大量内存,加载权重时速度很慢。
其四,DeepSeek-R1采用了混合专家模型(MoE)架构,其每个MoE层由1个共享专家和256个路由专家组成。在实际运行中,每个token会激活8个专家。其实现版本中有的只激活6个的专家,这个后期是否有优化空间?是否真的奏效,能否把性能损失控制到最小?
其五,未来的一些优化方向,包括对国产的适配和进一步加速。也正如其在官方文档中所述,https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md,FlashInfer(https://github.com/flashinfer-ai/flashinfer)项目正在发布更高效的融合MLA运算符,有望进一步提高速度;vLLM已在DeepSeek-V3中探索了多标记预测,并且我们的路线图正在提供支持,以实现更好的性能,并且正在与英特尔合作增强AMX内核(v0.3)并针对Xeon6/MRDIMM进行优化。另外,支持更多量化类型,包括unsloth高度要求的动态量化。
进而给出一个建议:可以观察下,目前有哪些公司会用这种方案,具体场景,子弹飞一会儿。
二、Ktransformer的一些表现和用户问题
当然,我们可以从其readme和issue出发,来看实际的一些情况。
1、看其发表时间线及速度
2024年8月28日,将DeepseekV2所需的显存从21GB降低到11GB。
2024年8月28日,支持在InternLM2.5-7B-Chat-1M模型下处理100万上下文,使用24GB显存和150GB内存。详细教程在此处;
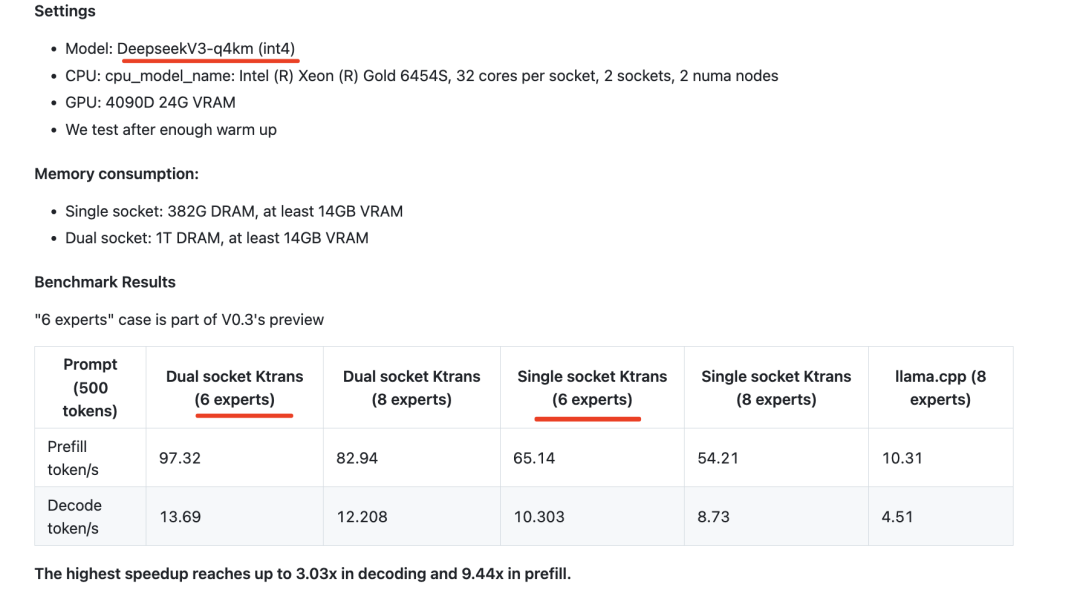
2025年2月10日,支持DeepseekR1和V3在单个(24GB显存)/多GPU和382GB内存上的运行,速度提升可达3至28倍。其中,本地671BDeepSeek-Coder-V3/R1,可以仅使用14GB显存(VRAM)和382GB内存(DRAM)运行其Q4_K_M版本,大家请注意VRAM和DRAM的区别,也注意,跑的是r1的q4量化版本,不是bf16原始版本。

当然,为了能够运行的更为流畅,可以再留大一些空闲,例如如下,使用的环境是4090D-24G的显卡资源,以及1T DRAM的内存资源,达到如下的的速度效果,注意,是跟llama.cpp 相比:

看几个详细指标:
1)预填充速度,prefillspeed指在模型推理过程中,从输入整个prompt到生成第一个token所需的时间,通常以tokens per second(每秒处理的token数)为单位。这个阶段的主要任务是计算整个输入序列的特征表示,并生成第一个输出token,同时缓存所有的KVCache以加速后续的解码过程。
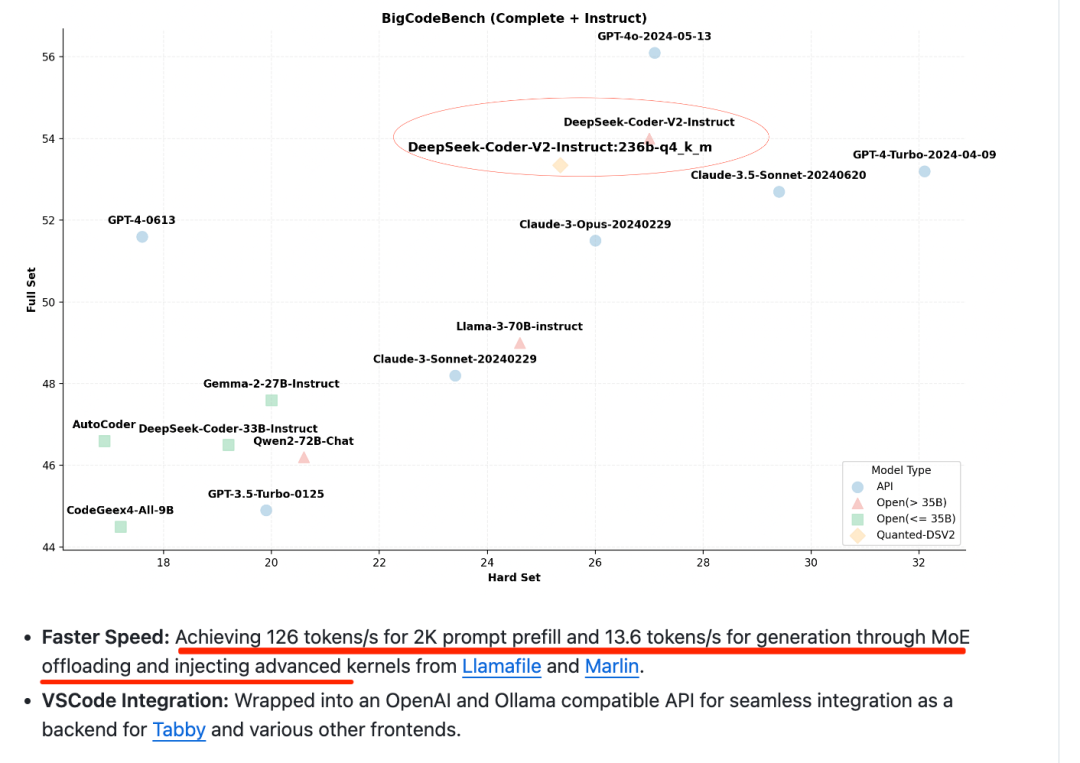
KTransformers的表现,54.21(32核)→74.362(双插槽,2×32核)→255.26(优化的基于AMX的MoE内核,仅限V0.3)→286.55(选择性使用6个专家,仅限V0.3),与使用2×32核心l的llama.cpp相比,达到最高27.79倍的速度提升。
2)解码速度(每秒token数),KTransformers的表现:8.73(32核)→11.26(双插槽,2×32核)→13.69(选择性使用6个专家,仅限V0.3),与使用2×32核的llama.cpp相比,达到最高3.03倍的速度提升。
2、看其实现框架
KTransformers的性能优化基本囊括了目前主流的优化手段,包括:
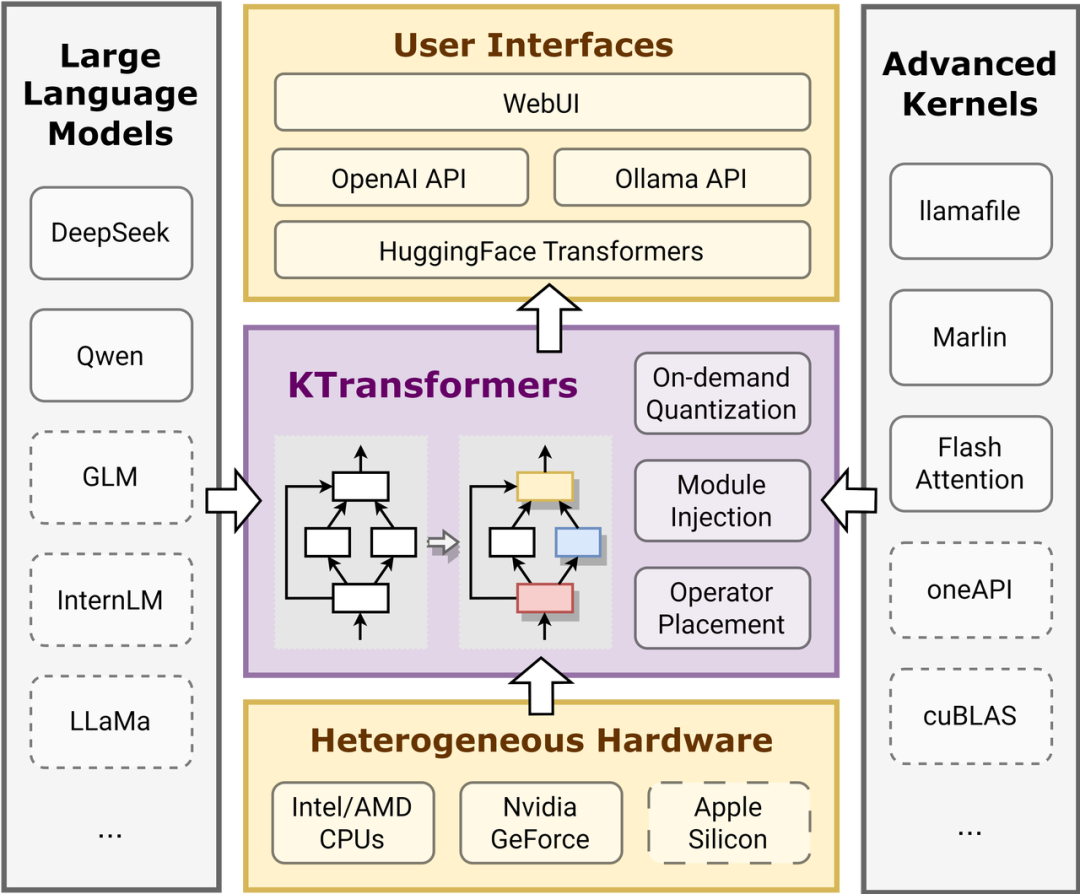
几个点。
一个是内核优化:通过注入优化的内核(如Llamafile和Marlin),替换PyTorch原生模块,从而提高计算效率。这些内核针对特定硬件和数据类型进行了深度优化。
一个是量化,将模型权重从高精度浮点数转换为低精度整数,减少模型大小和计算量,同时保持模型性能。
一个是CPU/GPU卸载,将计算任务在CPU和GPU之间分配,充分利用不同硬件的优势。
一个是注入框架,允许用户通过YAML配置文件定义优化规则,将指定模块替换为优化版本。
3、用户使用过程中提到的几个有趣的问题,
来自https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/FAQ.md。
当然,也可一去看issue:https://github.com/kvcache-ai/ktransformers/issues
1)DeepSeek-R1未输出初始token?
观察到DeepSeek-R1系列模型在响应某些查询时倾向于绕过思维模式(即输出“<think>\n\n</think>”),这可能会对模型的性能产生不利影响。为了确保模型进行彻底的推理,我们建议强制模型在每个输出的开头都以“<think>\n”作为响应。
因此,通过在提示符末尾手动添加“<think>\n”标记来解决这个问题(你可以在local_chat.py中查看),并传递参数–force_thinktrue可以让local_chat使用“<think>\n”启动响应
2)如果没有足够的VRAM,但我有多个GPU,该如何利用它们?
可以使用加载–optimize_rule_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu.yaml两个优化规则yaml文件,也可以以此为示例编写4/8gpu优化规则yaml文件。

但是务必注意:
ktransformers的多GPU策略为pipline,无法加速模型的推理,仅用于模型的权重分配。
所以,issue(https://github.com/kvcache-ai/ktransformers/issues/397)中提到的,GPU/CPU混合推理deepseekR1使用了多GPU,但推理性能和单GPU一致,没有提升,多卡并不会加速推理,直接改变权重分配。
也有issue(https://github.com/kvcache-ai/ktransformers/issues/345)中提到,为啥用8卡4090跑的,速度还没有单卡的快呢? 修改了但是推理优化的配置,实现了8卡来跑,实际测试下来,速度和用单卡跑的差不多,我用的是256G的内存,是自己2位量化的版本。
这个原因可能是因为计算阈值在cpu上。而且8卡阈值只会增加通信开销,4090跨越nvlink。
3)如何获得最佳性能?
必须设置–cpu_infer为要使用的核数。使用的核越多,模型运行速度越快,但并非越多越好。将其调整得略低一些,以适应实际核数。例如,–cpu_infer 65指定使用多少个核,超过物理数量是可以的,但也不是越多越好,稍微调低到实际的核心数量。
4)如果我获得的VRAM(也就是显存)比模型要求的多,我该如何充分利用它?*
一个是加大上下文,不用白不用,也能利用长上下文的能力,例如–max_new_tokenslocal_chat.py可以以通过设置更大的值来增加上下文窗口的大小。服务器部分将“–cache_lens”增加到更大的值。将更多权重移至GPU,参阅ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-multi-gpu-4.yaml
也可以根据需要修改层,

例如name:"^model\\.layers\\.([4-10])\\.mlp\\.experts$"将name:"^model\\.layers\\.([4-12])\\.mlp\\.experts$"更多权重移动到GPU。
里面提到几个注意点。目前,在GPU上执行专家将与CUDAGraph冲突。如果没有CUDAGraph,速度会明显变慢。因此,除非有大量VRAM (在GPU上放置DeepSeek-V3/R1的单层专家至少需要5.6GB的VRAM),否则不建议启用此功能。我们正在积极进行优化,且注意KExpertsTorch未经测试。
5)请问DeepseekR1-q4km在哪里下载,1.58位量化版本在哪里找?
https://huggingface.co/unsloth/DeepSeek-R1-GGUF 或https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF,
6)不带gpu可以运行ktransformers吗?ktransformers能否仅使用CPU和DRAM运行(无需GPU/VRAM)?
这个问题来自issue(https://github.com/kvcache-ai/ktransformers/issues/337),对应的回复是,
编译过程需要CUDA,生成的二进制文件对flash注意模块有硬性要求,而该模块需要CUDA环境才能编译。理论上,即使没有GPU,也可以通过安装CUDA工具包及相关依赖项来编译flash注意并发出运行,但可能性似乎不大。可能可以通过安装CUDA工具包和依赖项(无需GPU)来编译flash注意力并使其运行,但似乎不太可能。
所以,在没有GPU的测试机上安装所有CUDA依赖项以构建闪存注意力相当困难。至少对于DeepSeek-R1而言,ktransformers在运行时至少需要一块具有约16GB显存的CUDA设备作为硬性要求。若需纯CPU运行方案,建议用户暂时继续使用llama.cpp,kt目前只支持CPU+GPU。
三、如何部署ktransformers?
在部署方面,可以看地址:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md
DeepSeek-R1采用了混合专家模型(MoE)架构,其每个MoE层由1个共享专家和256个路由专家组成。在实际运行中,每个token会激活8个专家。

但是,ktransformers根据领域外数据的离线档案结果选择较少专家的专家选择策略,其发现在推理中稍微减少激活专家的数量时,输出质量不会改变。但解码和预填充的速度加快了。
具体执行代码如下:
`wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
python -m ktransformers.local_chat –model_path
<when you see chat, then press enter to load the text prompt_file>
`
可以看到,会有两个模型加载,一个是model_path,一个是gguf path。这其实相当于多出了一份存储消耗?【不知是否理解对】。例如,ktransformers --model_path deepseek-ai/DeepSeek-V2-Lite-Chat --gguf_path /path/to/DeepSeek-V2-Lite-Chat-GGUF --port 10002
这里我们做下解读。这说明model_path指向的是原始的模型路径,而gguf_path指向的是量化后的GGUF格式模型文件。
为什么要这么做?通过算术密度指导的卸载策略,将高计算密度的模块(如MLA)保留在GPU,而低密度模块(如MoE专家)卸载到CPU。这种混合加载需要同时访问原始模型结构(model_path)和量化权重(gguf_path)。也就是说, KTransformers的优化策略,包括将部分参数卸载到CPU并使用GGUF格式的量化权重,而GPU部分则使用Marlin内核处理。因此,model_path可能用于加载模型的结构和部分参数,而gguf_path提供量化后的权重,用于CPU端的计算。
所以,KTransformers部署时需要同时指定model_path和gguf_path,
model_path路径指向原始的PyTorch模型(如HuggingFace格式),用于加载模型结构和部分未量化的参数。例如,模型中的稠密计算模块(如MLA注意力层)会保留在GPU上,利用Marlin内核加速计算。
gguf_path指向GGUF格式的量化权重文件,用于加载CPU端的稀疏计算模块(如MoE专家层、词嵌入层)。GGUF格式通过4bit/8bit量化大幅降低内存占用,并直接调用Llamafile内核在CPU上高效执行
参考文献
1、https://github.com/kvcache-ai/ktransformers
(文:老刘说NLP)