


©PaperWeekly 原创 · 作者 | 尹怀鸿
单位 | 南京大学硕士研究生
研究方向 | 表格数据,多模态学习
近年来,深度学习在图像、语音、自然语言处理等领域大放异彩,但在一个看似简单却至关重要的场景——表格数据预测任务中,深度学习的能力却难以预约如梯度提升决策树(GBDT)等经典机器学习方法。
表格数据预测即最经典的机器学习任务,数据以行列结构组织,给定样本的向量表示,需要对其标记进行预测,在医疗记录、金融风控、电商推荐等行业中,表格数据仍作为核心。
随着深度学习在相关领域中的应用,研究者们也尝试思考,是否深度神经网络的能力能拓展至表格预测领域。近年来,有大量工作,从数据处理技巧、网络结构设计、大语言模型融入等多个方面进行了尝试,但深度神经网络的效果依然有限,或仅能在部分领域的数据上相比于树模型取得突破。
梯度提升树的出色的性能给予研究者启发:也许基于传统方法进行改进,能够让深度方法在传统方法上锦上添花,在表格数据上实现能力跨越。
在这一思路的指引下,南京大学团队从一个经典的可微 K 近邻算法——近邻成分分析(Neighbourhood Component Analysis,NCA)出发,通过不断加入深度学习的技术,提出 ModernNCA 方法,用便捷的形式取得深度学习模型在表格数据分类、回归任务上的性能突破,在 300 个数据集上展现出优越于其他深度方法的性能。

论文链接:
工具包链接:
ModernNCA代码链接:

回顾近邻成分分析
K 近邻算法(K-Nearest Neighbor,KNN)是一种简单而直观的非参数方法,广泛应用于分类和回归任务。KNN 的核心思想是通过度量样本之间的距离,从训练数据中寻找与给定样本最相似的 K 个邻居,并基于这些邻居的信息来预测目标值。
然而,KNN 的一个问题在于其基于原始特征空间进行距离度量,在高维数据中容易受到“维度灾难”的影响,导致性能下降。
为了解决这个问题,Jacob Goldberger 等人在 2004 年提出了近邻成分分析(NCA)[1],NCA 通过学习一个映射矩阵,使得在新的特征空间中,同一类的样本彼此靠近,而不同类的样本则远离,从而增强 KNN 算法的分类效果。
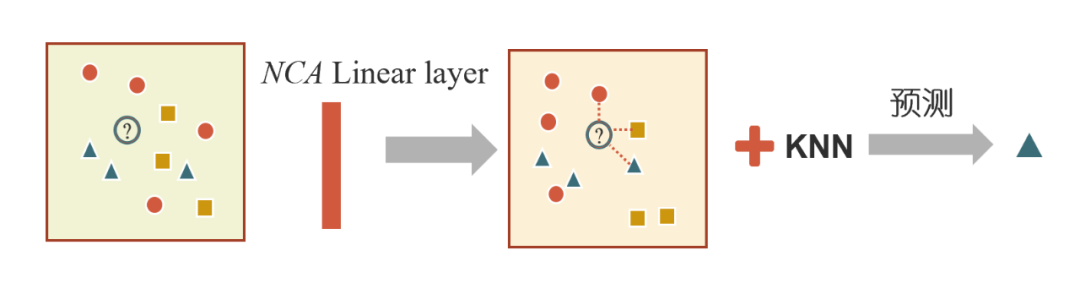
▲ 图1:NCA 进行表格预测思路
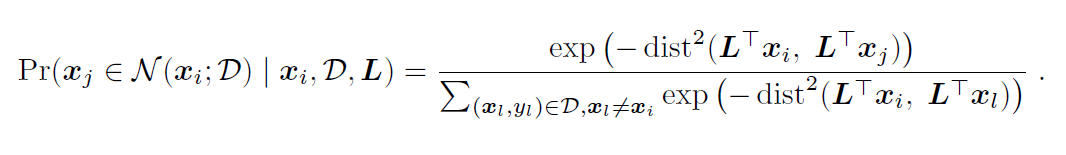
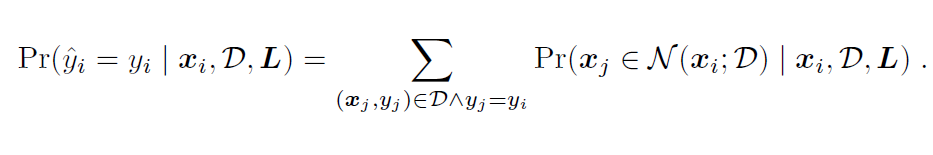
然而,尽管 NCA 提出于二十年前,并且提出的时候论文就将其应用于 iris 等表格数据分类任务,但由于 NCA 的预测能力远远不及 RandomForest、XGBoost 等机器学习方法,后续 NCA 在研究者视野中逐渐淡去,在 sklearn 工具包中也仅作为一种可视化降维方法出现。
本文重新分析并发现 NCA 的潜力,通过深度学习技术,对 NCA 进行一系列改进,学习面向表格数据高质量的特征表示,不仅能让其性能大幅增强,而且相较于其他表格深度学习方法,在时间,性能,内存消耗上有着更优秀的平衡。

改进步骤 1
原始 NCA 使用线性投影,且局限于分类场景。我们对预测公式进行修改,假设 在分类任务中是 one hot 形式,在回归任务中是数值的形式,对于样本预测的标签值为:
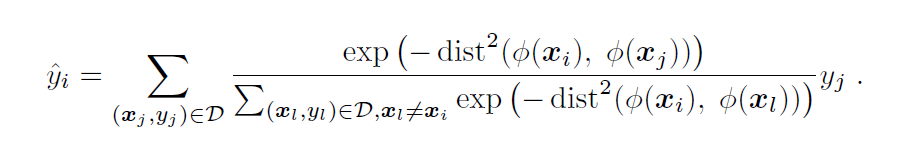
——公式(1)
我们发现使用了这些改进后,NCA 在预测性能上有了显著的提升,即便只有一个线性映射层,其预测性能也能比肩 MLP。我们把这一改进后的 NCA 版本称为 L-NCA。

改进步骤 2
尽管线性版本的 L-NCA 已展现出潜力,但其表达能力仍受限于线性映射。为了充分释放深度学习的优势,研究者进一步引入现代深度学习技术,提出了ModernNCA(M-NCA),核心改进主要包含以下两点:
3.1 深度非线性架构
原始的 L-NCA 仅通过线性映射提取特征,而 M-NCA 将线性投影 替换为多层非线性模块。具体地,每个模块由批归一化(batch normalization)、线性层、ReLU 激活、Dropout 和另一个线性层构成,数学形式为:
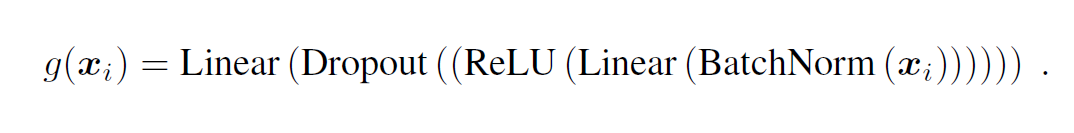
通过叠加多个此类模块,模型能够捕捉复杂的特征交互。此外,对于数值型特征,M-NCA 引入了 PLR(Periodic-Linear-ReLU)编码,将数值映射到高维空间,增强非线性表达能力。
传统 NCA 需计算目标样本与全部训练数据的距离,当训练集样本量很大(比如上百万)时候,计算开销巨大。为此,M-NCA 提出随机近邻采样(Stochastic Neighborhood Sampling, SNS)策略进行训练:
在训练阶段,M-NCA 每个批次仅随机采样部分训练数据(比如 30%)作为邻域候选,以降低计算量和显存消耗。在推理阶段,M-NCA 仍使用全体训练数据搜索近邻,保证预测精度。通过实验发现,SNS 不仅能显著加速训练,还能提升模型的泛化性能。

实验结果
研究团队在包含 300 个表格数据集(180 个分类数据集和 120 个回归数据集)的大规模基准测试中验证了 ModernNCA 的性能 [2]。
图 2 展示了不同表格数据方法的平均排名以及两两 Wilcoxon-Holm 检验的结果,实验结果显示,ModernNCA 在分类任务的平均准确率与回归任务的 RMSE(均方根误差)上均显著优于现有深度模型,并与当前最优的树模型 CatBoost 性能相当。

▲ 图2:表格数据方法平均排名的临界图
图 3 对图 2 中的方法的性能,运行时间和显存消耗进行比较,纵轴比较了不同方法的训练时间,横轴比较了不同方法的平均排名,圆圈的半径表示训练是消耗的显存。从图中可见,相较于其他的深度方法,ModernNCA 具备优秀的性能同时保持了合理的显存占用和高效的训练时间。
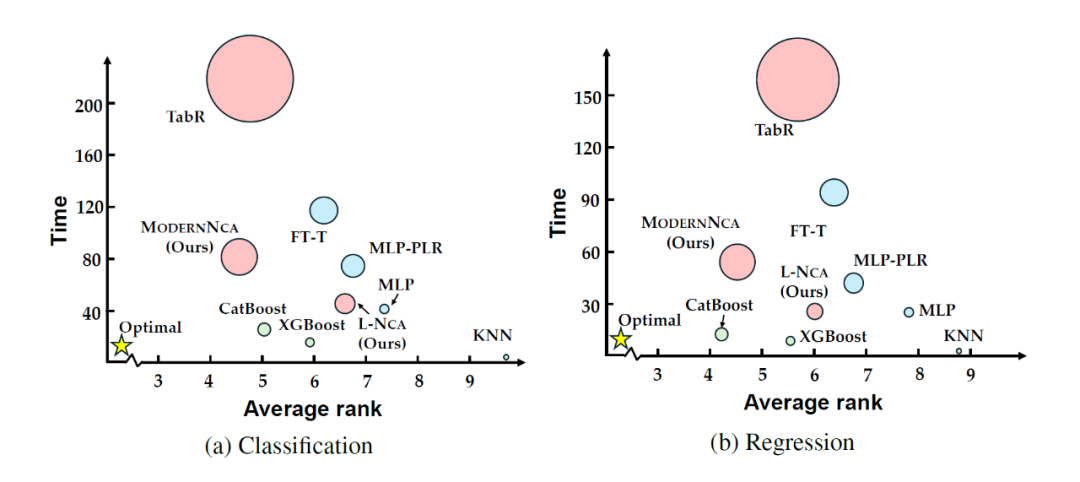
▲ 图3:表格数据方法性能、运行时间和显存消耗对比
4.2 消融实验
在 27 个分类数据集和 18 个回归数据集上,我们对改进的各个组件的有效性进行评估:
从表 1 可以看出,从原始的 NCA(表示为 NCAv0)中不断进行:不限制维度提升,优化器改进为 SGD,使用负对数似然损失,Soft 的近邻预测方式等改进,NCA 的平均排名持续下降,性能不断提升,即便只有一层线性映射,已经超过 MLP 的性能。

▲ 表1:NCA 加入不同改进组件后的平均排名
从表 2 可以看出,允许学习更深层的映射后,ModernNCA 具有更低的排名;此外,用带 batch normalization 的 MLP 学习 要好于其他的学习方式。

▲ 表2:映射层 不同结构的平均排名
从图 4 可以看出,ModernNCA 采用了随机近邻采样策略后,在 30-50% 的采样率产生了好于全量样本作为近邻训练的结果。

▲ 图4:不同采样比例的平均排名
4.3 可视化结果
以 AD 数据集为例,我们使用 TSNE 对不同方法学习的表征进行对比,如图 5 所示。
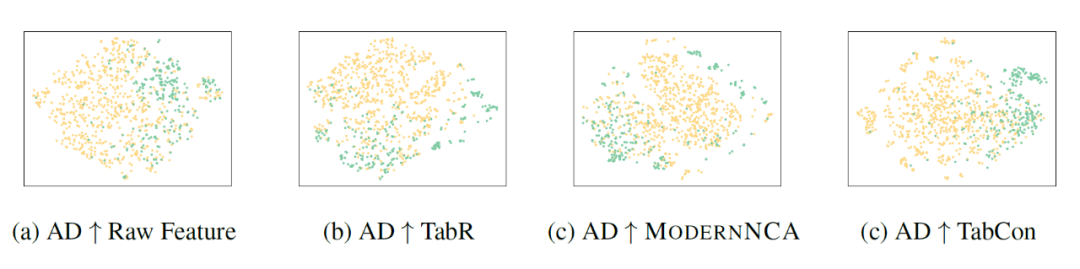
▲ 图5:学习表征可视化结果
可以看出,相较于原始特征,不同方法都学到了更加易于预测的特征空间。使用对比学习的方法(TabCon)使得同类的样本聚集成一个簇,难以处理难分样本。而 ModernNCA 会将同类的样本聚类成多个簇,保证相似的样本位置相近。ModernNCA 的机制能更好地学习样本间的局部关系,适应表格数据的特性。

总结
ModernNCA 通过融合经典近邻思想与深度学习技术,成功让二十年前的 NCA 算法焕发新生。其在 300 个数据集上的实验表明:ModernNCA 可以作为深度表格预测的一个强大的基线方法,相较于梯度提升树和其他深度表格方法展现出了强劲的性能。这一方法也启示研究者:对传统方法的现代化改造,可能是解锁深度学习潜力的关键钥匙。

(文:PaperWeekly)