

今天是2025年02月21日,星期五,北京,天气阴。
我们今天来看两个点,一个是关于大模型部署中几个点,框架、格式以及精度;另一个是prompt压缩策略用于COT推理微调的尝试,虽然不具有实用性,单纯是个发文的方向。
我们来看看一些基本的认知,供大家一起参考。
专题化,体系化,会有更多深度思考。大家一起加油。
一、大模型部署的几个框架要点
这些基本存储方面的知识,大家了解下也蛮好的。
1、关于大模型权重的存储格式
再普及下,大模型权重的存储格式多种多样,每种格式都有其独特的特点和适用场景。以下是一些常见的大模型权重存储格式:
1)PyTorch格式,pth, .pt, .bin:这是PyTorch框架的原生格式,广泛使用但安全性相对较低。
2)Safetensors格式,.safetensors:由Hugging Face开发,安全性更高,加载速度更快,支持内存映射,是目前推荐的格式。
3)GGUF格式,.gguf:由Georgi Gerganov定义的一种大模型文件格式,旨在快速加载和保存模型,适用于CPU推理。
4)ONNX格式,.onnx:开放神经网络交换格式,旨在实现不同深度学习框架之间的互操作性。
5)TensorFlow格式,.h5, .pb, .ckpt:TensorFlow使用的格式,包括HDF5格式、Protocol Buffers格式和Checkpoint文件。
6)量化格式,.gguf (llama.cpp使用), .ggml (旧版GGML), model-q4_0.bin (4-bit量化), model-q8_0.bin (8-bit量化):量化格式通过降低权重和激活值的精度来减小模型大小和内存占用,但可能略微降低精度。
7)分片格式, pytorch_model-00001-of-00003.bin:用于存储超大型模型,将权重文件分割成多个部分。
2、关于大模型精度
FP32(单精度浮点数)、FP16(半精度浮点数)、BF16(Brain Float 16)、INT8(8位整数)、低比特量化(如2-bit、4-bit)以及混合精度量化等多个类型。
量化通过将模型参数从高精度(如FP32)转换为低精度(如INT8、INT4),减少了计算和存储开销,从而提升模型的推理速度。例如,INT8量化通常可以在保持较高精度的同时,使推理速度提高数倍。
但是量化会带来很多问题,
量化过程中,从浮点到定点的转换可能会导致模型精度的下降,尤其是在量化到较低比特数时。例如,使用8位或更低精度的量化时,模型的预测性能可能会受到影响,尤其是在处理高维度输入数据时。
量化会显著降低大模型在基本数学任务上的表现。足够的模型精度是大模型解决基本数学任务的重要前提,而量化会大大降低大模型在多整数相加、整数相乘等任务上的能力,甚至提升模型参数量也无法弥补。
动态量化在推理时动态地进行量化,避免了静态量化中的信息损失,但可能会牺牲一些推理速度。
静态量化通过校准和量化两个步骤,通常可以获得更高的精度,但需要更多的计算资源。所以,混合精度量化结合了全精度训练和量化训练的优点,它在训练中采用不同的精度级别,如权重可能采用低精度存储,而梯度和偏差仍然保持高精度。
当然,大模型的量化精度选择应根据具体应用场景和硬件支持情况进行权衡。FP32、FP16和BF16适用于需要高精度计算的场景,而INT8和低比特量化则更适合资源受限的设备。
3、关于部署的一些框架
关于部署框架侧,目前有很多,VLLM、llama.cpp、sGLang、KTransformers和MLX。
1)VLLM(https://github.com/vllm-project/vllm),基于PagedAttention 的显存分页管理技术,支持动态批处理(Continuous Batching)和多GPU张量并行。量化支持FP8/INT4/AWQ/GPTQ,兼容多模态模型(如Qwen-VL)。
2)llama.cpp(https://github.com/ggerganov/llama.cpp),纯C++实现,支持 K-quant量化(2-8bit),优化CPU/ARM架构推理。硬件支持CPU/ARM/部分GPU(CUDA后端),跨平台(树莓派、Mac)。量化支持2-8bit量化,GGUF格式模型压缩。适用场本地开发、边缘计算、低资源环境。
3)sGLang(https://github.com/sgl-project/sglang)通过RadixAttention实现KV缓存复用,依赖后端引擎(如VLLM或NVIDIA Triton),支持多GPU集群。
4)KTransformers(https://github.com/kvcache-ai/ktransformers)基于异构计算(CPU+GPU协同)、专家卸载策略、Intel AMX优化,支持 671B参数模型 在24GB显存运行。
5)MLX(https://github.com/ml-explore/mlx)为苹果统一内存架构,CPU/GPU零拷贝传输,原生支持M系列芯片,适用于Mac本地开发、隐私敏感场景、轻量级调试。
在选型建议方面,对于企业级服务:VLLM(高吞吐)或 sGLang(结构化生成)。长文本推理优先 VLLM(PagedAttention显存优化)。
二、prompt压缩策略用于COT推理微调
推理压缩,跟之前的prompt压缩类似,各位可看看,《TokenSkip: Controllable Chain-of-Thought Compression in LLMs》 ,https://arxiv.org/pdf/2502.12067,
发现,其实并不是所有的token都对推理结果有同等贡献。有些token是“划水”的,完全可以跳过,于是,提出了一个叫TokenSkip方法,让大模型在推理时能够自动跳过那些不重要的token,思维链中的token并不是平等的。
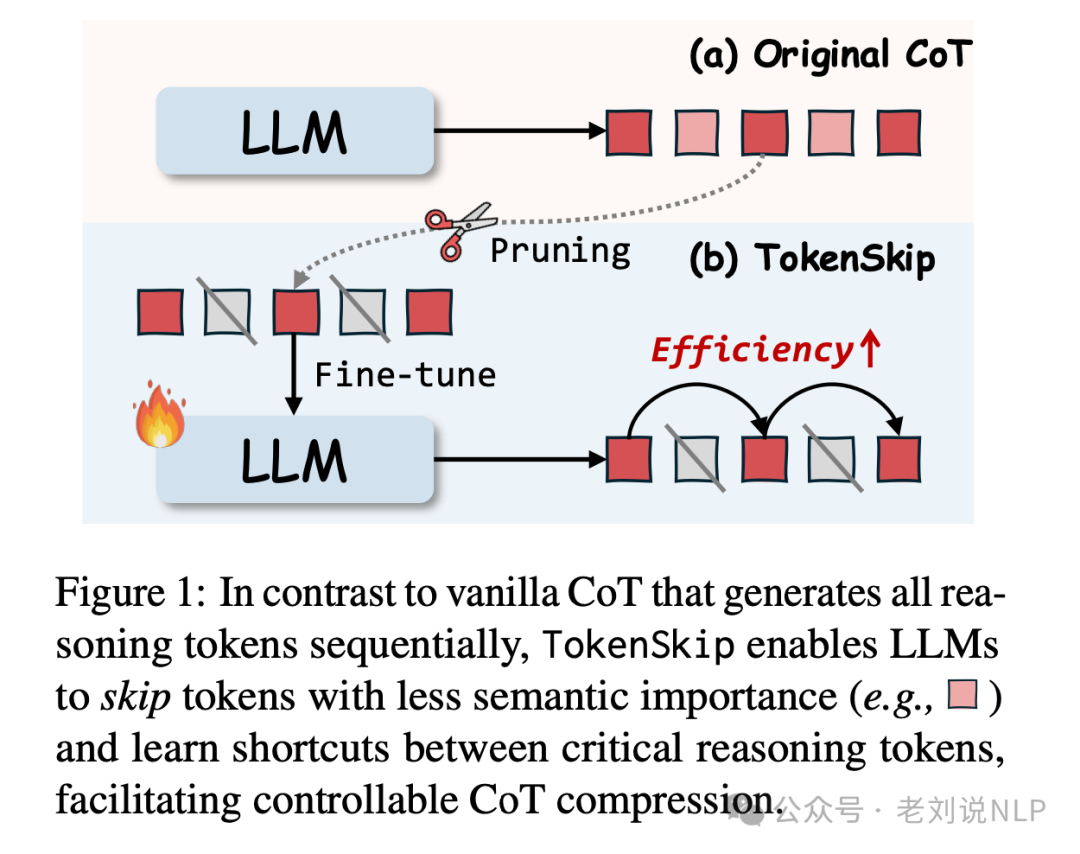
有些token对推理结果至关重要,比如数学公式和关键数字;而有些token则相对“划水”,比如一些连接词(如“所以”、“因为”)。基于这个发现,TokenSkip的核心思想就是:让大模型学会跳过那些不重要的token,只保留关键的推理步骤。
具体,TokenSkip的实现分为三个步骤:token修剪、训练和推理。
Token修剪阶段,也就是Token重要性分析和剪枝: 通过分析CoT输出中每个token的语义重要性,发现其对推理性能的贡献不同。使用LLMLingua-2作为token重要性度量标准;
随后,根据token的重要性值对CoT输出进行剪枝,保留重要性较高的token。具体步骤包括计算每个token的重要性值,按重要性排序,并设定一个阈值来剪枝不重要的token。

训练阶段,用修剪后的思维链数据对大模型进行微调,使目标LLM能够在推理过程中自动跳过冗余的token
为了让大模型学会在不同的压缩比例下工作,训练数据中会包含不同压缩比例的思维链。这样一来,大模型就能学会在不同的压缩比例下进行推理。

在推理阶段,让大模型根据设定的压缩比例,自动跳过那些不重要的token,生成压缩后的思维链。

看具体的结论,这个工作其实目的是为了加速,不是为了提升准确性,所以真实落地的时候,其实用不了。
采用LoRA方法进行模型微调,训练时间为2小时(7B模型)和2.5小时(14B模型)后,**在LLaMA-3.1-8B-Instruct模型上,减少了30%的CoT token使用,性能下降不到4%,推理速度提高了1.4倍;在Qwen2.5-14B-Instruct模型上,在GSM8K数据集上减少了40%的推理token(从313减少到181),性能下降不到0.4%。在0.5的压缩比下,性能仅下降2%**,推理速度提高了1.8倍。
所以,依旧有很多问题。COT过程的token还是要生成,这部分token并没有省;引入了一个模型来作为token的重要度评估,特别是在cot比较长时,这一块性能如何保证;重要度评估方法模型是否需要针对不同的领域进行训练。
参考文献
1、https://arxiv.org/pdf/2502.12067
(文:老刘说NLP)