


邮箱|zhouyixiao@pingwest.com
DeepSeek开源周第四天来了,一次性放出开源三个项目。
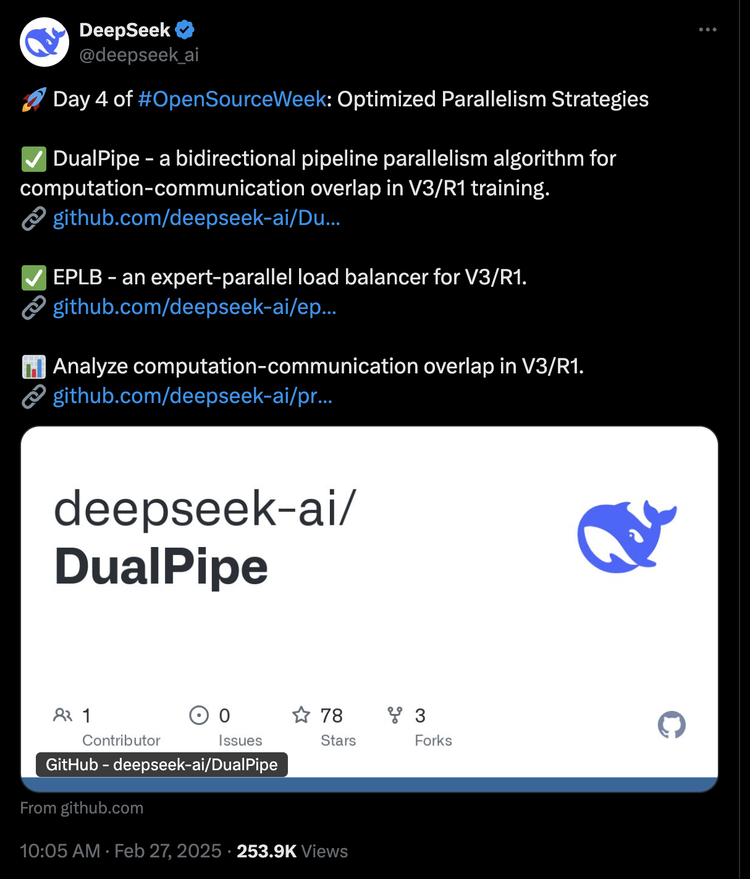
DualPipe:一种双向管道并行算法,用于 V3/R1 训练中的计算通信重叠。
亮点:双向数据流设计减少流水线空闲时间,提升GPU利用率
EPLB:适用于 V3/R1 的专家并行负载均衡器。
亮点:智能流量调度,确保混合专家模型中计算负载均匀分布,降低通信开销
Profile-data:分析 V3/R1 中的计算通信重叠。
亮点:用于分析 DeepSeek V3 和 R1 模型训练中的计算与通信重叠,帮助优化训练效率。
这三个开源项目重点都放在优化的并行策略。通过并行策略,最大化计算资源的利用效率,从而加快模型训练的速度,降低计算成本。
#01
首先是DualPipe,这是DeepSeek-V3里首次亮相的双向流水线并行算法,现在代码开源了。

在V3的论文中是这样描述的:我们设计了DualPipe算法以实现高效的流水线并行,该算法减少了流水线中的空泡,并通过计算与通信的重叠隐藏了训练期间的大部分通信。
这种重叠确保了,随着模型进一步扩大规模,只要我们保持计算与通信的比例不变,我们就能在节点间继续使用细粒度的专家,同时实现近乎为零的all-to-all通信开销。
简单来讲,它把前向和后向计算 – 通信阶段完全重叠起来,还减少了“流水线气泡”。
设想你正在多块GPU上训练一个大模型。你把模型分割成若干部分,每块GPU负责其中一块。听起来不错,然而,并非总是如此。传统的流水线并行常常留下间隙——称为“气泡”——某些 GPU 在此期间无所事事,只是等待其他GPU赶上来,这就浪费了时间和资源。

通过DualPipe这种双向流水线并行算法,可以不再让通信瓶颈拖慢进程,而是通过重叠计算与通信阶段来提升效率。当一个 GPU 忙于处理数据时,另一个则负责传输信息。如此一来,所有设备都保持高效运转,大幅减少了闲置时间,从而整体加速了流程。

更精彩的是DualPipe 在跨节点通信中表现出色。在多台机器(节点)上进行训练时,相互通信可能会成为瓶颈。DualPipe通过在计算过程中并行运行通信,而不是在其后进行,从而解决了这一问题。对于DeepSeek-V3或R1等需要大量数据交换的MoE模型,这是一个改变游戏规则的创新。这也是今天的三个项目中,Github星标涨得最快的,也是梁文峰本人参与开发的项目。
#02
再看EPLB,全称Expert Parallelism Load Balancer,是一种工具,专门用于AI模型中专家并行的负载平衡。专家并行是一种技术,特别是在混合专家(MoE)层中,不同的“专家”(小型模型)处理不同的输入数据。EPLB确保这些专家的计算任务在多个GPU之间均匀分配,避免某些GPU过载而其他GPU闲置。

简单来说,EPLB像一个“任务分配器”,确保AI模型的计算任务不会集中在某些GPU上,而是均匀分布,防止效率低下。如果某个专家处理的任务特别多,EPLB会复制这个专家,并将其分配到其他GPU上,这样计算任务就能更均匀地分布。
另外,它还会尽量把同一组的专家放在同一个节点上,减少节点之间的数据传输,从而降低通信成本。这对大规模GPU集群特别有用,能让模型训练和运行更高效。
#03
Profiling Data是训练和推理框架的性能分析数据,用PyTorch Profiler捕获,能清晰展示通信 – 计算重叠策略和底层实现细节。展示其模型在不同训练配置下的效率,下载后在浏览器特定页面就能可视化,训练和推理阶段的数据都有,对开发者深入研究和优化有帮助。
根据profile-data GitHub,它展示了 DualPipe 策略如何在正向和反向块中重叠计算和通信,例如在 EP64、TP1 和 4K 序列长度下。它还包括前填充和解码阶段的分析,分别使用 EP32 和 EP128 的配置。

简单来说,Profiling Data像DeepSeek AI实验室的实验笔记,帮助看清楚在训练大型AI模型时,不同配置对训练过程的影响,尤其是使用DualPipe方法时。
#04
DeepSeek的开源开源周来到第四天,聚焦在大模型Infra层,每天都有不同的看点,有FlashMLA在Hopper GPU上的加速解码,DeepEP简化MoE模型的通信流程,而DeepGEMM则优化了矩阵运算。今天则是DualPipe和EPLB的加入,通过直接应对并行性问题,来完善DeepSeek工具集。
一位算法工程师告诉硅星人,DeepSeek开源周的每个工具都是小模块的组成部分,“整合起来才是Deepseek的infra系统优化”。也就是说,这些开源项目不是一堆凑在一起的工具——而是一整套较为完整的方法和策略,目的就是能让AI训练和推理的各个环节都发挥最大效能。
我们也很直观看到了DeepSeek将这样的创新投入实际应用所带来的成效:2月25日,DeepSeek重新开放了暂停许久的API充值。2月26日,DeepSeek宣布推出错峰优惠活动,在非高峰时API调用价格大幅下调:DeepSeek-V3降至原价的50%,DeepSeek-R1降至25%。
现在就等着最后一天的压轴大招了。

(文:硅星GenAI)