
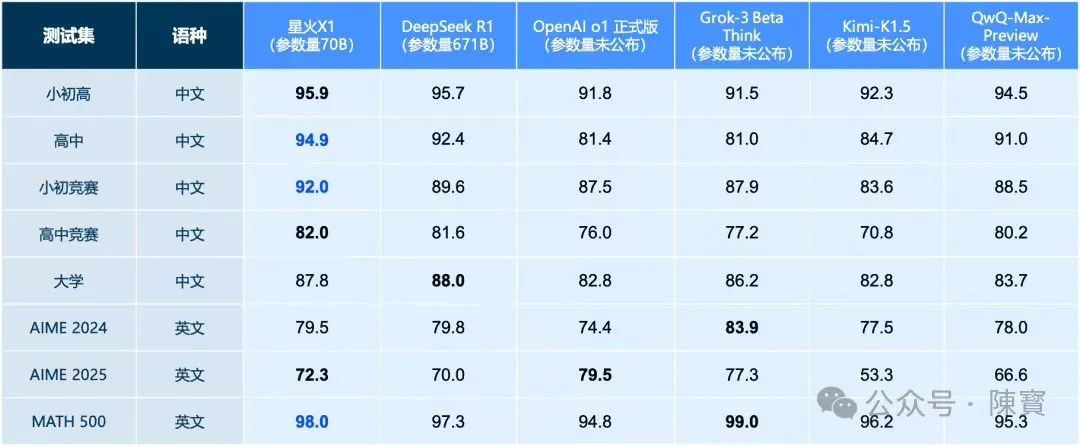
星火大模型,算是国产AI大模型中上线比较早的了,在市场的表现上也是稳扎稳打。刚刚,科大讯飞公司对深度推理大模型星火X1完成全面升级,并以70B参数量的“轻量级”姿态,在数学能力上实现对DeepSeek R1(671B参数)和OpenAI o1的全面对标,甚至在中文数学任务中取得领先优势。
这次的突破不仅标志着国产大模型技术从“跟跑”转向“并跑”,更揭示了AI技术发展的新路径。个人觉得它的优势在于以算法优化和垂直场景深度融合为核心,而非单纯依赖参数堆砌。
参数竞赛升级为效能突破
星火X1仅凭70B参数量,便在数学推理任务中超越参数量近10倍的DeepSeek R1,背后是科大讯飞在算法效率与数据挖掘技术上的创新。
通过“长思维链激发与推理验证”技术,模型能够将复杂问题拆解为多步逻辑链条,并通过自我反思优化答案质量。
解答竞赛级数学题时,星火X1不仅能输出答案,还能分步展示推导过程,甚至标注易错点。该能力源于对教学场景中“错题本”逻辑的模拟,而非单纯依赖海量数据训练。
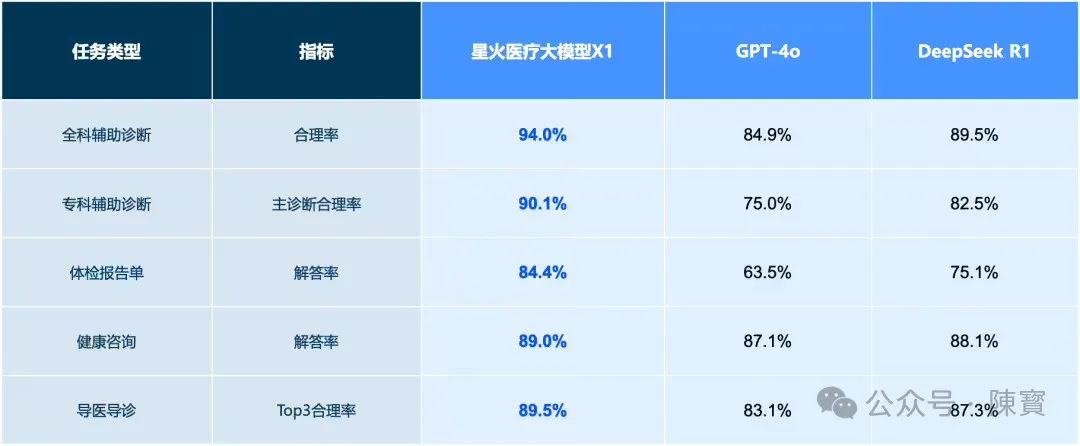
医疗大模型X1的推出,直击行业痛点,也就是AI的“幻觉问题”。通过融合亿级医学知识库与循证推理技术,X1在诊断推荐、报告解读等任务中,效果超越GPT-4o和DeepSeek R1。
用户咨询用药建议时,系统不仅依据疾病指南,还能结合个人健康档案中的过敏史、既往用药记录,生成个性化的用药方案。
“知识+推理+个性化”的三重架构,为AI在专业领域的可信度树立了新标杆。
通用智能到垂直深耕
星火教师助手的升级,展现了AI如何从“工具”进化为“教学伙伴”。
传统AI生成的教学设计多为线性流程,而新版助手能基于教师意图,识别教学重难点,并通过“思维链显性化”技术,将AI的思考过程实时投影至课堂屏幕。数学课上,系统可动态展示几何证明题的多种解法路径,引导学生进行探究式学习。
“透明化AI”的设计,既解决了教师对AI“黑箱”的信任问题,又推动了教学从“知识传授”向“思维培养”的转型。
AI法官助理的升级,标志着大模型开始深入司法核心流程。
通过将法律法规、司法解释与深度推理技术结合,系统能在证据审查、量刑建议等环节中,自动生成附有法理依据的裁判观点,并可视化呈现比对过程。
劳动争议案件中,AI 能够快速匹配相似判例,并分析不同判决结果的法律依据,辅助法官规避知识盲区。它在政务场景中同样关键,政务一体机支持材料智能审查,将政策条文与申报材料自动匹配,大幅降低人工审核成本。
替代进口进阶生态引领
星火X1 具有独特价值,因为它是完全基于国产算力(如华为910B芯片)训练与推理完成的。
相比国际主流平台,国产算力在单卡性能、集群效率上仍有差距,但讯飞通过算法优化与硬件适配的“双轮驱动”,实现了“1万张国产卡等效10万张进口卡”的效能突破。
“以软补硬”的策略,不仅降低了对进口硬件的依赖,更推动了国产算力生态的成熟。
华为与讯飞联合推出的星火一体机,支持双引擎(讯飞+DeepSeek)运行,行业知识能力提升30%,幻觉率下降10%。
DeepSeek引发美国对华算力管控升级的背景下,星火X1的国产化路径具有战略意义。
根据第三方数据,2024年科大讯飞在大模型招投标中以8.47亿元中标额居首,覆盖金融、能源、政务等关键领域。
正如刘庆峰所言:“这一步非走不可,除非你不想自立自强。”
我认为,“技术+场景”的双重壁垒,使得国产大模型不再是实验室中的技术Demo,而是真正成为支撑国民经济的安全基座。
(一)当然也有不足的地方,星火X1在垂直场景的高效,是以通用任务能力的局限为代价。
(二)它在数学能力虽强,但在多模态生成、跨领域推理上仍落后于GPT-4o。
(三)当前国产芯片的制程与能效比仍受制于国际供应链,若无法突破物理极限,算法优化的边际收益也会递减。

医疗、司法等高风险场景中,AI的“可解释性”与“责任归属”仍需制度配套。
若AI法官助理的裁判建议出错,责任应由开发者还是使用者承担?
⋯ ⋯
求变才能更好地突破,星火X1的升级,揭示了一条差异化竞争路径:在算力受限的条件下,通过算法创新与场景深耕,实现“低耗高能”的突破。
东方哲学往往具有更深远的考量,该策略不仅适用于AI领域,也为中国科技产业的全局突围提供了范本。
与其在西方主导的赛道中“硬碰硬”,不如在垂直领域构建“护城河”,以应用反哺技术,以生态定义标准。
(文:陳寳)