


©PaperWeekly 原创 · 作者 | 张彧
随着学术会议论文提交数量的迅速增加,我们越来越依赖有效的论文-评审人匹配模型。此前在这一领域的研究考虑了多种因素来评估评审人与论文之间的相关性,例如论文与评审人过往工作之间的语义相似性、主题相似性以及引用关系。然而,大多数研究仅专注于单一因素,导致对论文-评审人相关性的评估不够全面。
为了解决这一问题,我们提出了一种统一的匹配模型,该模型综合考虑了语义、主题和引用三大因素。具体而言,在训练阶段,我们对一个所有因素共享的语言模型进行指令微调,以捕捉这些因素的共性和特性;在推理阶段,我们将三种因素串联起来,实现逐步、从粗到精的搜索,为给定的论文找到合适的评审人。

论文题目:
Chain-of-Factors Paper-Reviewer Matching
https://arxiv.org/abs/2310.14483

论文-审稿人匹配作为一个文本挖掘任务已被广泛研究,其目标是根据投稿论文的文本(如标题和摘要)以及审稿人此前发表的论文,评估该审稿人对该投稿论文的审稿资质。
从直观上看,如下图所示,相关研究主要考虑三个重要因素:
1. 语义(semantic):将投稿论文 𝑝 视为查询,如果与该查询在语义上最相关的论文由审稿人 𝑟 撰写,则 𝑟 应被认为有资格审稿 𝑝。这一直觉被先前方法如 Toronto Paper Matching System(TPMS)所采用,其中使用 tf-idf 来计算语义相关性。
2. 主题(topic):如果审稿人 𝑟 之前发表的论文与投稿论文 𝑝 共享许多细粒度研究主题,那么 𝑟 被认为是 𝑝 的专家审稿人。这一假设被一些主题建模方法利用。
3. 引用(citation):投稿论文 𝑝 所引用论文的作者更有可能是 𝑝 的专家审稿人。一些科学领域的语言模型(如 SPECTER 2.0)采用了论文的引用信息进行模型预训练,并在论文-审稿人匹配任务上获得了准确率的提升。
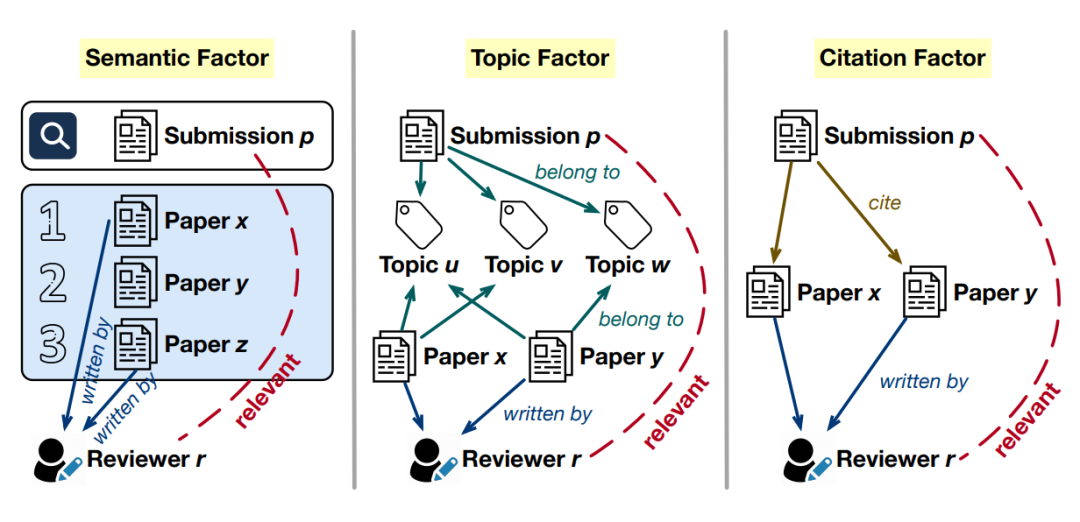
尽管先前研究探讨了各种因素,但我们发现大多数方法在实践中通常只考虑其中一个因素。直观上看,语义、主题和引用这三者之间是相互关联的,但无法完全替代彼此。因此,仅考虑其中任何一个因素都会导致对论文与审稿人相关性的评估不够全面。
此外,这些因素之间是互相补充、相辅相成的。例如,理解一篇论文引用另一篇论文的意图,有助于评估它们之间的语义和主题相关性。因此,可以预期一个联合学习这三种因素的模型将在每个单独因素上的表现更加准确。进一步而言,这三个因素应该以逐步推进、由粗到细的方式进行考虑。
具体来说,语义相关性是最粗粒度的信号,可用于筛选完全不相关的审稿人;在考察语义因素之后,我们可以将每篇投稿论文和每位相关审稿人分类到细粒度的主题空间,并检查他们是否在相同的研究领域中。

本文提出了一个因素链(Chain-of-Factors)框架,将语义、主题和引用这三个因素统一到一个模型中,用于论文-审稿人匹配。这里的“统一”包含两个方面:1)预训练一个联合考虑三种因素的模型,从而提升每个因素的表现;2)在推理阶段,将三种因素串联起来,支持逐步推进、由粗到细的专家审稿人搜索。
为了实现这一目标,我们从多个来源收集不同因素的预训练数据,用于训练一个论文编码器。该编码器在所有因素中共享,以学习通用知识。同时,考虑到每个因素的独特性以及指令微调在多任务预训练中的成功应用,我们引入了针对各因素的专属指令,以引导编码过程,从而获得具备因素感知能力的论文表示(如下图所示)。

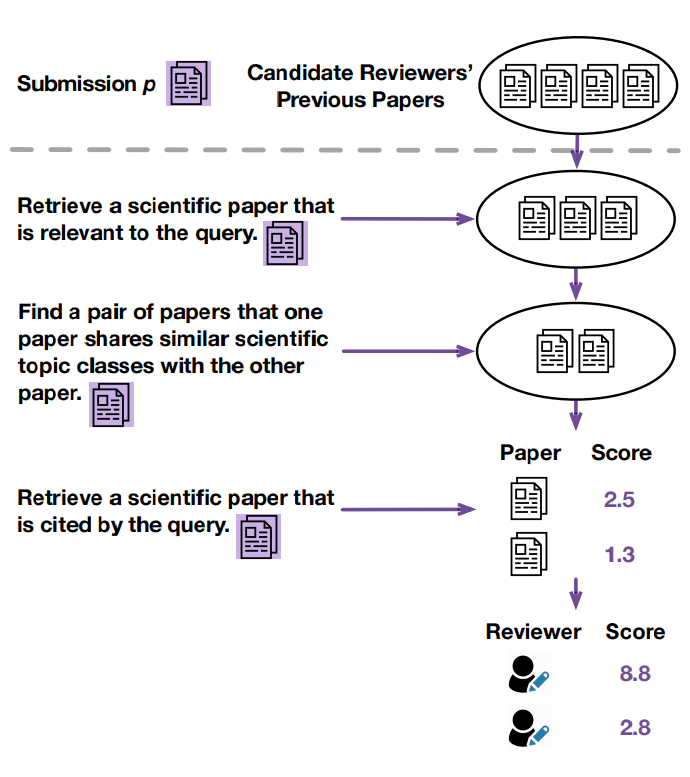

我们在四个不同领域的数据集上进行了实验,其中第四个数据集由我们新标注,规模比前三个更大,并包含更多最新发表的论文(链接在我们的GitHub README中:https://github.com/yuzhimanhua/CoF)。
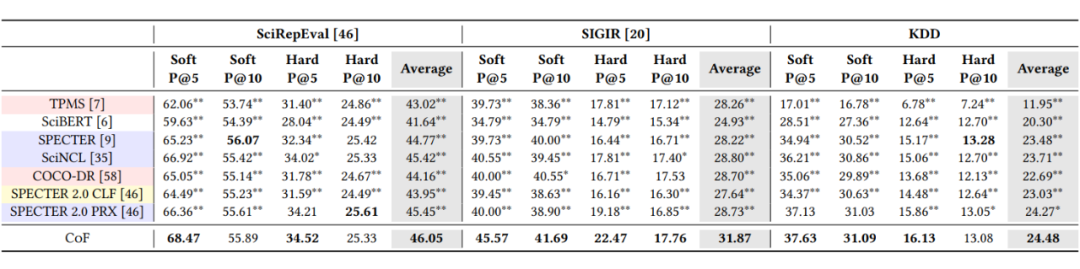
实验结果表明,我们提出的因素链模型在四个数据集上均稳定优于以往的论文-审稿人匹配方法和预训练语言模型。进一步的消融实验验证了 CoF 模型有效的三个原因:
2. CoF 将这三种因素以链式方式串联,实现了逐步筛选相关审稿人的过程,而非一次性合并所有因素;
3.2 应该使用审稿人此前发表的哪些论文来进行匹配?
我们是否应将候选审稿人之前撰写的所有论文纳入与投稿论文的匹配,还是应该设定某些标准?在此,我们探讨三种直观标准对模型的影响:
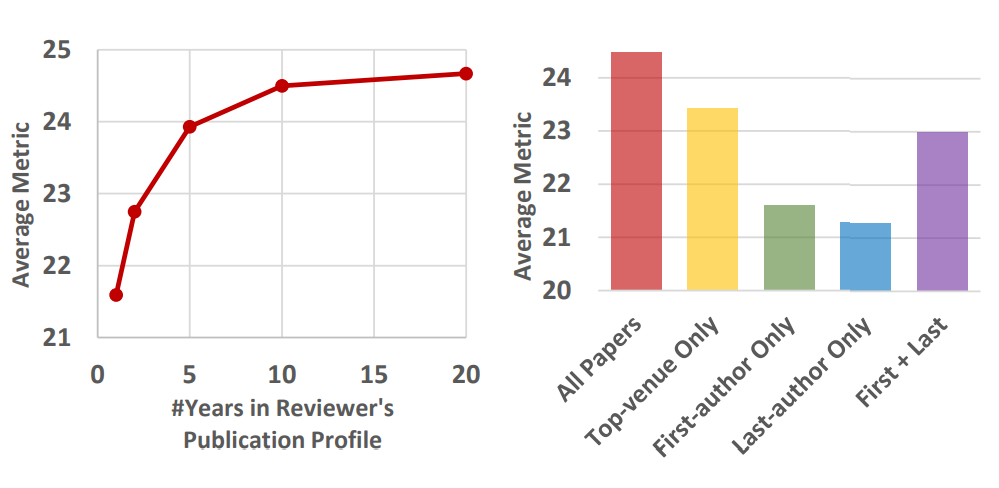
1. 时间跨度:如果仅包含审稿人在最近 𝑌 年内发表的论文会怎样(因为早期论文可能已偏离审稿人当前的研究兴趣)?
例如,在 KDD 2020 会议中,如果 𝑌 = 5,我们只将 2015-2019 年间发表的论文纳入审稿人的发表档案。下图展示了在 𝑌 = 1、2、5、10 和 20 时 CoF 模型的表现。结果表明,纳入更多论文通常是有益的,但在 𝑌 = 10 时性能开始收敛。
2. 发表会议:如果只包含发表在顶级会议上的论文会怎样?
下图对比了使用审稿人所有论文与仅使用“顶会”论文的表现。这里“顶会”指 CSRankings 在 2020 年列出的 75 个会议(包括 KDD)。结果表明,即使是不在顶会发表的论文,对刻画审稿人的专业领域仍有积极贡献。
下图也展示了仅使用审稿人作为一作、尾作论文及两者合并后的模型表现。尽管合并后的表现明显优于单独使用其中之一,但仍明显弱于使用审稿人所有论文的情况。

在这项工作中,我们提出了一个因素链框架,以逐步推进、由粗到细的方式,将语义、主题和引用三种信号联合考虑,用于论文-审稿人匹配。我们设计了一种基于指令引导的论文编码过程,从而学习具备因素感知能力的文本表示,以建模论文与审稿人在不同因素上的相关性。在四个数据集上的实验结果验证了 CoF 框架的有效性。
(文:PaperWeekly)