

极市导读
首次在3D多模态大语言模型中移除了编码器,让LLM直接处理3D编码任务。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文标题: Exploring the Potential of Encoder-free Architectures in 3D LMMs
作者单位:上海人工智能实验室,西北工业大学,香港中文大学,清华大学
代码链接:https://github.com/Ivan-Tang-3D/ENEL
论文链接:https://arxiv.org/pdf/2502.09620v1
在二维视觉领域,无编码器架构已初步得到探索,但它是否能有效应用于3D理解场景仍然是一个未解之谜。本文中,我们首次全面探讨了无编码器架构在克服基于编码器的3D大规模多模态模型(LMMs)挑战方面的潜力。这些挑战包括无法适应不同点云分辨率,以及编码器提取的点特征未能满足大语言模型(LLMs)的语义需求。
我们确定了3D LMM去除编码器并使LLM承担3D编码器角色的关键方面:
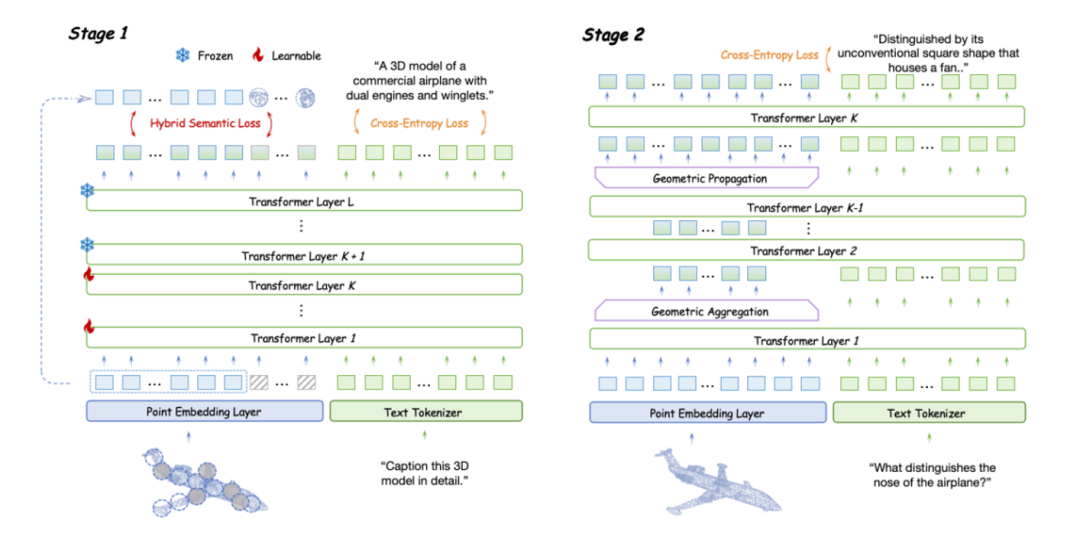
(1) 在预训练阶段,我们提出了LLM嵌入语义编码策略,探索了各种点云自监督损失的效果,并提出了混合语义损失,以提取高层次语义。
(2) 在指令微调阶段,我们引入了分层几何聚合策略,将归纳偏置引入LLM的早期层次,专注于点云的局部细节。
最终,我们提出了首个无编码器的3D LMM,ENEL,其7B模型与当前最先进的ShapeLLM-13B相媲美。
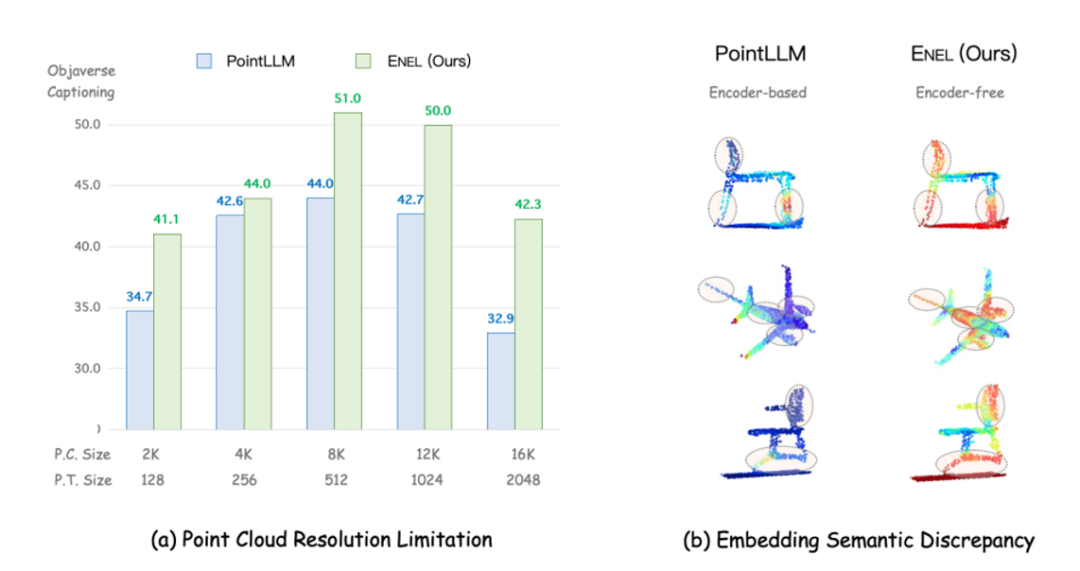
1.出发点
对于3D LMMs,基于编码器的架构存在以下潜在缺点:1. 点云分辨率限制:3D编码器通常是在固定分辨率的点云数据上进行预训练的,例如在 PointLLM 中采用了 1,024 个点。然而,在实际推理时,点云的分辨率可能会有所变化(例如,可能是 8,192 或 512 个点)。训练和推理时分辨率的不一致,可能会导致在提取 3D 嵌入时丢失关键信息,从而使得 LLM 难以有效理解空间结构。如上图(a)所示,我们提出的ENEL相比于PointLLM在不同的点云分辨率输入下具有更强的泛化性和鲁棒性。2. 语义嵌入差异:3D编码器通常采用自监督方法(如Point-MAE)和对比学习(如PointContrast)进行预训练,但这些方法的训练目标往往无法捕捉到 LLM 理解 3D 物体所必需的最相关语义,因此与 LLM 的语义需求存在不匹配。换句话说,如图(b)所示,即便在PointLLM中使用了投影层,文本标记仍难以有效地关注到点云物体的关键区域。而ENEL则能够轻松地将注意力集中在椅脚和机翼等重要部位。鉴于这些问题,我们提出了一个问题:是否有可能探索一种无编码器架构用于3D LMMs,去除3D编码器,并将其功能直接集成到LLM自身中?
2. 具体实现方案
我们选择PointLLM作为基准模型进行探索,并使用GPT-4评分标准在Objaverse数据集上评估不同策略的表现。为了在去除编码器的同时避免性能下降,我们探索了解决以下两个关键问题的方法:
1)如何弥补原本由3D编码器提取的高级3D语义?
在3D LMMs中,原始的点云输入首先通过一个标记嵌入模块进行低级别的标记化处理,然后再传递给主3D编码器(通常是一个Transformer模型)生成高级别的嵌入。完全跳过编码器会带来一个挑战,即无法有效捕捉3D点云的复杂空间结构。为了应对这个问题,我们提出了一种名为LLM嵌入式语义编码的策略,应用于预训练阶段。首先,我们采用一个简单而有效的标记嵌入模块,尽可能多地捕捉信息丰富的语义内容。这些3D标记随后被直接输入到LLM中。接着,我们的目标是将捕捉高级3D语义的任务转交给LLM本身。为此,我们使LLM的早期层可学习,从而使其能够专注于3D编码。为了引导这一过程,我们探索了多种3D自监督损失函数,如重建损失、掩码建模损失和蒸馏损失,并最终提出了混合语义损失,作为最有效的选择。
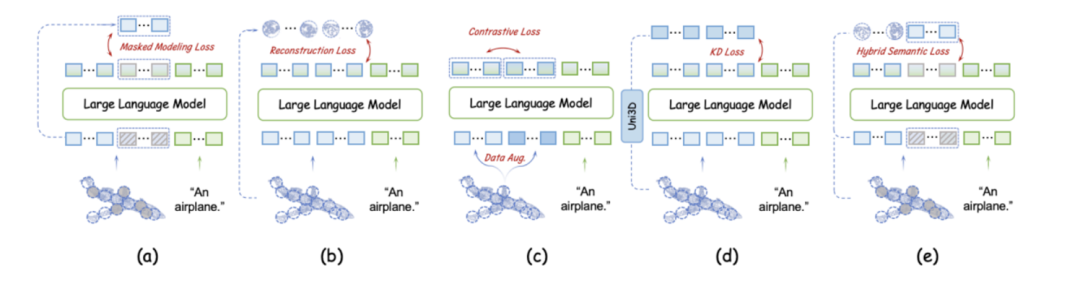
如上图所示:蔽建模损失(a)、重建损失(b)、对比损失(c) 和知识蒸馏损失(d),我们在预训练阶段实现并评估了这些损失对无编码器3D LMM的影响。混合语义损失中,我们首先对点云的标记进行随机掩码处理,然后将掩码标记与可见标记拼接在一起,以符合自回归的逻辑。在此基础上,我们对可见标记计算重建损失。这种混合策略不仅能够高效地将高级语义信息嵌入到LLM中,还能在整个点云学习过程中有效保持几何信息的一致性。
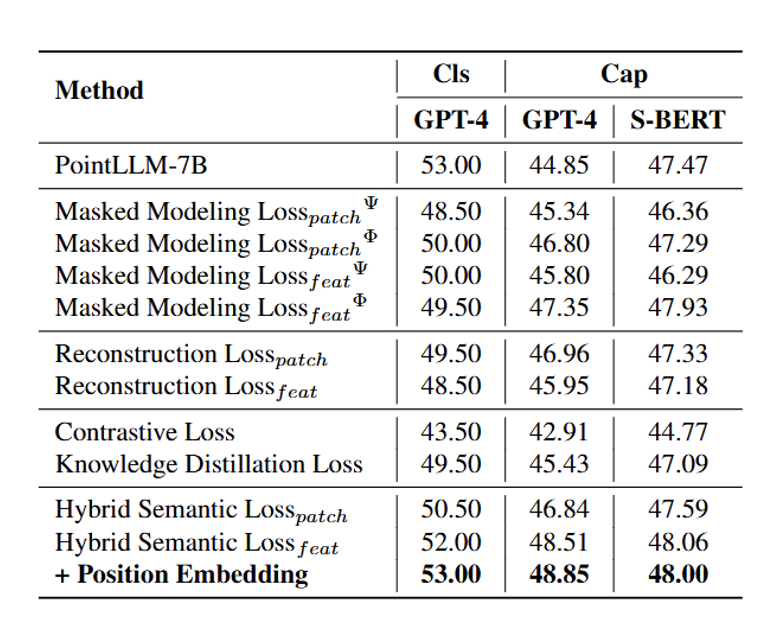
从表中我们可以发现: 1) 点云的自监督学习损失通常对无编码器的3D LMM具有重要帮助。自监督学习损失能够有效地转化复杂的点云数据,促使LLM学习潜在的几何关系以及高层次的语义信息。2) 在所有自监督学习损失中,掩蔽建模损失展现了最显著的性能提升。相比之下,显式的点云patch重建虽然不如掩蔽建模效果好,但依然有助于LLM捕捉点云中的复杂模式。而知识蒸馏损失的效果相对较弱,表现不如前两者。3) 基于上述实验结果,我们提出的混合语义损失(Hybrid Semantic Loss)达到了最好的性能效果。
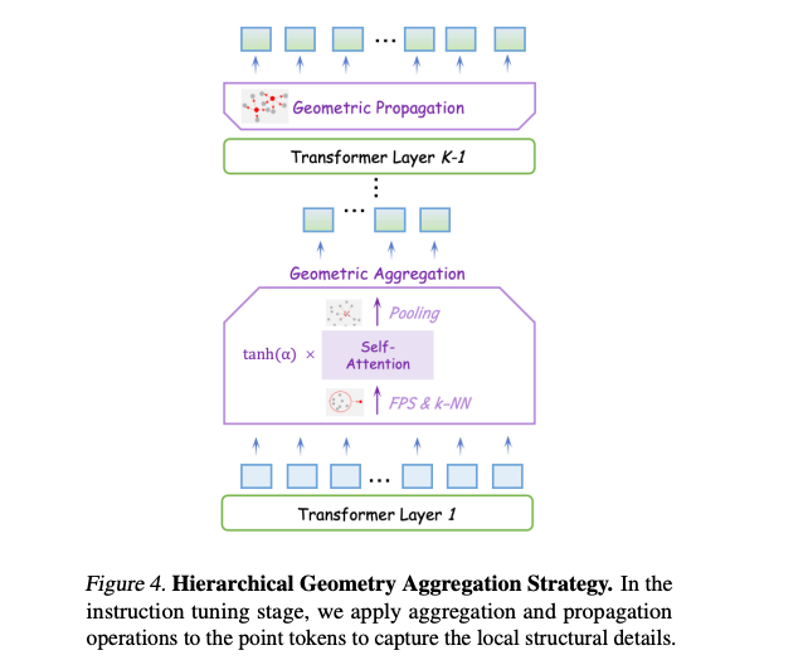
2)如何将归纳偏置融入LLM,以提升其对3D几何结构的感知?
传统的3D编码器通常将显式的归纳偏置嵌入到其架构中,以逐步捕捉多层次的3D几何信息。例如,像 Point-M2AE这样的模型使用了局部到全局的层次结构,这种思想在2D图像处理的卷积层中也十分常见。而与之对比,LLM采用的是标准的Transformer架构,其中每一层处理相同数量的标记,表示网络中相同的语义层次。在缺乏编码器的情况下,我们在指令微调阶段引入了分层几何聚合的方法。在LLM的早期层次,我们基于3D标记的几何分布,通过最远点采样(FPS)和k近邻采样(k-NN)对3D标记进行聚合。这一方法使得LLM能够逐步整合详细的3D语义,并对3D物体形成更加全面的理解。在后续层次,我们反向进行这一聚合过程,将标记传播回其原始分布,以保持必要的细粒度表示,从而确保有效的语义交流。我们发现,这种分层设计有助于多层次知识的获取,并能更好地理解复杂点云的3D几何结构。
3.实验结果
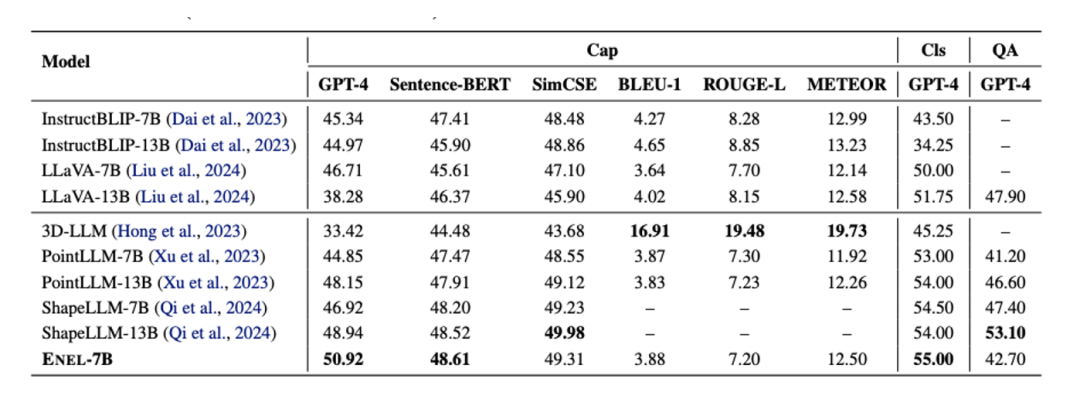
在Objaverse的3D物体描述任务中, ENEL-7B达到了50.92%的GPT-4得分,创下了新的SOTA(最先进)成绩。在传统指标方面,SentenceBERT和SimCSE分别获得了48.61%和49.31%的得分,表现与ShapeLLM-13B相当。在3D物体分类任务中,ENEL-7B超越了之前基于编码器的3D LMMs,取得了55%的GPT得分。此外,在3D MM-Vet数据集的3D-VQA任务上,尽管训练数据中缺乏与空间和具身交互相关的内容,ENEL仍然取得了42.7%的GPT得分,超过了PointLLM-7B的得分1.5%。

我们进行了可视化分析,在模型的最后一层计算了文本平均token与点云token之间的注意力,涵盖了三种物体类别(椅子、飞机和台灯)。结果显示,ENEL在无编码器架构下展现了两种模态特征之间的高度相关性,图中的红色部分表示较高的注意力得分。

(文:极市干货)