
腾讯混元团队发布了他们最新的力作——Hunyuan-TurboS,首个混合Transformer-Mamba MoE架构的超大模型
大家都知道,传统Transformer模型在处理长文本时一直面临挑战,O(N²)的复杂度以及KV-Cache问题让长文本训练和推理效率大打折扣。 而这次,混元-TurboS巧妙地融合了Mamba和Transformer两种架构的优势:
-
• Mamba的高效长序列处理能力 -
• Transformer强大的上下文理解能力
强强联合,效果自然惊艳!
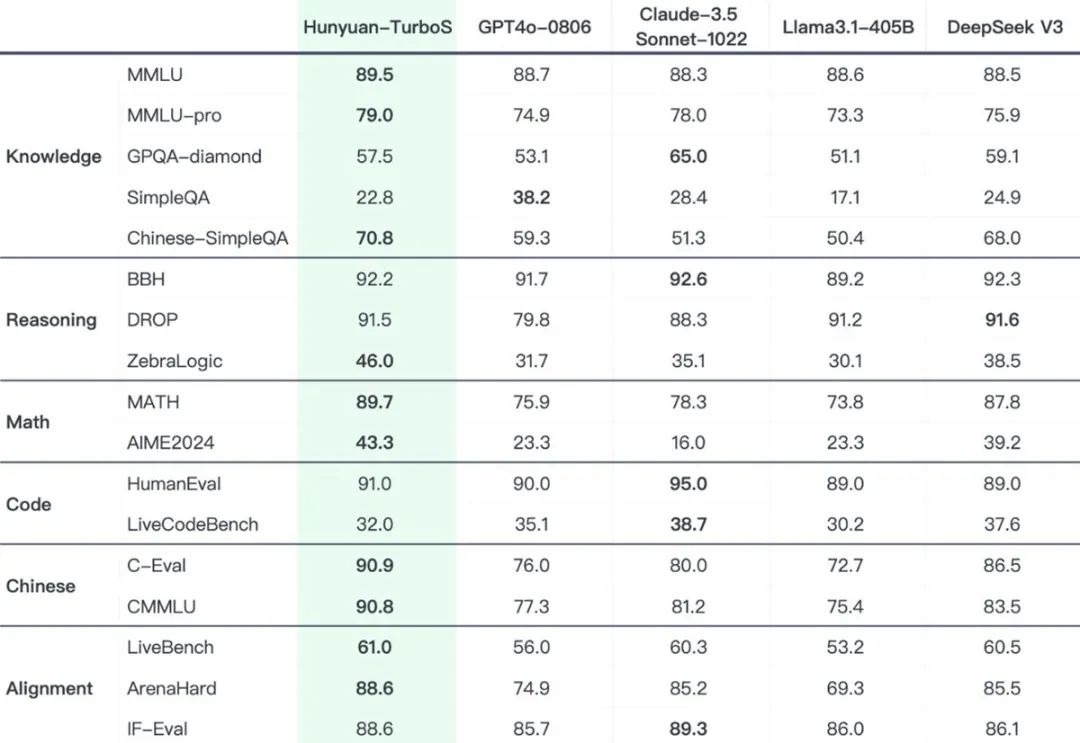
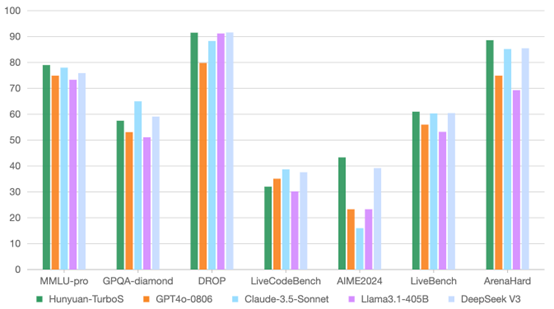
官方数据显示,Hunyuan-TurboS在多个关键benchmark上表现出色:
-
• 数学、推理、对齐能力超越或持平 GPT-4o-0806、DeepSeek-V3 以及各类开源模型。 -
• 知识能力同样突出,在 MMLU-Pro 等专业评测中也具备竞争力 -
Hunyuan-TurboS的推理成本相比之前的Turbo模型降低了整整7倍! 性能提升的同时,成本大幅下降
为了进一步提升模型能力,混元团队还对TurboS进行了多项后训练优化:
-
• 引入慢思考(Slow-thinking)集成,显著提升了模型在数学、编程和推理任务上的表现。 -
• 通过精细化的指令调优,增强了模型的对齐性和Agent执行能力。 -
• 进行了英语训练优化,从而提升模型的通用性能。
除了模型架构和训练优化,混元团队还升级了奖励系统:
-
• 采用基于规则的评分和一致性验证,保证模型输出的质量和可靠性。 -
• 引入代码沙箱反馈,大幅提升模型在STEM领域的准确性。 -
• 使用生成式奖励,优化模型在问答和创意性任务上的表现,并有效减少奖励作弊现象

⭐
(文:AI寒武纪)