


尽管大型语言和推理模型仍然很受欢迎,但企业越来越多地转向使用较小的模型来运行人工智能流程,从而减少能源和成本方面的担忧。
3 月 12 日,谷歌宣布推出了 Gemma 3 开源 AI 模型,这是基于与 Gemini 2.0 模型相同的研究和技术构建。
谷歌在其官方博客中表示,Gemma 3 是一组轻量级的模型,开发者可以在手机、笔记本电脑以及工作站这些设备上直接快速地运行。该模型支持超过 35 种语言,并具备分析文本、图像及短视频的能力。
Gemma 3 有不同的规模可供选择,分别是 10 亿参数(1B)、40 亿参数(4B)、120 亿参数(12B)和 270 亿参数(27B)。开发者可以根据自身设备的硬件条件以及对性能的要求,选择适当的模型。
项目地址:https://ollama.com/library/gemma3
谷歌表示,Gemma 3“以其尺寸提供了最先进的性能”,并且优于 Llama-405B、DeepSeek-V3 和 o3-mini 等领先的 LLM。具体来说,Gemma 3 27B 在 Chatbot Arena Elo 分数测试中排名第二,仅次于 DeepSeek-R1。它超过了 DeepSeek 的较小模型、DeepSeek v3、OpenAI 的 o3-mini、Meta 的 Llama-405B 和 Mistral Large。
具体来讲,Gemma 3 有哪些新功能?谷歌在博客中给出了如下信息:
-
构建全球最佳单加速器模型:Gemma 3 在 LMArena 排行榜的初步人类偏好评估中,表现优于 Llama-405B、DeepSeek-V3 和 o3-mini。这帮助用户创建适合单 GPU 或 TPU 主机的引人入胜的用户体验。
-
支持 140 种语言:构建能够使用客户语言的应用。Gemma 3 提供超过 35 种语言的开箱即用支持,并对 140 多种语言提供预训练支持。
-
创建具备高级文本和视觉推理能力的 AI:轻松构建能够分析图像、文本和短视频的应用程序,为交互式和智能化应用开辟新的可能性。
-
通过扩展的上下文窗口处理复杂任务:Gemma 3 提供 128k token 的上下文窗口(相比之下, Gemma 2 的上下文窗口只有 80K),让应用程序能够处理和理解大量信息。
-
使用函数调用创建 AI 驱动的工作流:Gemma 3 支持函数调用和结构化输出,帮助用户自动化任务并构建代理式体验。
-
通过量化模型实现更快的高性能:Gemma 3 引入了官方量化版本,在保持高精度的同时减少模型大小和计算需求。
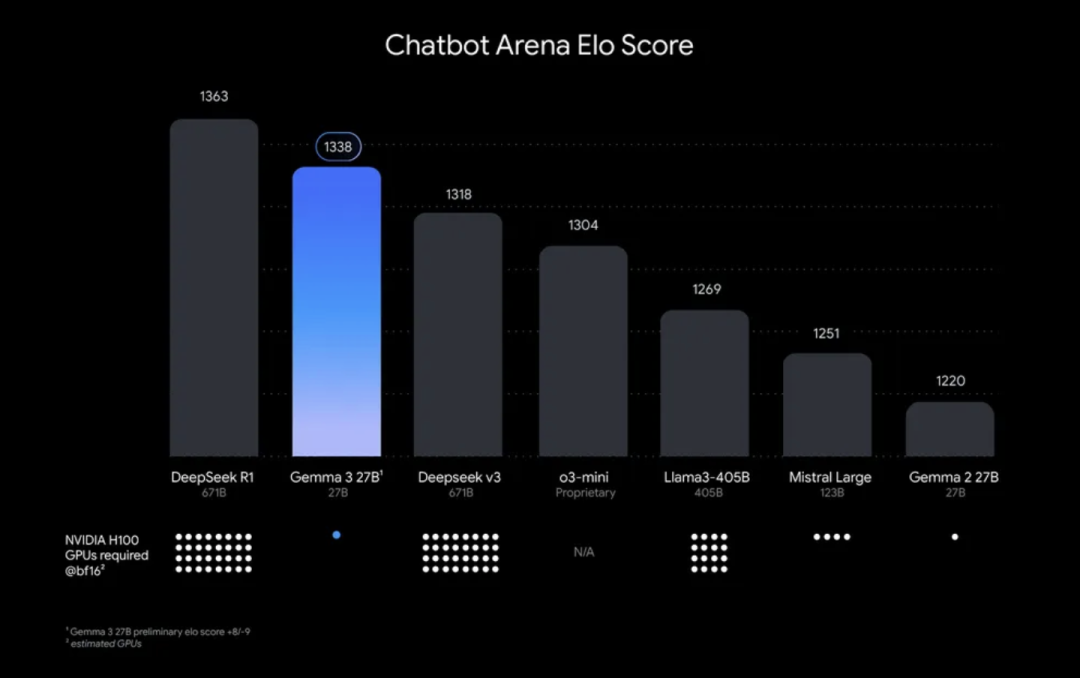
该图表根据 Chatbot Arena Elo 分数对 AI 模型进行排名;分数越高(顶部数字)表示用户偏好越高。圆点表示预估的 NVIDIA H100 GPU 需求。Gemma 3 27B 排名靠前,尽管其他模型需要多达 32 个 GPU,但它仅需单个 GPU 即可运行。
谷歌声称,Gemma 3 是“世界上最好的单加速器模型”,在配备单个 GPU 的主机上的性能表现超越了 Facebook 的 Llama、DeepSeek 和 OpenAI 等竞争对手。具体来说,Gemma 3 27B 在 Chatbot Arena Elo 分数测试中排名第二,仅次于 DeepSeek-R1。它超过了 DeepSeek 的较小模型、DeepSeek v3、OpenAI 的 o3-mini、Meta 的 Llama-405B 和 Mistral Large。
同时,该模型针对英伟达的 GPU 和专用人工智能硬件进行了优化。谷歌还发布了一份长达 26 页的技术报告,深入阐述了这些性能优势。
论文地址:https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf
Gemma 3 与 Hugging Face Transformers、Ollama、JAX、Keras、PyTorch 等开发者工具集成。用户还可以通过 Google AI Studio、Hugging Face 或 Kaggle 访问 Gemma 3。公司和开发者可以通过 AI Studio 请求访问 Gemma 3 API。
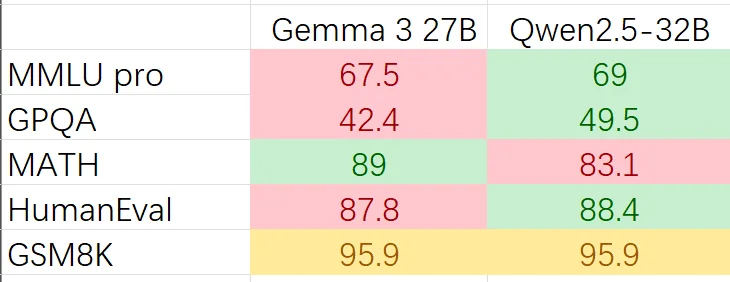
有网友对 Gemma 3 和 Qwen 2.5 进行了基准测试比较,两者在分数上没有拉开太大差距,有网友表示,“这是可以接受的,较小的模型具有大致相同的功能。”据谷歌报告得分高于Qwen2.5Max。

Gemma 3 在架构上主要进行了两方面改进:下文长度扩展和预训练优化。
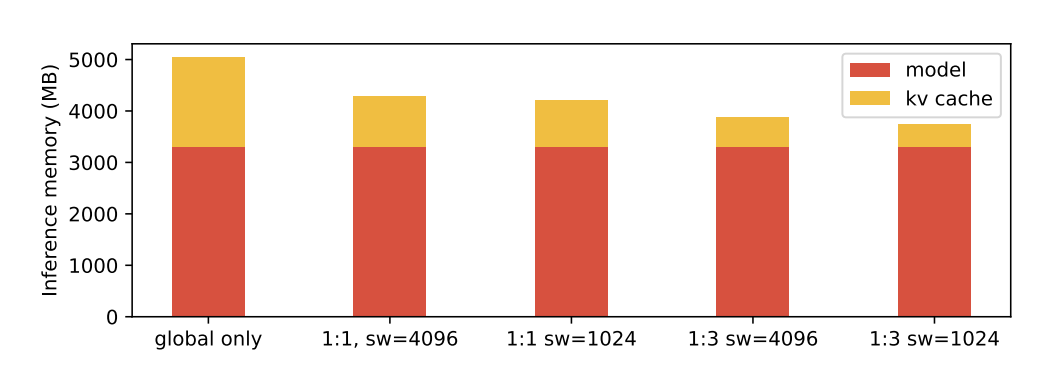
长上下文的挑战在于推理过程中 KV 缓存(KV-cache) 内存的爆炸式增长。为缓解这一问题,谷歌采用了 5:1 的局部 / 全局层交错机制,即每 5 层局部层后接 1 层全局层,并以局部层作为模型的第一层开始计算。
Gemma 3 通过增加“局部注意力层(local attention layers)”相较于全局注意力层(global attention layers)的比例,并缩短局部注意力的跨度(仅 1024 个 tokens),减少了长上下文时 KV 缓存爆炸问题。
当前,Gemma 3 支持最长 128K tokens 的上下文长度,但 1B 参数模型的上下文长度为 32K tokens。为此,Gemma 3 将全局自注意力层的 RoPE(旋转位置编码)基频 从 10K 提升至 1M,而局部层的基频保持在 10K。
预训练方面,Gemma 3 采用与 Gemini 2.0 相同的 SentencePiece 分词器,词汇表规模为 262K,并针对非英语语言进行了平衡优化。
另外,Gemma 3 重新设计了数据混合策略,以提升模型的多语言能力,并融入图像理解能力。
相比 Gemma 2,Gemma 3 增加了训练 token 量,以容纳图像和文本的混合数据:Gemma 3 27B 使用 14 万亿 tokens 进行预训练;12B 模型使用 12 万亿 tokens;4B 模型使用 4 万亿 tokens;1B 模型使用 2 万亿 tokens。此外,Gemma 3 还大幅增加了多语言数据,包括单语数据和平行语料。
蒸馏机制方面,每个 token 采样 256 个 logits,并按教师模型的分布进行加权,学生模型通过交叉熵损失函数学习教师模型样本上的分布。教师模型的目标分布中,未被采样的 logits 概率被设为零,并重新归一化。这种高效的蒸馏过程确保了学生模型能够准确学习教师模型的输出分布,同时控制计算成本。
视觉模态方面,Gemma 3 使用 SigLIP 作为图像编码器,将图像编码成可由语言模型处理的 token。该视觉编码器的输入调整为 896×896 的矢量图像。固定输入分辨率处理使得非长宽比和高精度图像变得更加困难。为解决推理过程中的这些限制,图像可以先进行适应性裁剪,然后将每个裁剪区域调整为 896×896 尺寸,再由图像编码器进行编码。该算法被称为“平移扫描”,它能有效帮助模型聚焦图像中的更小细节。
Gemma 3 中的注意力机制对于文本和图像输入的处理方式不同。文本使用单向注意力,而图像则采用全局注意力,没有遮蔽(mask),允许模型以双向方式查看图像的每个部分,从而对视觉输入进行完整且没有任何限制的理解。

谷歌表示,当前的 Gemma 3 27B 已经处于帕累托最优点。
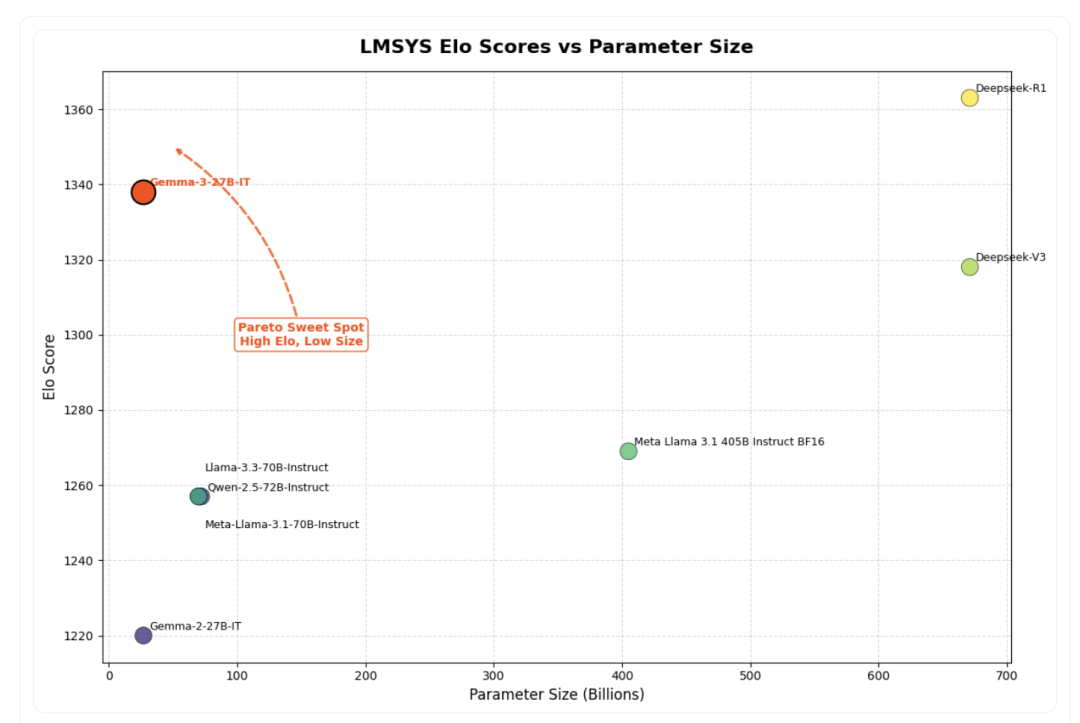
Gemma 3 发布后,迅速在 Hacker News 和 Reddit 等平台上引发热议。有的网友看到 Gemma 3 27B 模型在 LLM Arena 上的得分不淡定了,认为 27B 模型就能击败 Claude 3.7 Sonnet 让人难以置信:
“据谷歌博客,Gemma 3 27B 在 LLM Arena 上的 ELO 为 1338?27B 模型得分高于 Claude 3.7 Sonnet?太疯狂了。”
有开发者对谷歌的技术创新表示感谢:
“感谢谷歌,我真的很感激。这真是太棒了!作为一名开发人员和产品所有者,我非常愿意每周花 6 天时间从事这样的项目。与 Gemini 相比,从我的角度来看,这些模型是支持 Gemini 的 MoE(混合专家)的基础模型——也就是说,它们是专家模型的基础(通过微调实现)。”
该开发者还强调了谷歌需要把这些模型发布出来的原因在于:
“第一,谷歌自身需求:谷歌需要这些模型来支持其内部的技术开发和实验;第二,社区评审:通过开放这些模型,谷歌可以让社区(开发者、研究人员等)参与评审和改进,从而提升模型的质量和可靠性。第三:客户安全:这些模型可以帮助客户在安全的环境中使用 AI 技术,例如通过微调模型来适应私有数据集,而不必直接依赖谷歌的云端服务。 因为可以使用这些模型,基于自己的私人数据集对 Gemini 的性能进行微调。”
在 Hacker News 平台,有用户称自己在家里经常使用 Gemma 2,因为它仍然表现良好。
“9B 版本在我的 2080Ti 上运行得非常流畅。它的强大性能和整体能力使其非常实用。我期待尝试 Gemma 3。不过,我有一些可能比较基础的问题,想请教一下:你们是如何决定模型大小的?这些模型是如何训练的?是独立训练的,还是它们之间存在某种关联?”
该用户的提问得到了谷歌 Gemma 团队成员 alekandreev(Hacker News 用户 ID)的回复。alekandreev 表示:
选择模型大小并不是一门精确的科学。我们主要根据不同的设备类别(例如低端和高端智能手机、笔记本电脑、16GB GPU 以及更大的 GPU/TPU)来确定合适的模型尺寸。此外,我们希望模型的宽度与深度(层数)的比例始终保持在 90 左右,因为我们发现这是最佳的比例。 这些模型是通过从更大的教师模型中提炼(蒸馏)来训练的。对于 Gemma 3,我们独立训练了不同规模的模型,但在 v3 中,我们统一了 4B 到 27B 的训练配方。这样做的目的是在扩大或缩小模型规模时,为您提供更一致的性能和可预测性。
InfoQ 还留意到,alekandreev 在发布 Gemma 3 时,还甩出了一则招聘启事,在招聘启事中,Gemma 团队强调应聘者需要具备的技能和经验包括:构建和维护大型软件系统、分布式系统、具有 Python 和静态类型编程语言的经验(Gemma 主要使用 Python 编程)、编写设计文档和代码审查、愿意适应研究环境等。

招聘地址:https://boards.greenhouse.io/deepmind/jobs/6590957
自谷歌于 2024 年 2 月首次发布 Gemma 以来,外界对小型语言模型的兴趣与日俱增。其他小型模型(如微软的 Phi-4 和 Mistral Small 3)的出现表明,企业希望使用与大语言模型一样强大的模型构建应用程序,但不一定能充分利用大语言模型的全部功能。
与传统的大模型相比,小模型在特定任务中表现出色,尤其是在资源有限的环境中。企业开始意识到,并非所有应用场景都需要大语言模型的全部功能。例如,在简单的代码编辑器或特定领域的任务中,较小的模型(无论是 SLM 还是通过蒸馏工艺精简的版本)可以更高效地完成任务,而不会造成资源浪费或过度拟合。
蒸馏工艺作为一种将大型模型的知识转移到小型模型的技术,正逐渐成为企业优化 AI 部署的重要手段。通过蒸馏,企业可以创建更小、更高效的模型版本,同时保留原始模型的性能。然而,值得注意的是,Gemma 并非 Gemini 2.0 的蒸馏版本。Gemma 是基于相同的数据集和架构独立训练的,而不是从更大的模型中学习。
组织通常更喜欢将某些用例拟合到模型中。与将 o3-mini 或 Claude 3.7 Sonnet 等 LLM 部署到简单的代码编辑器相比,较小的模型(无论是 SLM 还是精简版)都可以轻松完成这些任务,而不会过度拟合大型模型。
声明:本文为 AI前线整理,不代表平台观点,未经许可禁止转载。
(文:AI前线)